Data Lakehouse 是一种数据管理系统,它结合了数据湖和数据仓库的优势。 本文介绍 Lakehouse 架构模式及其在 Azure Databricks 上的应用。
Data Lakehouse 用于什么?
Data Lakehouse 为希望避免独立系统处理不同工作负载(如机器学习(ML)和商业智能(BI)的新式组织提供可缩放的存储和处理功能。 Data Lakehouse 可以帮助建立单一事实来源,消除冗余成本,并确保数据新鲜度。
数据湖仓通常使用一种数据设计模式,在数据通过过渡层和转换层时,逐步改进、丰富和优化数据。 湖屋的每一层可以包括一个或多个层。 此模式通常称为奖牌体系结构。 有关详细信息,请参阅 什么是奖牌湖屋体系结构?
Databricks lakehouse 的工作原理是什么?
Databricks 基于 Apache Spark 构建。 Apache Spark 支持在与存储分离的计算资源上运行的大规模可缩放引擎。 有关详细信息,请参阅 Apache Spark 概述
Databricks Lakehouse 使用另外两项关键技术:
- Delta Lake:支持 ACID 事务和架构强制执行的优化存储层。
- Unity Catalog:统一的、细粒度的数据和人工智能治理解决方案。
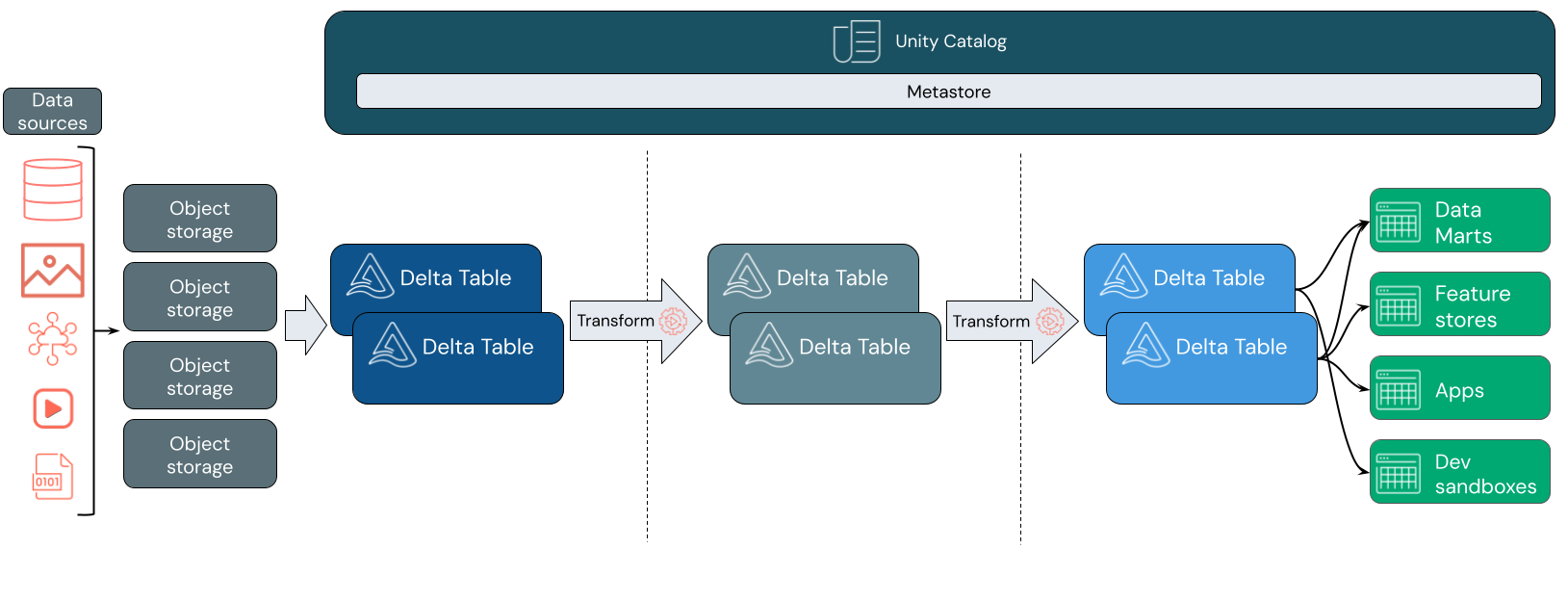
数据引入
在引入层,批处理或流数据从各种源和各种格式到达。 第一个逻辑层为该数据提供一个以原始格式登陆的位置。 将这些文件转换为 Delta 表时,可以使用 Delta Lake 的架构强制功能来检查缺失或意外的数据。 可以使用 Unity 目录根据数据治理模型和所需的数据隔离边界来注册表。 Unity 目录允许跟踪数据的世系,因为它经过转换和优化,并应用统一的治理模型来保持敏感数据的私密性和安全性。
数据处理、策展和集成
验证后,可以开始策划和优化数据。 数据科学家和机器学习从业者经常在此阶段处理数据,开始组合或创建新功能和完成数据清理。 彻底清理数据后,可以将其集成并重新组织到旨在满足特定业务需求的表中。
写入架构方法与 Delta 架构演变功能相结合,这意味着你可以对此层进行更改,而无需重写为最终用户提供数据的下游逻辑。
数据服务
最后一层为最终用户提供干净、扩充的数据。 最终表应设计为为所有用例提供数据。 统一的治理模型意味着可以将数据世系跟踪回单一事实来源。 针对不同任务进行优化的数据布局允许最终用户访问机器学习应用程序、数据工程和商业智能和报告的数据。
若要了解有关 Delta Lake 的详细信息,请参阅 什么是 Azure Databricks 中的 Delta Lake? 若要了解有关 Unity 目录的详细信息,请参阅 什么是 Unity 目录?
Databricks lakehouse 的功能
基于 Databricks 构建的 Lakehouse 取代了现代数据公司的对数据湖和数据仓库的当前依赖关系。 可执行的一些关键任务包括:
- 实时数据处理: 实时处理流数据,以便立即进行分析和采取行动。
- 数据集成: 在单个系统中统一数据,以启用协作并为组织建立单一事实来源。
- 架构演变: 随着时间的推移,修改数据架构以适应不断变化的业务需求,而不会中断现有的数据管道。
- 数据转换: 使用 Apache Spark 和 Delta Lake 可提高数据的速度、可伸缩性和可靠性。
- 数据分析和报告: 使用针对数据仓库工作负荷优化的引擎运行复杂的分析查询。
- 机器学习和 AI: 将高级分析技术应用于所有数据。 使用 ML 丰富数据并支持其他工作负载。
- 数据版本控制与世系: 维护数据集的版本历史记录并跟踪世系,以确保数据来源和可跟踪性。
- 数据管理: 使用单个统一的系统来控制对数据的访问和执行审核。
- 数据共享: 通过允许跨团队共享特选数据集、报表和见解,促进协作。
- 运营分析: 使用数据质量监控来监测数据质量指标、模型质量指标和漂移。
Lakehouse vs Data Lake 与数据仓库
数据仓库为商业智能(BI)决策提供支持约 30 年,已演变为控制数据流的系统设计准则。 企业数据仓库优化 BI 报表的查询,但生成结果可能需要几分钟甚至数小时。 数据仓库旨在防止并发运行的查询之间的冲突,专为不太可能以高频率变化的数据而设计。 许多数据仓库依赖于专有格式,这些格式通常限制对机器学习的支持。 Azure Databricks 上的数据仓库利用 Databricks lakehouse 和 Databricks SQL 的功能。 有关详细信息,请参阅 Azure Databricks 上的数据仓库。
数据湖由数据存储的技术进步以及数据类型和数量指数增长所推动,在过去十年中,数据湖已广泛使用。 数据湖以低成本和高效的方式存储和处理数据。 数据湖常被定义为与数据仓库相对立:数据仓库为 BI 分析提供清理过的结构化数据,而数据湖则永久且低成本地存储任何格式与性质的数据。 许多组织使用数据湖进行数据科学和机器学习,但由于其未经验证的性质,数据湖不用于 BI 报告。
数据湖仓结合了数据湖和数据仓库的优势,并且提供:
- 打开、直接访问以标准数据格式存储的数据。
- 为机器学习和数据科学优化的索引协议。
- BI 和高级分析的查询延迟低和可靠性高。
通过将优化元数据层与以标准格式存储在云对象存储中的经过验证的数据相结合,Data Lakehouse 允许你从同一数据以及跨不同用例在同一平台中工作。
后续步骤
若要详细了解如何使用 Databricks 实现和运营 Lakehouse 的原则和最佳做法,请参阅 设计良好的 Data Lakehouse 简介