适用对象:
![]() NoSQL
NoSQL
![]() MongoDB
MongoDB
![]() Cassandra
Cassandra
![]() Gremlin
Gremlin
![]() 表
表
本文介绍用于缩放数据库或容器(集合、表或图形)吞吐量的最佳做法和策略。 在为任何 Azure Cosmos DB API 增加预配的手动请求单位数(RU/s)或自动缩放任何资源的最大 RU/秒时,概念适用。
必备条件
- 如果不熟悉 Azure Cosmos DB 中的分区和缩放,请参阅 Azure Cosmos DB 中的分区和水平缩放。
- 如果计划缩放 RU/秒(由于 429 个异常),请查看诊断中的指南 并排查“请求速率过大”(429)异常。 在增加 RU/秒之前,请确定问题的根本原因,以及增加 RU/秒是否是正确的解决方案。
缩放 RU/秒的背景信息
发送请求以增加数据库或容器的 RU/s 时,根据请求的 RU/s 和当前的物理分区布局,纵向扩展作会立即或异步完成(通常为 4-6 小时)。
即时纵向扩展:
- 如果当前物理分区布局支持请求的 RU/秒,则 Azure Cosmos DB 无需拆分或添加新分区。
- 因此,操作会立即完成,RU/秒可供使用。
异步纵向扩展:
- 当请求的 RU/s 高于物理分区布局支持的内容时,Azure Cosmos DB 会拆分现有的物理分区。 在资源具有支持请求的 RU/秒所需的最小分区数之前,会发生这种情况。
- 因此,操作可能需要一些时间才能完成,通常需要 4-6 小时。 每个物理分区最多可支持 10,000 RU/秒(适用于所有 API)的吞吐量和 50 GB 存储(适用于所有 API,具有 30 GB 存储的 Cassandra 除外)。
即时缩减:
- 对于缩减作,Azure Cosmos DB 不需要拆分或添加新分区。
- 因此,操作会立即完成,RU/秒可供使用。
- 此作的主要结果是减少每个物理分区的 RU。
如何在不更改分区布局的情况下纵向扩展 RU/秒
步骤 1:查找当前物理分区数
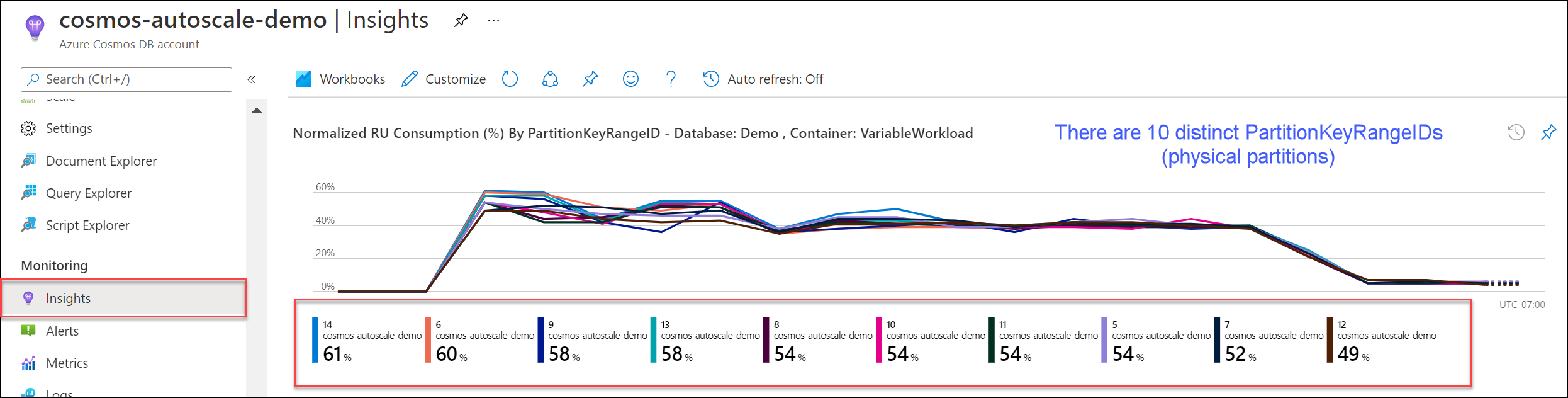
导航到“见解”“吞吐量”>“按 PartitionKeyRangeID 显示的规范化 RU 消耗量 (%)”。 统计 PartitionKeyRangeId 的非重复数。
注意
该图表最多显示 50 个 PartitionKeyRangeIds。 如果资源超过 50 个,可以使用 Azure Cosmos DB REST API 来统计分区总数。
每个 PartitionKeyRangeId 映射到一个物理分区,并分配用于保存一系列可能的哈希值的数据。
Azure Cosmos DB 根据分区键跨逻辑分区和物理分区分布数据,以实现横向缩放。 在数据写入后,Azure Cosmos DB 使用分区键值的哈希来确定数据位于哪个逻辑分区和物理分区。
步骤 2:计算默认最大吞吐量
在无需触发 Azure Cosmos DB 拆分分区的情况下,可以缩放到的最高 RU/秒等于 Current number of physical partitions * 10,000 RU/s。
可以从 Azure Cosmos DB 资源提供程序获取此值。 对你的数据库或容器吞吐量设置对象执行 GET 请求并检索 instantMaximumThroughput 属性。 此值也可在门户中的数据库或容器的 “缩放和设置” 页中使用。
示例
假设现有容器具有五个物理分区和 30,000 RU/秒的手动预配吞吐量。 可以立即增加 RU/秒 5 * 10,000 RU/s = 50,000 RU/s 。 同样,如果我们有一个容器,它的自动缩放最大 RU/秒为 30,000 RU/秒(在 3000 - 30,000 RU/秒之间缩放),我们可以立即将最大 RU/秒增加到 50,000 RU/秒(在 5000 - 50,000 RU/秒之间缩放)。
提示
如果要纵向扩展 RU/秒以响应请求速率太大异常(429s),建议先将 RU/秒增加到当前物理分区布局支持的最高 RU/秒,并评估新 RU/s 是否足够,然后再进一步增加。
如何在异步缩放期间确保数据分布均匀
背景
当 RU/s 超出当前数目 physical partitions * 10,000 RU/s时,Azure Cosmos DB 会拆分现有分区,直到新的分区数 = ROUNDUP(requested RU/s / 10,000 RU/s)。 在拆分期间,父分区拆分为两个子分区。
例如,假设有一个容器,其中包含三个物理分区和 30,000 RU/秒的手动预配吞吐量。 如果将吞吐量增加到 45,000 RU/秒,Azure Cosmos DB 会拆分两个现有物理分区,以便总共存在 ROUNDUP(45,000 RU/s / 10,000 RU/s) = 5 physical partitions。
注意
在拆分期间,应用程序始终可以引入或查询数据。 Azure Cosmos DB 客户端 SDK 和服务会自动处理此方案,并确保将请求路由到正确的物理分区,因此无需执行任何其他用户作。
如果你有一个在存储和请求卷方面均匀分布的工作负荷(通常通过高基数字段进行 /id分区来完成),建议设置 RU/秒,以便纵向扩展时,所有分区都均匀拆分。
为了了解原因,让我们以一个示例为例,其中现有容器具有两个物理分区、20,000 RU/秒和 80 GB 的数据。
由于选择了一个基数较高的良好分区键,数据大致均匀分布在两个物理分区中。 每个物理分区分配有大约 50% 的键空间,这定义为可能的哈希值的总范围。
此外,Azure Cosmos DB 在所有物理分区中均匀分布 RU/秒。 因此,每个物理分区具有 10,000 RU/秒和 50% (40 GB) 的总数据。 下图显示了我们的当前状态。

现在,假设你想要将 RU/秒从 20,000 RU/秒增加到 30,000 RU/秒。
如果只是将 RU/s 增加到 30,000 RU/秒,则只拆分其中一个分区。 拆分后,你有:
- 一个分区,其中包含 50 个数据%(此分区未拆分)。
- 每个分区包含 25 个数据%(这是拆分父级生成的子分区)。
由于 Azure Cosmos DB 在所有物理分区之间均匀分布 RU/秒,因此每个物理分区仍获得 10,000 RU/秒。 但是,现在存储和请求分发存在偏差。
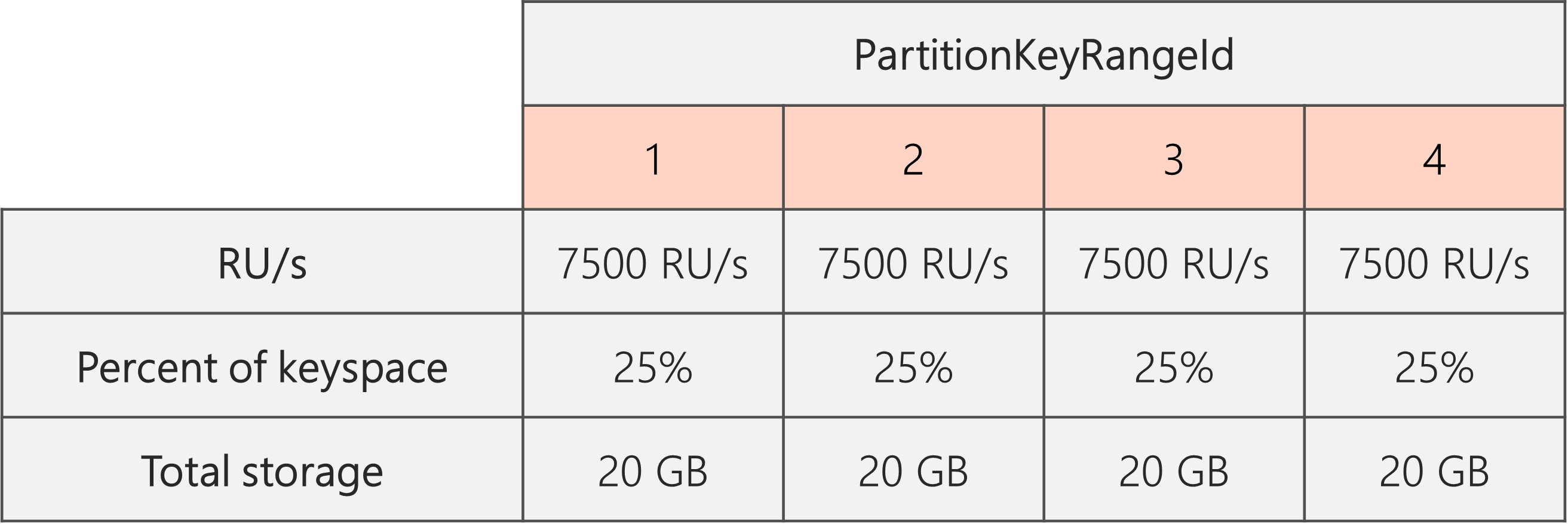
在下图中,分区 3 和 4(分区 2 的子分区)各有 10,000 RU/秒,用于处理 20 GB 数据的请求,而分区 1 有 10,000 RU/秒,用于为数据量(40 GB)的请求提供服务。

为了维护偶数存储分布,可以首先纵向扩展 RU/秒,以确保每个分区拆分。 然后,可以将 RU/秒降低到所需状态。
因此,如果从两个物理分区开始,若要保证分区甚至在拆分后,则需要设置 RU/s,以便最终有四个物理分区。 若要实现此目的,请首先设置 RU/s = 4 * 10,000 RU/s per partition = 40,000 RU/s。 然后,在拆分完成后,将 RU/s 降低到 30,000 RU/秒。
因此,每个物理分区都可以 30,000 RU/s / 4 = 7500 RU/s 为 20 GB 数据的请求提供服务。 总的来说,维护跨分区的均匀存储和请求分布。
常规公式
步骤 1:增加 RU/秒,以确保所有分区均匀拆分
一般情况下,如果你的物理分区的起始数目为 P,并且你想要设置所需的 RU/秒 S:
将 RU/秒增加到:10,000 * P * (2 ^ (ROUNDUP(LOG_2 (S/(10,000 * P))))。 这为所需的值提供最接近的 RU/秒,以确保所有分区均匀拆分。
注意
增加数据库或容器的 RU/秒时,这可能会影响将来可以降低到的最小 RU/秒。 通常,最小 RU/秒等于 MAX(400 RU/s, Current storage in GB * 1 RU/s, Highest RU/s ever provisioned / 100)。 例如,如果曾经缩放到的最高 RU/秒为 100,000 RU/秒,则将来可以设置的最低 RU/秒为 1000 RU/秒。 详细了解最小 RU/秒。
步骤 2:将 RU/秒降低至所需的 RU/秒
例如,假设我们有五个物理分区,即 50,000 RU/秒,并且需要缩放到 150,000 RU/秒。 我们应该首先设置: 10,000 * 5 * (2 ^ (ROUND(LOG_2(150,000/(10,000 * 5)))) = 200,000 RU/s,然后降低到 150,000 RU/秒。
现在,当我们纵向扩展到 200,000 RU/秒时,我们可以在将来设置的最低手动 RU/秒为 2000 RU/秒。 我们可以设置的最低自动缩放最大 RU/秒为 20,000 RU/秒(缩放范围为 2000 - 20,000 RU/秒)。 由于目标 RU/s 为 150,000 RU/秒,因此不受最小 RU/秒的影响。
如何优化大型数据引入的 RU/秒
当你计划将大量数据迁移或引入到 Azure Cosmos DB 时,建议设置容器的 RU/秒,以便 Azure Cosmos DB 预先预配存储你计划提前引入的总数据量所需的物理分区。 否则,在引入期间,Azure Cosmos DB 可能需要拆分分区,这会增加数据引入的时间。
我们可以利用这样一个事实,即在容器创建期间,Azure Cosmos DB 使用起始 RU/秒的启发式公式来计算要开始统计的物理分区数。
步骤 1:查看分区键的选择
遵循选择分区键 的最佳做法 ,以确保在迁移后均匀分配请求卷和存储。
步骤 2:计算所需的物理分区数
Number of physical partitions = Total data size in GB / Target data per physical partition in GB
每个物理分区最多可以容纳 50 GB 的存储(对于适用于 Cassandra 的 API,此项为 30 GB)。 对于 每个物理分区的目标数据 ,应选择的值取决于物理分区的完全打包程度,以及迁移后存储预期会增长多少。
例如,如果预计存储将继续增长,可以选择将该值设置为 30 GB。 假设选择了均匀分布存储的良好分区键,则每个分区大约为 60% 完整(50 GB 的 30 GB)。 在将来写入数据时,可以将其存储在现有的物理分区集上,而无需让服务立即添加更多的物理分区。
相比之下,如果你认为存储不会在迁移后显著增长,则可以选择设置更高的值,例如 45 GB。 这意味着每个分区大约为 90% 完整(45 GB(50 GB)。 这会最大程度地减少数据所分布的物理分区的数量,意味着每个物理分区可以获得预配的总 RU/秒中更大的一部分。
步骤 3:对于所有分区,计算要开始统计的 RU/s 数目
Starting RU/s for all partitions = Number of physical partitions * Initial throughput per physical partition
让我们从一个示例开始,它显示每个物理分区的任意数量的 RU/s。
-
Initial throughput per physical partition = 10,000 RU/s per physical partition使用自动缩放或共享吞吐量数据库时 -
Initial throughput per physical partition = 6000 RU/s per physical partition使用手动吞吐量时
示例
假设要引入的数据量为 1 TB(1,000 GB),并且想要使用手动吞吐量。 Azure Cosmos DB 中每个物理分区的容量为 50 GB。 假设你的目标是将分区打包为 80% 完整(40 GB),为未来的增长留出空间。
这意味着,对于 1 TB 的数据,需要 1000 GB / 40 GB = 25 物理分区。 若要确保使用手动吞吐量获取 25 个物理分区,请首先进行预配 25 * 6000 RU/s = 150,000 RU/s。 然后,在创建容器后,为了帮助引入更快,请在引入开始之前将 RU/s 增加到 250,000 RU/秒(因为已有 25 个物理分区立即发生)。 这样,每个分区最多可以获得 10,000 RU/秒。
如果使用自动缩放吞吐量或共享吞吐量数据库,则首先预配 25 * 10,000 RU/s = 250,000 RU/s25 个物理分区。 由于你已处于 25 个物理分区支持的最高 RU/秒,因此在引入之前不会进一步增加预配的 RU/秒。
从理论上讲,如果使用 250,000 RU/秒和 1 TB 的数据,如果我们假设需要 1 kb 文档和 10 个 RU 进行写入,则引入理论上可以完成: 1000 GB * (1,000,000 kb / 1 GB) * (1 document / 1 kb) * (10 RU / document) * (1 sec / 250,000 RU) * (1 hour / 3600 seconds) = 11.1 hours
这个计算得到是一个估计值,假设执行数据引入的客户端可以使吞吐量完全饱和,并将写入分布到所有物理分区。 最佳做法是,建议在客户端 上对数据进行随机洗牌 。 这可以确保在每一秒,客户端都在写入许多不同的逻辑(从而写入物理)分区。
迁移结束后,可以降低 RU/s 或根据需要启用自动缩放。