Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Applies to: ![]() Azure SQL Database
Azure SQL Database
Azure SQL Database provides an enterprise class availability SLA to support a wide variety of applications, including mission critical, that always need to be available. Azure SQL Database also has turn key business continuity capabilities that you can perform for quick disaster recovery in the event of a regional outage. This article contains valuable information to review in advance of application deployment.
Though we continuously strive to provide availability, there are times when the Azure SQL Database service incurs outages that cause the unavailability of your database and thus impacts your application. When our service monitoring detects issues that cause widespread connectivity errors, failures or performance issues, the service automatically declares an outage to keep you informed.
Service outage
In the event of an Azure SQL Database service outage, you can find additional details related to the outage in the following places:
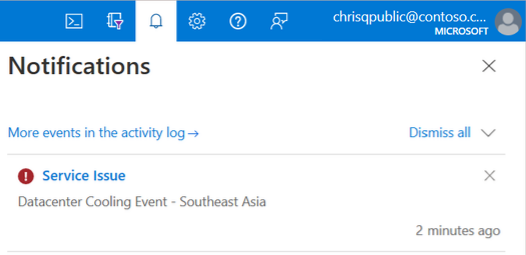
Azure portal banner
If your subscription is identified as impacted, there's an outage alert of a Service Issue in your Azure portal Notifications:
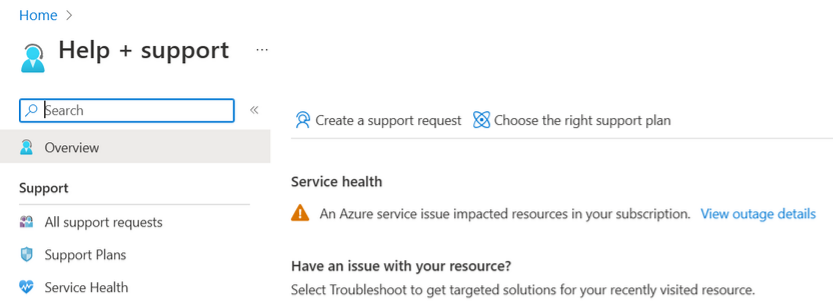
Help + support or Support + troubleshooting
When you create a support ticket from Help + support or Support + troubleshooting, there's information about any issues impacting your resources. Select View outage details for more information and a summary of impact. There's also an alert in the New support request page.
Service health
The Service Health page in the Azure portal contains information about Azure data center status globally. Search for `service health`` in the search bar in the Azure portal, then view Service issues in the Active events category. You can also view the health of individual resources in the Resource health page of any resource under the Help menu.
Email notification
If you have set up alerts, an email notification is sent from
azure-noreply@microsoft.comwhen a service outage impacts your subscription and resource. The body of the email typically begins with "The activity log alert ... was triggered by a service issue for the Azure subscription...". For more information on service health alerts, see Receive activity log alerts on Azure service notifications using Azure portal.

When to initiate disaster recovery during an outage
In the event of a service outage impacting application resources, consider the following courses of action:
The Azure teams work diligently to restore service availability as quickly as possible but depending on the root cause it can sometimes take hours. If your application can tolerate significant downtime, you can simply wait for the recovery to complete. In this case, no action on your part is required. View the health of individual resources in the Resource health page of any resource under the Help menu. Refer to the Resource health page for updates and the latest information regarding an outage. After the recovery of the region, your application's availability is restored.
Recovery to another Azure region can require changing application connection strings or using DNS redirection, and might result in permanent data loss. Therefore, disaster recovery should be performed only when the outage duration approaches your application's recovery time objective (RTO). When the application is deployed to production, you should perform regular monitoring of the application's health and assert that the recovery is warranted only when there's prolonged connectivity failure from the application tier to the database. Depending on your application tolerance to downtime and possible business liability, you can decide if you want to wait for service to recover or initiate disaster recovery yourself.
Outage recovery guidance
If the Azure SQL Database outage in a region hasn't been mitigated for an extended period of time and is affecting your application's service-level agreement (SLA), consider the following steps:
Failover (no data loss) to geo-replicated secondary server
If active geo-replication or failover groups are enabled, check if the primary and secondary database resource status is Online in the Azure portal. If so, the data plane for both primary and secondary database is healthy. Initiate a failover of active geo-replication or failover groups to the secondary region by using the Azure portal, T-SQL, PowerShell, or Azure CLI.
Note
A failover requires full data synchronization before switching roles and does not result in data loss. Depending on the type of service outage there is no guarantee that failover without data loss will succeed, but it is worth trying as the first recovery option.
To initiate a failover, use the following links:
| Technology | Method | Steps |
|---|---|---|
| Active geo-replication | PowerShell | Failover to geo-replication secondary via PowerShell |
| T-SQL | Failover to geo-replication secondary via T-SQL | |
| Failover groups | Azure CLI | Failover to secondary server via Azure CLI |
| Azure portal | Failover to secondary server via Azure portal | |
| PowerShell | Failover to secondary server via PowerShell |
Forced failover (potential data loss) to geo-replicated secondary server
If failover doesn't complete gracefully and experiences errors, or if the primary database status is not Online, carefully consider forced failover with potential data loss to the secondary region.
To initiate a forced failover, use the following links:
| Technology | Method | Steps |
|---|---|---|
| Active geo-replication | Azure CLI | Forced failover to geo-replication secondary via Azure CLI |
| Azure portal | Forced failover to geo-replication secondary via the Azure portal | |
| PowerShell | Forced failover to geo-replication secondary via PowerShell | |
| T-SQL | Forced failover to geo-replication secondary via T-SQL | |
| Failover groups | Azure portal | Forced failover to secondary server via Azure portal but choose Forced Failover. |
| Azure CLI | Forced failover to secondary server via Azure CLI but use --allow-data-loss |
|
| PowerShell | Forced failover to secondary server via PowerShell but use -AllowDataLoss |
Geo-restore
If you haven't enabled active geo-replication or failover groups, then as a last resort, you can use geo-restore to recover from an outage. Geo-restore uses geo-replicated backups as the source. You can restore a database on any logical server in any Azure region from the most recent geo-replicated backups. You can request a geo-restore even if an outage has made the database or the entire region inaccessible.
For more information on geo-restores via Azure CLI, the Azure portal, PowerShell, or the REST API, see geo-restore of Azure SQL Database.
Configure your database after recovery
If you're using geo-failover or geo-restore to recover from an outage, you must make sure that the connectivity to the new database is properly configured so that the normal application function can be resumed. This is a checklist of tasks to get your recovered database production ready.
Important
It is recommended to conduct periodic drills of your disaster recovery strategy to verify application tolerance, as well as all operational aspects of the recovery procedure. The other layers of your application infrastructure might require reconfiguration. For more information on resilient architecture steps, review the Azure SQL Database high availability and disaster recovery checklist.
Update connection strings
- If you're using active geo-replication or geo-restore, you must make sure that the connectivity to the new databases is properly configured so that the normal application function can be resumed. Because your recovered database resides in a different server, you need to update your application's connection string to point to that server. For more information about changing connection strings, see the appropriate development language for your connection library.
- If you're using failover groups to recover from an outage and use read-write and read-only listeners in your application connection strings, then no further action is needed as connections are automatically directed to new primary.
Configure firewall rules
You need to make sure that the firewall rules configured on the secondary server and database match those that were configured on the primary server and primary database. For more information, see How to: Configure Firewall Settings.
Configure logins and database users
Create the logins that must be present in the master database on the new primary server, and ensure these logins have appropriate permissions in the master database, if any. For more information, see security after disaster recovery.
Setup telemetry alerts
You need to make sure your existing alert rule settings are updated to map to the new primary database and the different server. For more information about database alert rules, see Receive Alert Notifications and Track Service Health.
Enable auditing
If you have auditing configured on the primary server, make it identical on the secondary server. For more information, see Auditing.
Related content
To learn more, review:
- Continuity scenarios.
- Automated backups
- Restore a database from the service-initiated backups.
- To learn about faster recovery options, see Active geo-replication and Failover groups.
- Review disaster recovery guidance and the high availability and disaster recovery checklist.