Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Important
Azure SQL Edge will be retired on September 30, 2025. For more information and migration options, see the Retirement notice.
Note
Azure SQL Edge no longer supports the ARM64 platform.
After the data retention policy is defined for a database and the underlying table, a background time timer task runs to remove any obsolete records from the table enabled for data retention. Identification of matching rows and their removal from the table occur transparently, in the background task scheduled and run by the system. Age condition for the table rows is checked based on the filter_column column specified in the table definition. If retention period is set to one week, for instance, table rows eligible for cleanup satisfy either of the following condition:
- If the filter column uses DATETIMEOFFSET data type, then the condition is
filter_column < DATEADD(WEEK, -1, SYSUTCDATETIME()) - Otherwise, the condition is
filter_column < DATEADD(WEEK, -1, SYSDATETIME())
Data retention cleanup phases
The data retention cleanup operation consists of two phases:
- Discovery: In this phase, the cleanup operation identifies all the tables within the user databases to build a list for cleanup. Discovery runs once a day.
- Cleanup: In this phase, cleanup is run against all tables with finite data retention, identified in the discovery phase. If the cleanup operation can't be performed on a table, then that table is skipped in the current run and will be retried in the next iteration. The following principles are used during cleanup:
- If an obsolete row is locked by another transaction, that row is skipped.
- Cleanup runs with a default lock timeout of 5 seconds. If the locks can't be acquired on the tables within the timeout window, the table is skipped in the current run and will be retried in the next iteration.
- If there's an error during cleanup of a table, that table is skipped and will be picked up in the next iteration.
Manual cleanup
Depending on the data retention settings on a table and the nature of the workload on the database, it's possible that the automatic cleanup thread may not completely remove all obsolete rows during its run. To allow users to manually remove obsolete rows, the sys.sp_cleanup_data_retention stored procedure has been introduced in Azure SQL Edge.
This stored procedure takes three parameters:
@schema_name: Name of the owning schema for the table. Required.@table_name: Name of the table for which manual cleanup is being run. Required.@rowcount: Output variable. Returns the number of rows cleaned up by the manual cleanup sp. Optional.
For more information, see sys.sp_cleanup_data_retention (Transact-SQL).
The following example shows the execution of the manual cleanup sp for table dbo.data_retention_table.
DECLARE @rowcnt BIGINT;
EXEC sys.sp_cleanup_data_retention 'dbo', 'data_retention_table', @rowcnt OUTPUT;
SELECT @rowcnt;
How obsolete rows are deleted
The cleanup process depends on the index layout of the table. A background task is created to perform obsolete data cleanup for all tables with finite retention period. Clean up logic for the rowstore (heap or B-tree) index deletes aged row in smaller chunks (up to 10,000), minimizing pressure on database log and the I/O subsystem. Although cleanup logic utilizes the required B-tree index, the order of deletions for the rows older than retention period can't be firmly guaranteed. In other words, don't take a dependency on the cleanup order in your applications.
Warning
In the case of heaps and B-tree indexes, data retention runs a delete query on the underlying tables, which can conflict with delete triggers on the tables. You should either remove delete triggers from the tables, or avoid using data retention on tables that have delete DML triggers.
The cleanup task for the clustered columnstore indexes removes entire row groups at once (typically contain 1 million of rows each), which is efficient, especially when data is generated and ages out at a high pace.
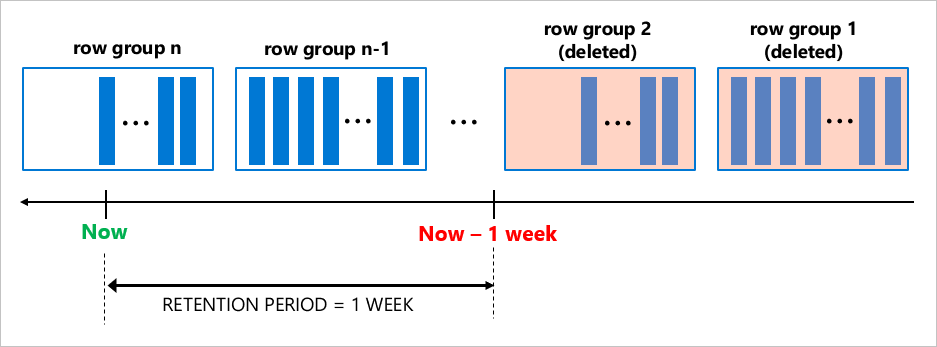
Excellent data compression and efficient retention cleanup makes clustered columnstore indexes a perfect choice for scenarios when your workload rapidly generates a large amount of data.
Monitor data retention cleanup
Data retention policy cleanup operations can be monitored using Extended Events in Azure SQL Edge. For more information on extended events, see Extended Events Overview.
The following Extended Events help track the state of the cleanup operations.
| Name | Description |
|---|---|
| data_retention_task_started | Occurs when the background task for cleanup of tables with a retention policy starts. |
| data_retention_task_completed | Occurs when the background task for cleanup of tables with a retention policy ends. |
| data_retention_task_exception | Occurs when the background task for cleanup of tables with a retention policy fails, outside of retention cleanup process specific to those tables. |
| data_retention_cleanup_started | Occurs when the cleanup process of a table with data retention policy starts. |
| data_retention_cleanup_exception | Occurs when the cleanup process of a table with retention policy fails. |
| data_retention_cleanup_completed | Occurs when the cleanup process of a table with data retention policy ends. |
Additionally, a new ring buffer type named RING_BUFFER_DATA_RETENTION_CLEANUP has been added to the sys.dm_os_ring_buffers dynamic management view. This view can be used to monitor the data retention cleanup operations.