适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
Azure Data Lake Storage Gen2 (ADLS Gen2) 是一组专用于大数据分析的功能,内置于 Azure Blob 存储中。 它可使用文件系统和对象存储范例与数据进行交互。
本文概述了如何使用复制活动从/向 Azure Data Lake Storage Gen2 复制数据,并使用数据流在 Azure Data Lake Storage Gen2 中转换数据。 有关详细信息,请阅读 Azure 数据工厂或 Azure Synapse Analytics 的简介文章。
提示
对于数据湖或数据仓库迁移方案,请参阅将数据从数据湖或数据仓库迁移到 Azure 以了解更多信息。
支持的功能
此 Azure Data Lake Storage Gen2 连接器支持以下功能:
| 支持的功能 | IR | 托管专用终结点 |
|---|---|---|
| 复制活动(源/接收器) | (1) (2) | ✓ |
| 映射数据流源(源/接收器) | ① | ✓ |
| Lookup 活动 | (1) (2) | ✓ |
| GetMetadata 活动 | (1) (2) | ✓ |
| Delete 活动 | (1) (2) | ✓ |
① Azure 集成运行时 ② 自承载集成运行时
对于复制活动,使用此连接器可以:
- 通过使用帐户密钥、服务主体或托管标识进行 Azure 资源身份验证来从/向 Azure Data Lake Storage Gen2 复制数据。
- 按原样复制文件,或使用支持的文件格式和压缩编解码器分析/生成文件。
- 在复制期间保留文件元数据。
开始
提示
有关使用 Data Lake Storage Gen2 连接器的演练,请参阅将数据加载到 Azure Data Lake Storage Gen2。
若要使用管道执行复制活动,可以使用以下工具或 SDK 之一:
使用 UI 创建 Azure Data Lake Storage Gen2 链接服务
使用以下步骤在 Azure 门户 UI 中创建 Azure Data Lake Storage Gen2 链接服务。
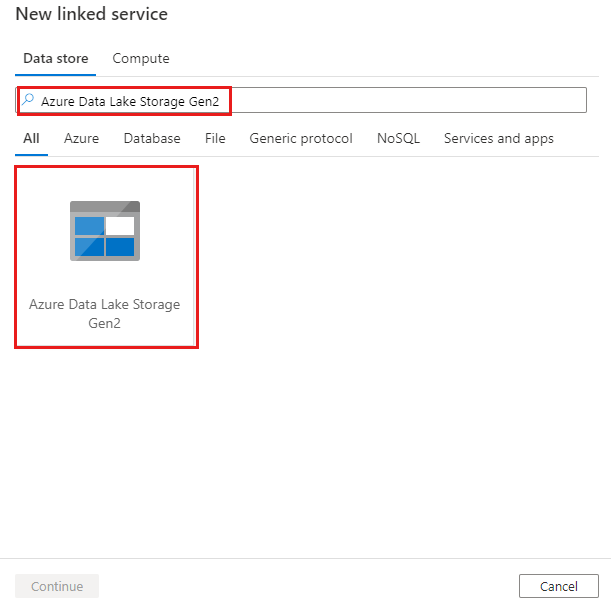
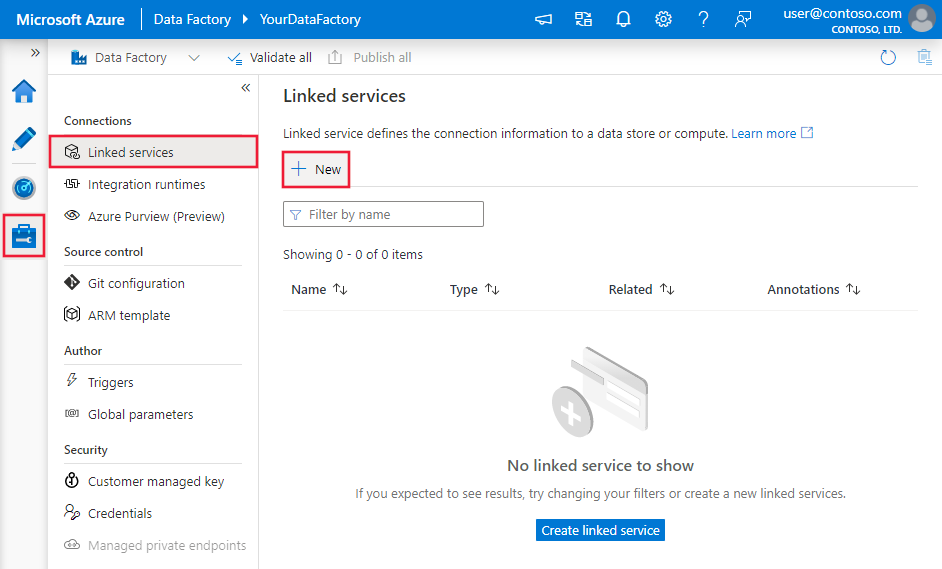
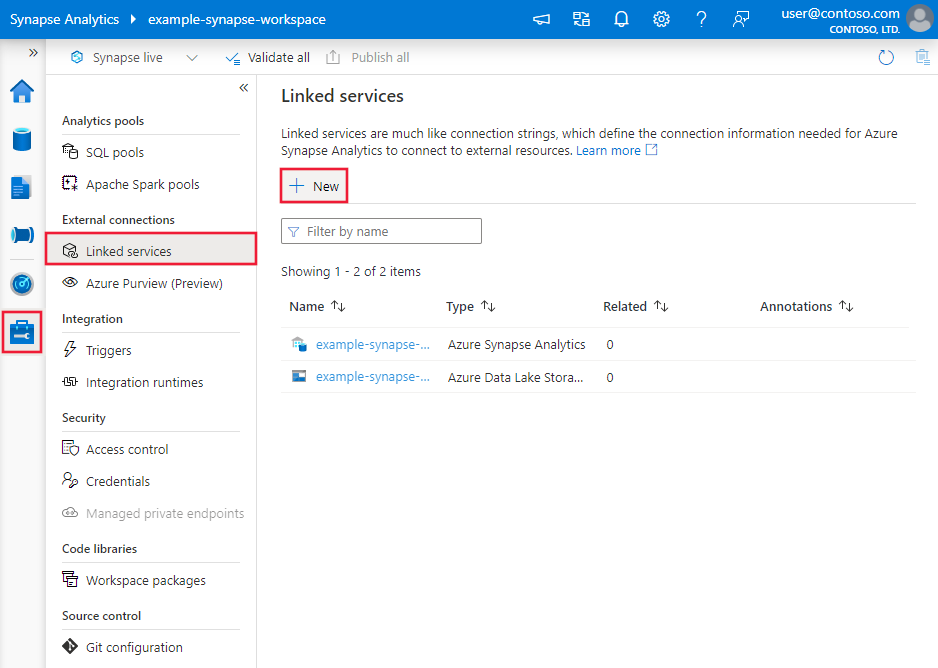
浏览到 Azure 数据工厂或 Synapse 工作区中的“管理”选项卡,并选择“链接服务”,然后单击“新建”:
搜索“Azure Data Lake Storage Gen2”并选择“Azure Data Lake Storage Gen2 连接器”。
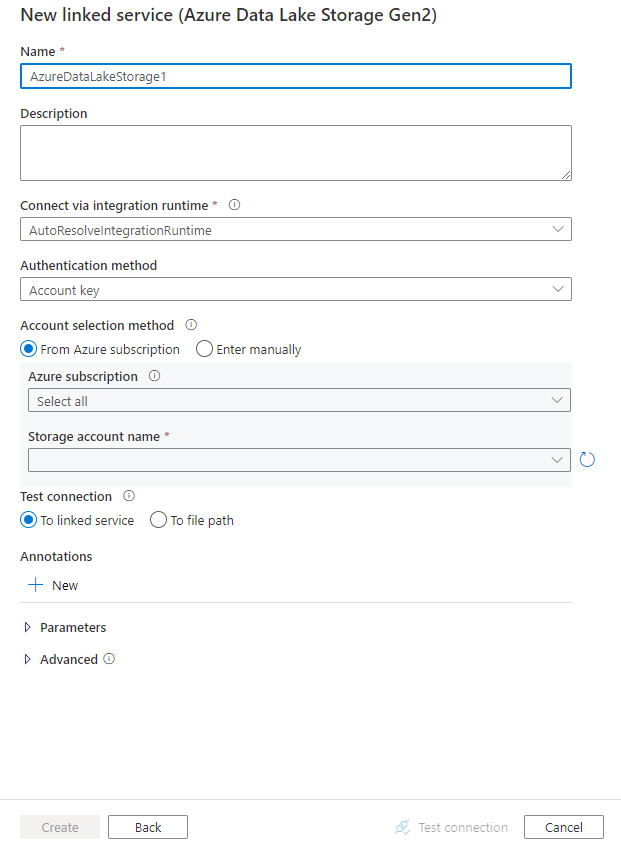
配置服务详细信息、测试连接并创建新的链接服务。
连接器配置详细信息
下面各部分介绍了用于定义特定于 Data Lake Storage Gen2 的数据工厂和 Synapse 管道实体的属性。
链接服务属性
Azure Data Lake Storage Gen2 连接器支持以下身份验证类型。 请参阅相应部分的了解详细信息:
注意
- 如果您想使用 Azure 集成运行时,通过在 Azure 存储防火墙上启用“允许受信任的 Microsoft 服务访问此存储帐户”选项来连接到 Data Lake Storage Gen2,那么您必须使用托管标识身份验证。 有关 Azure 存储防火墙设置的详细信息,请参阅配置 Azure 存储防火墙和虚拟网络。
- 在使用 PolyBase 或 COPY 语句将数据载入 Azure Synapse Analytics 时,如果源或暂存 Data Lake Storage Gen2 配置了 Azure 虚拟网络终结点,则必须按照 Azure Synapse 的要求使用托管标识身份验证。 请参阅托管标识身份验证部分,其中提供了更多配置先决条件。
帐户密钥身份验证
若要使用存储帐户密钥身份验证,需支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | type 属性必须设置为 AzureBlobFS。 | 是 |
| url | Data Lake Storage Gen2 的终结点,其模式为 https://<accountname>.dfs.core.chinacloudapi.cn。 |
是 |
| accountKey | Data Lake Storage Gen2 的帐户密钥 将此字段标记为 SecureString 以安全地存储它,或引用存储在 Azure Key Vault 中的机密。 | 是 |
| connectVia | 用于连接到数据存储的集成运行时。 可使用 Azure Integration Runtime 或自承载集成运行时(如果数据存储位于专用网络)。 如果没有指定此属性,则使用默认的 Azure Integration Runtime。 | 否 |
注意
使用帐户密钥身份验证时,不支持辅助 ADLS 文件系统终结点。 可以使用其他身份验证类型。
示例:
{
"name": "AzureDataLakeStorageGen2LinkedService",
"properties": {
"type": "AzureBlobFS",
"typeProperties": {
"url": "https://<accountname>.dfs.core.chinacloudapi.cn",
"accountkey": {
"type": "SecureString",
"value": "<accountkey>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
共享访问签名身份验证
共享访问签名对存储帐户中的资源提供委托访问。 使用共享访问签名可以在指定的时间内授予客户端对存储帐户中对象的有限访问权限。
无需共享帐户访问密钥。 共享访问签名是一个 URI,在其查询参数中包含对存储资源已验证访问所需的所有信息。 若要使用共享访问签名访问存储资源,客户端只需将共享访问签名传入到相应的构造函数或方法。
有关共享访问签名的详细信息,请参阅共享访问签名:了解共享访问签名模型。
注意
- 该服务现在支持服务共享访问签名和帐户共享访问签名 。 有关共享访问签名的详细信息,请参阅使用共享访问签名授予对 Azure 存储资源的有限访问权限。
- 在稍后的数据集配置中,文件夹路径是从容器级别开始的绝对路径。 需要配置与 SAS URI 中的路径一致的路径。
以下属性支持使用共享访问签名身份验证:
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 |
type 属性必须设置为 AzureBlobFS(建议) |
是 |
| sasUri | 指定存储资源(例如 Blob 或容器)的共享访问签名 URI。 将此字段标记为 SecureString 以安全存储它。 还可以将 SAS 令牌放在 Azure Key Vault 中,以使用自动轮换和删除令牌部分。 有关详细信息,请参阅以下示例和在 Azure Key Vault 中存储凭据。 |
是 |
| connectVia | 用于连接到数据存储的集成运行时。 可使用 Azure Integration Runtime 或自承载集成运行时(如果数据存储位于专用网络中)。 如果未指定此属性,服务会使用默认的 Azure Integration Runtime。 | 否 |
注意
如果使用 AzureStorage 类型的链接服务,则仍然按原样支持它。 但是,建议今后使用这个新的 AzureDataLakeStorageGen2 链接服务类型。
示例:
{
"name": "AzureDataLakeStorageGen2LinkedService",
"properties": {
"type": "AzureBlobFS",
"typeProperties": {
"sasUri": {
"type": "SecureString",
"value": "<SAS URI of the Azure Storage resource e.g. https://<accountname>.blob.core.chinacloudapi.cn/?sv=<storage version>&st=<start time>&se=<expire time>&sr=<resource>&sp=<permissions>&sip=<ip range>&spr=<protocol>&sig=<signature>>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
示例:在 Azure Key Vault 中存储帐户密钥
{
"name": "AzureDataLakeStorageGen2LinkedService",
"properties": {
"type": "AzureBlobFS",
"typeProperties": {
"sasUri": {
"type": "SecureString",
"value": "<SAS URI of the Azure Storage resource without token e.g. https://<accountname>.blob.core.chinacloudapi.cn/>"
},
"sasToken": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName with value of SAS token e.g. ?sv=<storage version>&st=<start time>&se=<expire time>&sr=<resource>&sp=<permissions>&sip=<ip range>&spr=<protocol>&sig=<signature>>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
在创建共享访问签名 URI 时,请注意以下几点:
- 根据链接服务(读取、写入、读/写)的用法,设置针对对象的适当读/写权限。
- 根据需要设置“到期时间”。 确保存储对象的访问权限不会在管道的活动期限内过期。
- 应该根据需要在正确的容器或 Blob 中创建 URI。 数据工厂或 Synapse 管道可以使用 Blob 的共享访问签名 URI 访问该特定 blob。 数据工厂或 Synapse 管道可以使用 Blob 存储容器的共享访问签名 URI 迭代该容器中的 blob。 以后若要提供更多/更少对象的访问权限或需要更新共享访问签名 URI,请记得使用新 URI 更新链接服务。
服务主体身份验证
若要使用服务主体身份验证,请按照以下步骤操作。
将应用程序注册到 Microsoft 标识平台。 快速入门:通过 Microsoft 标识平台注册应用程序。 记下以下值,这些值用于定义链接服务:
- 应用程序 ID
- 应用程序密钥
- 租户 ID
向服务主体授予适当权限。 查看文件和目录上的访问控制列表中的一些示例,来了解 Data Lake Storage Gen2 中的权限的工作原理。
- 作为源:在存储资源管理器中,至少授予对所有上游文件夹和文件系统的“执行”权限,并授予对文件的“读取”权限以进行复制 。 或者,在访问控制 (IAM) 中,授予至少“存储 Blob 数据读取者”角色。
- 作为接收器:在存储资源管理器中,至少授予所有上游文件夹和文件系统的“执行”权限,以及接收器文件夹的“写入”权限 。 或者,在访问控制 (IAM) 中,授予至少“存储 Blob 数据参与者”角色。
注意
如果使用 UI 编写,并且服务主体未在 IAM 中分配“存储 Blob 数据读取者/参与者”角色,请在测试连接或浏览/导航文件夹时,选择“测试指定路径的连接”或“从指定路径浏览”,并指定具有 读取 + 执行 权限的路径以继续。
链接服务支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | type 属性必须设置为 AzureBlobFS。 | 是 |
| url | Data Lake Storage Gen2 的终结点,其模式为 https://<accountname>.dfs.core.chinacloudapi.cn。 |
是 |
| servicePrincipalId | 指定应用程序的客户端 ID。 | 是 |
| servicePrincipalCredentialType | 要用于服务主体身份验证的凭据类型。 允许的值为“ServicePrincipalKey”和“ServicePrincipalCert”。 | 是 |
| servicePrincipalCredential | 服务主体凭据。 使用 ServicePrincipalKey 作为凭据类型时,请指定应用程序的密钥。 将此字段标记为 SecureString 以安全地存储它,或引用存储在 Azure Key Vault 中的机密。 当使用 ServicePrincipalCert 作为凭据时,请引用 Azure Key Vault 中的证书并确保证书内容类型为 PKCS #12。 |
是 |
| servicePrincipalKey | 指定应用程序的密钥。 将此字段标记为 SecureString 以安全地存储它,或引用存储在 Azure Key Vault 中的机密。 servicePrincipalId
+
servicePrincipalKey 仍按原样支持此属性。 当 ADF 添加新的服务主体证书身份验证时,服务主体身份验证的新模型为 servicePrincipalId + servicePrincipalCredentialType + servicePrincipalCredential。 |
否 |
| 租户 | 指定应用程序的租户信息(域名或租户 ID)。 将鼠标悬停在 Azure 门户右上角进行检索。 | 是 |
| azureCloudType | 对于服务主体身份验证,请指定 Microsoft Entra 应用程序注册到的 Azure 云环境的类型。 允许的值为“AzureChina”。 默认情况下,使用数据工厂或 Synapse 管道的云环境。 |
否 |
| connectVia | 用于连接到数据存储的集成运行时。 可使用 Azure Integration Runtime 或自承载集成运行时(如果数据存储位于专用网络)。 如果未指定,则使用默认 Azure Integration Runtime。 | 否 |
示例:使用服务主体密钥身份验证
也可以将服务主体密钥存储在 Azure Key Vault 中。
{
"name": "AzureDataLakeStorageGen2LinkedService",
"properties": {
"type": "AzureBlobFS",
"typeProperties": {
"url": "https://<accountname>.dfs.core.chinacloudapi.cn",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalKey",
"servicePrincipalCredential": {
"type": "SecureString",
"value": "<service principal key>"
},
"tenant": "<tenant info, e.g. microsoft.partner.onmschina.cn>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
示例:使用服务主体证书身份验证
{
"name": "AzureDataLakeStorageGen2LinkedService",
"properties": {
"type": "AzureBlobFS",
"typeProperties": {
"url": "https://<accountname>.dfs.core.chinacloudapi.cn",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalCert",
"servicePrincipalCredential": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<AKV reference>",
"type": "LinkedServiceReference"
},
"secretName": "<certificate name in AKV>"
},
"tenant": "<tenant info, e.g. microsoft.partner.onmschina.cn>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
系统分配的托管标识身份验证
数据工厂或 Synapse 工作区可与系统分配的托管标识相关联。 你可以像使用自己的服务主体一样,直接使用此系统分配的托管标识进行 Data Lake Storage Gen2 身份验证。 这样,此指定的工厂或工作区就可以访问以及向/从 Data Lake Storage Gen2 复制数据。
若要使用系统分配的托管标识身份验证,请执行以下步骤。
通过复制随工厂或 Synapse 工作区一起生成的托管标识对象 ID 的值,检索系统分配的托管标识信息。
向系统分配的托管标识授予适当权限。 查看文件和目录上的访问控制列表中的一些示例,来了解 Data Lake Storage Gen2 中的权限的工作原理。
- 作为源:在存储资源管理器中,至少授予对所有上游文件夹和文件系统的“执行”权限,并授予对文件的“读取”权限以进行复制 。 或者,在访问控制 (IAM) 中,授予至少“存储 Blob 数据读取者”角色。
- 作为接收器:在存储资源管理器中,至少授予所有上游文件夹和文件系统的“执行”权限,以及接收器文件夹的“写入”权限 。 或者,在访问控制 (IAM) 中,授予至少“存储 Blob 数据参与者”角色。
链接服务支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | type 属性必须设置为 AzureBlobFS。 | 是 |
| url | Data Lake Storage Gen2 的终结点,其模式为 https://<accountname>.dfs.core.chinacloudapi.cn。 |
是 |
| connectVia | 用于连接到数据存储的集成运行时。 可使用 Azure Integration Runtime 或自承载集成运行时(如果数据存储位于专用网络)。 如果未指定,则使用默认 Azure Integration Runtime。 | 否 |
示例:
{
"name": "AzureDataLakeStorageGen2LinkedService",
"properties": {
"type": "AzureBlobFS",
"typeProperties": {
"url": "https://<accountname>.dfs.core.chinacloudapi.cn",
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
用户分配的托管标识身份验证
可以为数据工厂分配一个或多个用户分配的托管标识。 可以将此用户分配的托管标识用于 Blob 存储身份验证,该身份验证允许访问和复制 Data Lake Storage Gen2 中的数据或将数据复制到其中。 若要详细了解 Azure 资源托管标识,请参阅 Azure 资源托管标识
若要使用用户分配的托管标识身份验证,请执行以下步骤:
创建一个或多个用户分配的托管标识并授予对 Azure Data Lake Storage Gen2 的访问权限。 查看文件和目录上的访问控制列表中的一些示例,来了解 Data Lake Storage Gen2 中的权限的工作原理。
- 作为源:在存储资源管理器中,至少授予对所有上游文件夹和文件系统的“执行”权限,并授予对文件的“读取”权限以进行复制 。 或者,在访问控制 (IAM) 中,授予至少“存储 Blob 数据读取者”角色。
- 作为接收器:在存储资源管理器中,至少授予所有上游文件夹和文件系统的“执行”权限,以及接收器文件夹的“写入”权限 。 或者,在访问控制 (IAM) 中,授予至少“存储 Blob 数据参与者”角色。
为数据工厂分配一个或多个用户分配的托管标识,并为每个用户分配的托管标识创建凭据。
链接服务支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | type 属性必须设置为 AzureBlobFS。 | 是 |
| url | Data Lake Storage Gen2 的终结点,其模式为 https://<accountname>.dfs.core.chinacloudapi.cn。 |
是 |
| 凭据 | 将用户分配的托管标识指定为凭据对象。 | 是 |
| connectVia | 用于连接到数据存储的集成运行时。 可使用 Azure Integration Runtime 或自承载集成运行时(如果数据存储位于专用网络)。 如果未指定,则使用默认 Azure Integration Runtime。 | 否 |
示例:
{
"name": "AzureDataLakeStorageGen2LinkedService",
"properties": {
"type": "AzureBlobFS",
"typeProperties": {
"url": "https://<accountname>.dfs.core.chinacloudapi.cn",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
注意
如果使用数据工厂 UI 进行配置,并且托管标识未在 IAM 中设置为“存储 Blob 数据读取者/贡献者”角色,请在执行测试连接或浏览/导航文件夹时,选择“测试文件路径连接”或“从指定路径浏览”,并指定具有读取 + 执行权限的路径以继续。
重要
如果使用 PolyBase 或 COPY 语句将 Data Lake Storage Gen2 中的数据加载到 Azure Synapse Analytics 中,则对 Data Lake Storage Gen2 使用托管标识身份验证时,请确保也按照此指南中的步骤 1 到步骤 3 进行操作。 这两个步骤将向 Microsoft Entra ID 注册服务器并将“存储 Blob 数据参与者”角色分配给服务器。 其余事项由数据工厂处理。 如果使用 Azure 虚拟网络终结点配置 Blob 存储,还需要按照 Azure Synapse 的要求,在 Azure 存储帐户“防火墙和虚拟网络”设置菜单下开启“允许受信任的 Microsoft 服务访问此存储帐户”。
数据集属性
有关可用于定义数据集的各个部分和属性的完整列表,请参阅数据集。
Azure 数据工厂支持以下文件格式。 请参阅每一篇介绍基于格式的设置的文章。
在基于格式的数据集中的 location 设置下,Data Lake Storage Gen2 支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | 数据集中 location 下的 type 属性必须设置为 AzureBlobFSLocation。 |
是 |
| fileSystem | Data Lake Storage Gen2 文件系统名称。 | 否 |
| folderPath | 给定文件系统下的文件夹路径。 若要使用通配符来筛选文件夹,请跳过此设置,并在活动源设置中指定它。 | 否 |
| fileName | 给定 fileSystem + folderPath 下的文件名。 若要使用通配符来筛选文件,请跳过此设置,并在活动源设置中指定它。 | 否 |
示例:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Data Lake Storage Gen2 linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobFSLocation",
"fileSystem": "filesystemname",
"folderPath": "folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
复制活动属性
要完整了解可供活动定义使用的各个部分和属性,请参阅复制活动配置和管道和活动。 本部分列出了 Data Lake Storage Gen2 源和接收器支持的属性。
Azure Data Lake Storage Gen2 作为源类型
Azure 数据工厂支持以下文件格式。 请参阅每一篇介绍基于格式的设置的文章。
从 ADLS Gen2 复制数据的方式有多种:
- 从数据集中指定的给定路径复制。
- 有关针对文件夹路径或文件名的通配符筛选器,请参阅
wildcardFolderPath和wildcardFileName。 - 将给定文本文件中定义的文件复制为文件集(请参阅
fileListPath)。
在基于格式的复制源中的 storeSettings 设置下,Data Lake Storage Gen2 支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 |
storeSettings 下的 type 属性必须设置为 AzureBlobFSReadSettings。 |
是 |
| 找到要复制的文件: | ||
| 选项 1:静态路径 |
从数据集中指定的给定文件系统或文件夹/文件路径复制。 若要复制文件系统/文件夹中的所有文件,请另外将 wildcardFileName 指定为 *。 |
|
| 选项 2:通配符 - wildcardFolderPath |
数据集中配置的给定文件系统下带有通配符的文件夹路径,用于筛选源文件夹。 允许的通配符为: *(匹配零个或更多个字符)和 ?(匹配零个或单个字符);如果实际文件夹名称中包含通配符或此转义字符,请使用 ^ 进行转义。 请参阅文件夹和文件筛选器示例中的更多示例。 |
否 |
| 选项 2:通配符 - 通配符文件名 |
给定文件系统 + folderPath/wildcardFolderPath 下带有通配符的文件名,用于筛选源文件。 允许的通配符为: *(匹配零个或更多个字符)和 ?(匹配零个或单个字符);如果实际文件名中包含通配符或此转义字符,请使用 ^ 进行转义。 请参阅文件夹和文件筛选器示例中的更多示例。 |
是 |
| 选项 3:文件列表 - 文件列表路径 |
指明复制给定文件集。 指向包含要复制的文件列表的文本文件,每行一个文件(即数据集中所配置路径的相对路径)。 使用此选项时,请不要在数据集中指定文件名。 请参阅文件列表示例中的更多示例。 |
否 |
| 其他设置: | ||
| recursive | 指示是要从子文件夹中以递归方式读取数据,还是只从指定的文件夹中读取数据。 当 recursive 设置为 true 且接收器是基于文件的存储时,将不会在接收器上复制或创建空的文件夹或子文件夹。 允许的值为 true(默认值)和 false。 如果配置 fileListPath,则此属性不适用。 |
否 |
| deleteFilesAfterCompletion | 指示是否会在二进制文件成功移到目标存储后将其从源存储中删除。 文件删除按文件进行。因此,当复制活动失败时,你会看到一些文件已经复制到目标并从源中删除,而另一些文件仍保留在源存储中。 此属性仅在二进制文件复制方案中有效。 默认值:false。 |
否 |
| modifiedDatetimeStart | 基于属性“上次修改时间”的文件筛选器。 如果文件的上次修改时间大于或等于 modifiedDatetimeStart 并且小于 modifiedDatetimeEnd,将选择这些文件。 该时间应用于 UTC 时区,格式为“2018-12-01T05:00:00Z”。 属性可以为 NULL,这意味着不向数据集应用任何文件属性筛选器。 如果 modifiedDatetimeStart 具有日期/时间值,但 modifiedDatetimeEnd 为 NULL,则意味着将选中“上次修改时间”属性大于或等于该日期/时间值的文件。 如果 modifiedDatetimeEnd 具有日期/时间值,但 modifiedDatetimeStart 为 NULL,则意味着将选中“上次修改时间”属性小于该日期/时间值的文件。如果配置 fileListPath,则此属性不适用。 |
否 |
| modifiedDatetimeEnd | 同上。 | 否 |
| enablePartitionDiscovery | 对于已分区的文件,请指定是否分析文件路径中的分区,并将其添加为其他源列。 允许的值为 false(默认)和 true 。 |
否 |
| partitionRootPath | 启用分区发现时,请指定绝对根路径,以便将已分区文件夹读取为数据列。 如果未指定,则默认情况下, - 在数据集或源的文件列表中使用文件路径时,分区根路径是在数据集中配置的路径。 - 使用通配符文件夹筛选器时,分区根路径是第一个通配符前的子路径。 例如,假设你将数据集中的路径配置为“root/folder/year=2020/month=08/day=27”: - 如果将分区根路径指定为“root/folder/year=2020”,则除了文件内的列外,复制活动还将生成另外两个列 month 和 day,其值分别为“08”和“27”。- 如果未指定分区根路径,则不会生成额外的列。 |
否 |
| maxConcurrentConnections | 活动运行期间与数据存储建立的并发连接的上限。 仅在要限制并发连接时指定一个值。 | 否 |
示例:
"activities":[
{
"name": "CopyFromADLSGen2",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "AzureBlobFSReadSettings",
"recursive": true,
"wildcardFolderPath": "myfolder*A",
"wildcardFileName": "*.csv"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Azure Data Lake Storage Gen2 作为接收器类型
Azure 数据工厂支持以下文件格式。 请参阅每一篇介绍基于格式的设置的文章。
在基于格式的复制接收器中的 storeSettings 设置下,Data Lake Storage Gen2 支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 |
storeSettings 下的 type 属性必须设置为 AzureBlobFSWriteSettings。 |
是 |
| copyBehavior | 定义以基于文件的数据存储中的文件为源时的复制行为。 允许值包括: - PreserveHierarchy(默认):将文件层次结构保留到目标文件夹中。 指向源文件夹的源文件相对路径与指向目标文件夹的目标文件相对路径相同。 - FlattenHierarchy:源文件夹中的所有文件都位于目标文件夹的第一级中。 目标文件具有自动生成的名称。 - MergeFiles:将源文件夹中的所有文件合并到一个文件中。 如果指定了文件名,则合并文件的名称为指定名称。 否则,它是自动生成的文件名。 |
否 |
| blockSizeInMB | 指定用于将数据写入 ADLS Gen2 的块大小(以 MB 为单位)。 详细了解块 Blob。 允许的值介于 4 MB 到 100 MB 之间。 默认情况下,ADF 会根据源存储类型和数据自动确定块大小。 以非二进制格式复制到 ADLS Gen2 时,默认块大小为 100 MB,这样最多能容纳大约 4.75 TB 数据。 如果数据量不大,那么使用网络不佳的自托管集成运行时可能会导致操作超时或性能问题,这时候它可能不是最佳选择。 可以显式指定块大小,同时确保 blockSizeInMB*50000 足够大来存储数据,否则复制活动运行将失败。 |
否 |
| maxConcurrentConnections | 活动运行期间与数据存储建立的并发连接的上限。 仅在要限制并发连接时指定一个值。 | 否 |
| 元数据 | 在复制到接收器时设置自定义元数据。
metadata 数组下的每个对象都表示一个额外的列。
name 定义元数据键名称,value 表示该键的数据值。 如果使用了保留属性功能,则指定的元数据会与源文件元数据联合,或者会被其覆盖。允许的数据值为: - $$LASTMODIFIED:保留变量指示存储源文件的上次修改时间。 仅适用于二进制格式的基于文件的源。- 表达式 - 静态值 |
否 |
示例:
"activities":[
{
"name": "CopyToADLSGen2",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Parquet output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "ParquetSink",
"storeSettings":{
"type": "AzureBlobFSWriteSettings",
"copyBehavior": "PreserveHierarchy",
"metadata": [
{
"name": "testKey1",
"value": "value1"
},
{
"name": "testKey2",
"value": "value2"
},
{
"name": "lastModifiedKey",
"value": "$$LASTMODIFIED"
}
]
}
}
}
}
]
文件夹和文件筛选器示例
本部分介绍使用通配符筛选器生成文件夹路径和文件名的行为。
| folderPath | fileName | recursive | 源文件夹结构和筛选器结果(用粗体表示的文件已检索) |
|---|---|---|---|
Folder* |
(为空,使用默认值) | false | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
(为空,使用默认值) | true | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
false | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
true | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
文件列表示例
本部分介绍了在复制活动源中使用文件列表路径时的结果行为。
假设有以下源文件夹结构,并且要复制加粗显示的文件:
| 示例源结构 | FileListToCopy.txt 中的内容 | ADF 配置 |
|---|---|---|
| filesystem FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv 元数据 FileListToCopy.txt |
File1.csv Subfolder1/File3.csv Subfolder1/File5.csv |
在数据集中: - 文件系统: filesystem- 文件夹路径: FolderA在复制活动源中: - 文件列表路径: filesystem/Metadata/FileListToCopy.txt 文件列表路径指向同一数据存储中的文本文件,其中包含要复制的文件列表,每行一个文件,以及在数据集中配置的路径的相对路径。 |
一些 recursive 和 copyBehavior 示例
本节介绍了将 recursive 和 copyBehavior 值进行不同组合所产生的复制操作行为。
| recursive | copyBehavior | 源文件夹结构 | 生成目标 |
|---|---|---|---|
| true | preserveHierarchy | Folder1 文件 1 文件 2 Subfolder1 File3 File4 File5 |
使用与源相同的结构创建目标 Folder1: Folder1 文件 1 文件 2 Subfolder1 File3 File4 File5 |
| true | flattenHierarchy | Folder1 文件 1 文件 2 Subfolder1 File3 File4 File5 |
使用以下结构创建目标 Folder1: Folder1 File1 的自动生成的名称 File2 的自动生成的名称 File3 的自动生成的名称 File4 的自动生成的名称 File5 的自动生成的名称 |
| true | mergeFiles | Folder1 文件 1 文件 2 Subfolder1 File3 File4 File5 |
使用以下结构创建目标 Folder1: Folder1 File1 + File2 + File3 + File4 + File5 的内容将合并到一个文件中,且自动生成文件名。 |
| false | preserveHierarchy | Folder1 文件 1 文件 2 Subfolder1 File3 File4 File5 |
使用以下结构创建目标 Folder1: Folder1 文件 1 文件 2 没有选取包含 File3、File4 和 File5 的 Subfolder1。 |
| false | flattenHierarchy | Folder1 文件 1 文件 2 Subfolder1 File3 File4 File5 |
使用以下结构创建目标 Folder1: Folder1 File1 的自动生成的名称 File2 的自动生成的名称 没有选取包含 File3、File4 和 File5 的 Subfolder1。 |
| false | mergeFiles | Folder1 文件 1 文件 2 Subfolder1 File3 File4 File5 |
使用以下结构创建目标 Folder1: Folder1 File1 + File2 的内容将合并到一个文件中,且自动生成文件名。 File1 的自动生成的名称 没有选取包含 File3、File4 和 File5 的 Subfolder1。 |
在复制期间保留元数据
将文件从 Amazon S3/Azure Blob/Azure Data Lake Storage Gen2 复制到 Azure Data Lake Storage Gen2/Azure Blob 时,可以选择保留文件元数据和数据。 从保留元数据中了解更多信息。
映射数据流属性
在映射数据流中转换数据时,可以在 Azure Data Lake Storage Gen2 中读取和写入以下格式的文件:
格式特定的设置位于该格式的文档中。 有关详细信息,请参阅映射数据流中的源转换和映射数据流中的接收器转换。
源转换
在源转换中,可以从 Azure Data Lake Storage Gen2 中的容器、文件夹或单个文件进行读取。 通过“源选项”选项卡,可以管理如何读取文件。
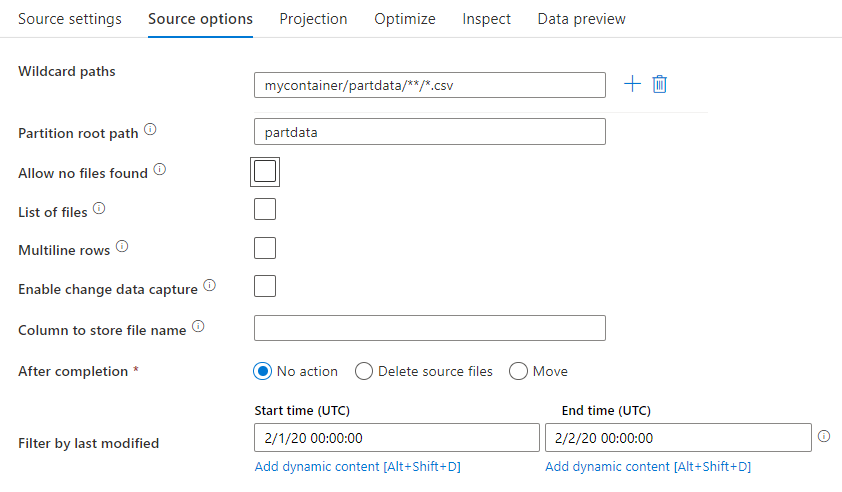
通配符路径: 如果使用通配符模式,则是指示 ADF 在单个“源转换”中遍历每个匹配的文件夹和文件。 这是在单个流中处理多个文件的有效方法。 使用将鼠标悬停在现有通配符模式上时出现的“+”号来添加多个通配符匹配模式。
从源容器中,选择与模式匹配的一系列文件。 数据集中只能指定容器。 因此,通配符路径必须也包含根文件夹中的文件夹路径。
通配符示例:
*表示任意字符集**表示递归目录嵌套?替换一个字符[]与括号中众多字符中的一个匹配/data/sales/**/*.csv获取 /data/sales 下的所有 csv 文件/data/sales/20??/**/获取 20 世纪的所有文件/data/sales/*/*/*.csv获取比 /data/sales 低两个级别的 csv 文件/data/sales/2004/*/12/[XY]1?.csv获取 2004 年 12 月的所有以 X 或 Y 开头且前缀为两位数的 csv 文件
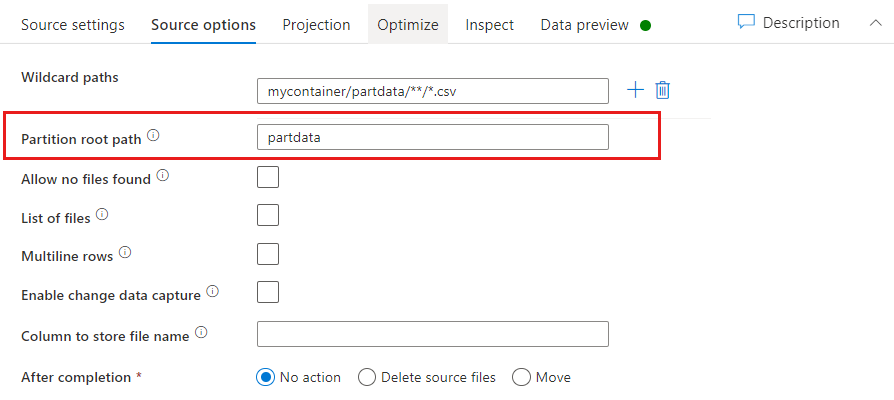
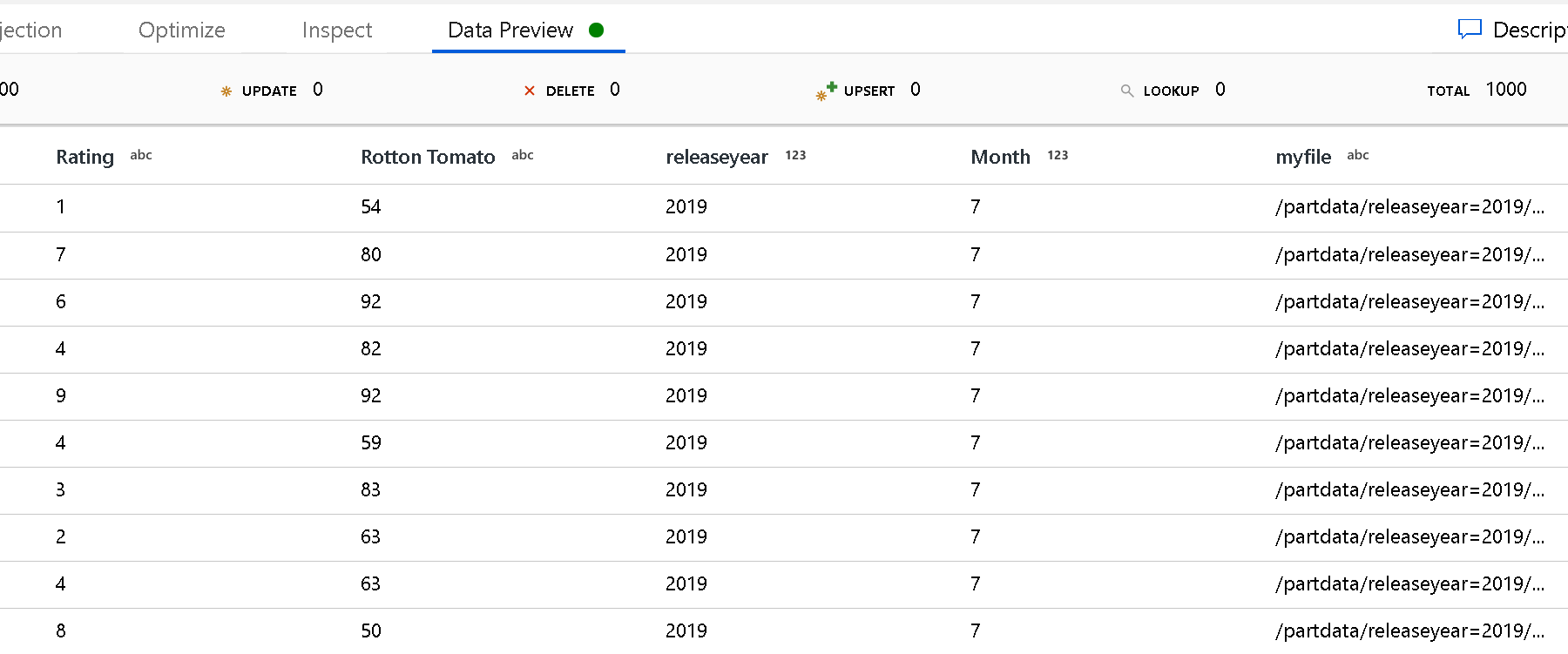
分区根路径:如果文件源中存在 格式(例如 year=2019)的分区文件夹,则可以向该分区文件夹树的顶层分配数据流中的列名称。
首先,设置一个通配符,用于包括分区文件夹以及要读取的叶文件的所有路径。
使用“分区根路径”设置来定义文件夹结构的顶级。 通过数据预览查看数据内容时会看到,ADF 会添加在每个文件夹级别中找到的已解析的分区。
文件列表: 这是一个文件集。 创建一个文本文件,其中包含要处理的相对路径文件的列表。 指向此文本文件。
用于存储文件名的列: 将源文件的名称存储在数据的列中。 请在此处输入新列名称以存储文件名字符串。
完成后: 数据流运行后,可以选择不对源文件执行任何操作、删除源文件或移动源文件。 移动路径是相对路径。
要将源文件移到其他位置进行后期处理,请首先选择“移动”以执行文件操作。 然后,设置“从”目录。 如果未对路径使用任何通配符,则“从”设置中的文件夹将是与源文件夹相同的文件夹。
如果源路径包含通配符,则语法将如下所示:
/data/sales/20??/**/*.csv
可将“从”指定为
/data/sales
将“到”指定为
/backup/priorSales
在此例中,源自 /data/sales 下的所有文件都将移动到 /backup/priorSales。
注意
仅当从在管道中使用“执行数据流”活动的管道运行进程(管道调试或执行运行)中启动数据流时,文件操作才会运行。 文件操作不会在数据流调试模式下运行。
按上次修改时间筛选: 通过指定上次修改的日期范围,可以筛选要处理的文件。 所有日期时间均采用 UTC 格式。
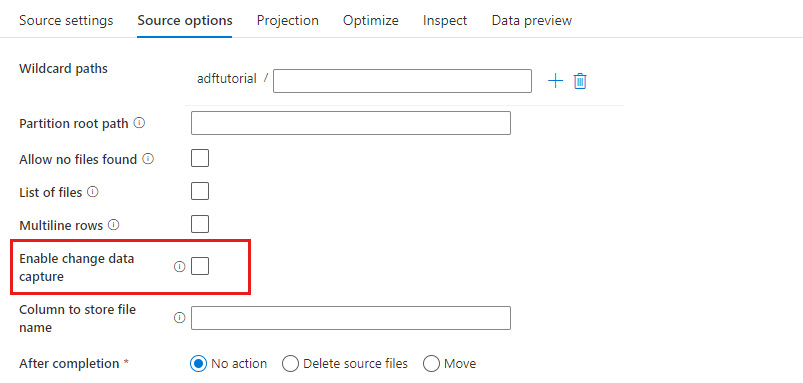
启用变更数据捕获:如果为 true,则只能从上次运行中获取新的或更改后的文件。 将始终从首次运行中获取完整快照数据的初始加载,然后仅在下次运行中捕获新的或更改后的文件。 有关详细信息,请参阅变更数据捕获。
接收器属性
在接收器转换中,可以写入到 Azure Data Lake Storage Gen2 中的容器或文件夹。 通过“设置”选项卡,可以管理文件的写入方式。
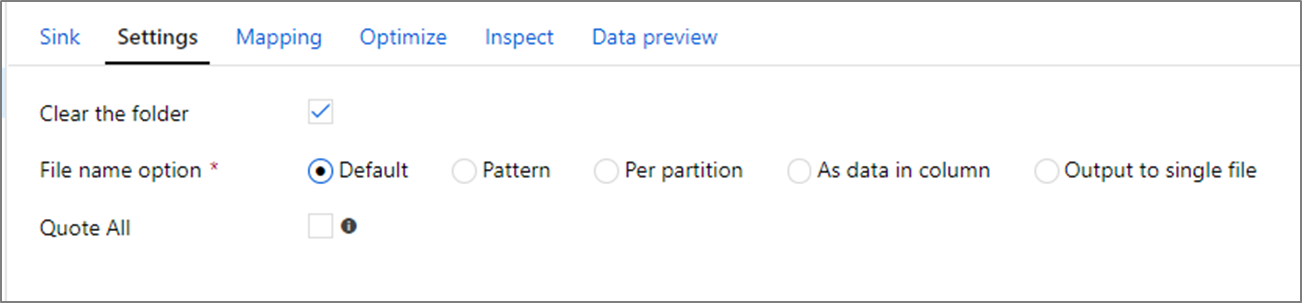
清除文件夹: 确定在写入数据之前是否清除目标文件夹。
文件名选项: 确定目标文件在目标文件夹中的命名方式。 文件名选项有:
- 默认:允许 Spark 根据 PART 默认值为文件命名。
- 模式:输入一种模式,该模式枚举每个分区的输出文件。 例如,loans[n].csv 将创建 loans1.csv、loans2.csv 等等。
- 每个分区:为每个分区输入一个文件名。
- 作为列中的数据:将输出文件设置为列的值。 此路径是数据集容器而非目标文件夹的相对路径。 如果数据集中有文件夹路径,则会将其重写。
- 输出到一个文件:将分区输出文件合并为一个命名的文件。 此路径是数据集文件夹的相对路径。 请注意,合并操作可能会因为节点大小而失败。 对于大型数据集,不建议使用此选项。
全部引用: 确定是否将所有值括在引号中
umask
可以选择使用 POSIX 读取、写入、执行所有者、用户和组的标志来设置 umask 文件。
预处理脚本和后处理命令
可以选择在写入 ADLS Gen2 接收器之前或之后执行 Hadoop 文件系统命令。 支持以下命令:
cpmvrmmkdir
示例:
mkdir /folder1mkdir -p folder1mv /folder1/*.* /folder2/cp /folder1/file1.txt /folder2rm -r /folder1
还能通过表达式生成器支持参数,例如:
mkdir -p {$tempPath}/commands/c1/c2
mv {$tempPath}/commands/*.* {$tempPath}/commands/c1/c2
默认情况下,将以用户/根身份创建文件夹。 请参阅具有“/”的顶级容器。
“查找”活动属性
若要了解有关属性的详细信息,请查看 Lookup 活动。
GetMetadata 活动属性
若要了解有关属性的详细信息,请查看 GetMetadata 活动
Delete 活动属性
若要详细了解这些属性,请查看 Delete 活动
旧模型
注意
仍按原样支持以下模型,以实现向后兼容性。 建议使用上述部分中提到的新模型,ADF 创作 UI 已切换到生成新模型。
旧数据集模型
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | 数据集的 type 属性必须设置为 AzureBlobFSFile。 | 是 |
| folderPath | Data Lake Storage Gen2 中的文件夹的路径。 如果未指定,它指向根目录。 支持通配符筛选器。 允许的通配符为: *(匹配零个或更多字符)和 ?(匹配零个或单个字符)。 如果实际文件夹名内具有通配符或此转义符,请使用 ^ 进行转义。 示例:filesystem/folder/。 请参阅文件夹和文件筛选器示例中的更多示例。 |
否 |
| fileName | 指定的“folderPath”下的文件的“名称或通配符筛选器”。 如果没有为此属性指定任何值,则数据集会指向文件夹中的所有文件。 对于筛选器,允许的通配符为: *(匹配零个或更多字符)和 ?(匹配零个或单个字符)。- 示例 1: "fileName": "*.csv"- 示例 2: "fileName": "???20180427.txt"如果实际文件名内具有通配符或此转义符,请使用 ^ 进行转义。如果没有为输出数据集指定 fileName,并且没有在活动接收器中指定 preserveHierarchy,则复制活动会自动生成采用以下模式的文件名称:“Data.[activity run ID GUID].[GUID if FlattenHierarchy].[format if configured].[compression if configured]”(例如,“Data.0a405f8a-93ff-4c6f-b3be-f69616f1df7a.txt.gz”)。 如果使用表名称而不是查询从表格源进行复制,则名称模式为“[table name].[format].[compression if configured]”,例如“MyTable.csv”。 |
否 |
| modifiedDatetimeStart | 基于属性“上次修改时间”的文件筛选器。 如果文件的上次修改时间大于或等于 modifiedDatetimeStart 并且小于 modifiedDatetimeEnd,则会选择这些文件。 该时间应用于 UTC 时区,格式为“2018-12-01T05:00:00Z”。 当你要从大量文件中进行文件筛选时,启用此设置将影响数据移动的整体性能。 属性可以为 NULL,这意味着不向数据集应用任何文件特性筛选器。 如果 modifiedDatetimeStart 具有日期/时间值,但 modifiedDatetimeEnd 为 NULL,则意味着将选中“上次修改时间”属性大于或等于该日期/时间值的文件。 如果 modifiedDatetimeEnd 具有日期/时间值,但 modifiedDatetimeStart 为 NULL,则意味着将选中“上次修改时间”属性小于该日期/时间值的文件。 |
否 |
| modifiedDatetimeEnd | 基于属性“上次修改时间”的文件筛选器。 如果文件的上次修改时间大于或等于 modifiedDatetimeStart 并且小于 modifiedDatetimeEnd,则会选择这些文件。 该时间应用于 UTC 时区,格式为“2018-12-01T05:00:00Z”。 当你要从大量文件中进行文件筛选时,启用此设置将影响数据移动的整体性能。 属性可以为 NULL,这意味着不向数据集应用任何文件特性筛选器。 如果 modifiedDatetimeStart 具有日期/时间值,但 modifiedDatetimeEnd 为 NULL,则意味着将选中“上次修改时间”属性大于或等于该日期/时间值的文件。 如果 modifiedDatetimeEnd 具有日期/时间值,但 modifiedDatetimeStart 为 NULL,则意味着将选中“上次修改时间”属性小于该日期/时间值的文件。 |
否 |
| format | 若要在基于文件的存储之间按原样复制文件(二进制副本),可以在输入和输出数据集定义中跳过格式节。 若要分析或生成具有特定格式的文件,以下是受支持的文件格式类型:TextFormat、JsonFormat、AvroFormat、OrcFormat 和 ParquetFormat 。 请将 format 中的 type 属性设置为上述值之一。 有关详细信息,请参阅文本格式、JSON 格式、Avro 格式、ORC 格式和 Parquet 格式部分。 |
否(仅适用于二进制复制方案) |
| 压缩 | 指定数据的压缩类型和级别。 有关详细信息,请参阅受支持的文件格式和压缩编解码器。 支持的类型为 **GZip**, **Deflate**, **BZip2**, and **ZipDeflate**。支持的级别为“最佳”和“最快”。 |
否 |
提示
如需复制文件夹下的所有文件,请仅指定 folderPath。
如需复制具有给定名称的单个文件,请使用文件夹部分指定 folderPath 并使用文件名指定 fileName。
若要复制文件夹下的文件子集,请指定带有文件夹部分的 folderPath,以及带有通配符筛选器的 fileName。
示例:
{
"name": "ADLSGen2Dataset",
"properties": {
"type": "AzureBlobFSFile",
"linkedServiceName": {
"referenceName": "<Azure Data Lake Storage Gen2 linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"folderPath": "myfilesystem/myfolder",
"fileName": "*",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
旧复制活动源模型
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | 复制活动源的 type 属性必须设置为 AzureBlobFSSource。 | 是 |
| recursive | 指示是要从子文件夹中以递归方式读取数据,还是只从指定的文件夹中读取数据。 当 recursive 设置为 true 且接收器是基于文件的存储时,将不会在接收器上复制或创建空的文件夹或子文件夹。 允许的值为 true(默认值)和 false。 |
否 |
| maxConcurrentConnections | 活动运行期间与数据存储建立的并发连接的上限。 仅在要限制并发连接时指定一个值。 | 否 |
示例:
"activities":[
{
"name": "CopyFromADLSGen2",
"type": "Copy",
"inputs": [
{
"referenceName": "<ADLS Gen2 input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureBlobFSSource",
"recursive": true
},
"sink": {
"type": "<sink type>"
}
}
}
]
旧复制活动接收器模型
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | 复制活动接收器的 type 属性必须设置为 AzureBlobFSSink。 | 是 |
| copyBehavior | 定义以基于文件的数据存储中的文件为源时的复制行为。 允许值包括: - PreserveHierarchy(默认):将文件层次结构保留到目标文件夹中。 指向源文件夹的源文件相对路径与指向目标文件夹的目标文件相对路径相同。 - FlattenHierarchy:源文件夹中的所有文件都位于目标文件夹的第一级中。 目标文件具有自动生成的名称。 - MergeFiles:将源文件夹中的所有文件合并到一个文件中。 如果指定了文件名,则合并文件的名称为指定名称。 否则,它是自动生成的文件名。 |
否 |
| maxConcurrentConnections | 活动运行期间与数据存储建立的并发连接的上限。 仅在要限制并发连接时指定一个值。 | 否 |
示例:
"activities":[
{
"name": "CopyToADLSGen2",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<ADLS Gen2 output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureBlobFSSink",
"copyBehavior": "PreserveHierarchy"
}
}
}
]
更改数据捕获
Azure 数据工厂只能从 Azure Data Lake Storage Gen2 获取新的或更改后的文件,方法是在映射数据流源转换中启用“启用变更数据捕获”。 使用此连接器选项,可以仅读取新的或更新后的文件,并在将转换后的数据加载到所选目标数据集之前应用转换。
请确保管道和活动名称保持不变,以便始终可以从上次运行中记录检查点,从而从此处获取更改。 如果更改管道名称或活动名称,检查点将重置,并且你将在下一次运行中从头开始。
调试管道时,“启用变更数据捕获”也正常工作。 在调试运行期间刷新浏览器时,检查点将重置。 对调试运行的结果感到满意后,可以发布和触发管道。 无论调试运行记录的上一个检查点是什么,它都将始终从头开始。
在监视部分,你始终有机会重新运行管道。 在这样做时,将始终从所选管道运行中的检查点记录获取更改。
相关内容
有关复制活动支持作为源和接收器的数据存储的列表,请参阅受支持的数据存储。