Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Applies to: ![]() Azure SQL Database
Azure SQL Database
Azure SQL Database elastic pools are a simple, cost-effective solution for managing and scaling multiple databases with varying and unpredictable usage demands. The databases in an elastic pool are on a single server and share a set number of resources at a set price. Elastic pools in SQL Database enable software-as-a-service (SaaS) developers to optimize the price performance for a group of databases within a prescribed budget while delivering performance elasticity for each database.
What are SQL elastic pools?
SaaS developers build applications on top of large-scale data tiers with multiple databases. A typical application pattern is to provision a single database for each customer. However, different customers often have varying and unpredictable usage patterns, and it's difficult to predict the resource requirements of each database user. Traditionally, you had two options:
- Overprovision resources based on peak usage and overpay.
- Underprovision to save cost at the expense of performance and customer satisfaction during peaks.
Elastic pools solve this problem by ensuring that databases get the performance resources they need when they need them. They provide a simple resource allocation mechanism within a predictable budget.
Important
There's no per-database charge for elastic pools. You're billed for each hour a pool exists at the highest eDTU or vCores, regardless of usage or whether the pool was active for less than an hour.
Elastic pools enable you to purchase resources for a pool shared by multiple databases to accommodate unpredictable usage periods by individual databases. You can configure resources for the pool based either on the DTU-based purchasing model or the vCore-based purchasing model. The aggregate utilization of its databases determines the resource requirement for a pool.
Your budget controls the resources available to the pool. All you have to do is:
- Add databases to the pool.
- Optionally set the minimum and maximum resources for the databases, in either DTU or vCore purchasing model.
- Set the resources of the pool based on your budget.
You can use pools to seamlessly grow your service from a lean startup to a mature business at an ever-increasing scale.
Within the pool, individual databases have the flexibility to use resources within set parameters. Under heavy load, a database can consume more resources to meet demand. Databases under light loads consume less, and databases under no load consume no resources. Provisioning resources for the entire pool rather than for single databases simplifies your management tasks. Plus, you have a predictable budget for the pool.
More resources can be added to an existing pool with minimum downtime. If extra resources are no longer needed, they can be removed from an existing pool anytime. You can also add or remove databases from the pool. If a database is predictably underutilizing resources, you can move it out.
Note
When you move databases into or out of an elastic pool, there's no downtime except for a brief period (on the order of seconds) when database connections are dropped at the end of the operation.
When to consider a SQL Database elastic pool?
Pools are well suited for a large number of databases with specific utilization patterns. This pattern is characterized by low average utilization with infrequent utilization spikes for a given database. Conversely, multiple databases with persistent medium-high utilization shouldn't be placed in the same elastic pool.
The more databases you can add to a pool, the greater your savings. Depending on your application utilization pattern, it's possible to see savings with as few as two S3 databases.
The following sections help you understand how to assess if your specific collection of databases can benefit from being in a pool. The examples use Standard pools, but the same principles apply to elastic pools in other service tiers.
Assess database utilization patterns
The following figure shows an example of a database that spends much of its idle time but periodically spikes with activity. This utilization pattern is suited for a pool.
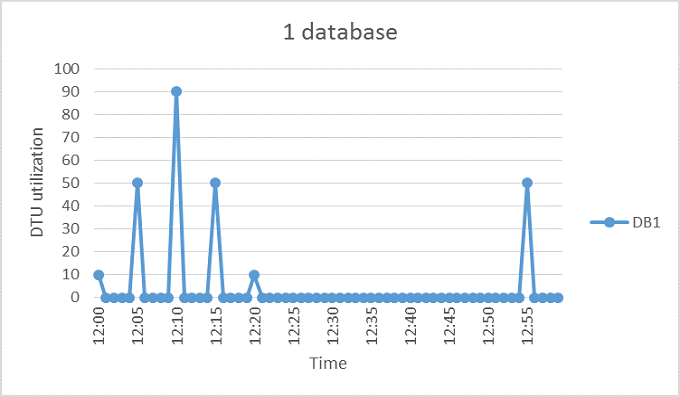
The chart illustrates DTU usage over one hour from 12:00 to 1:00 where each data point has one-minute granularity. At 12:10, DB1 peaks up to 90 DTUs, but its overall average usage is fewer than five DTUs. An S3 compute size is required to run this workload in a single database, but this size leaves most resources unused during periods of low activity.
A pool allows these unused DTUs to be shared across multiple databases. A pool reduces the DTUs needed and the overall cost.
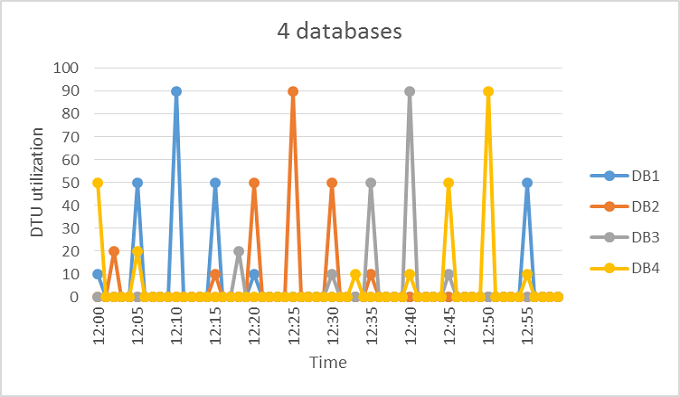
Building on the previous example, suppose other databases have similar utilization patterns as DB1. In the following two figures, the utilization of 4 databases and 20 databases are layered onto the same graph to illustrate the nonoverlapping nature of their utilization over time by using the DTU-based purchasing model:
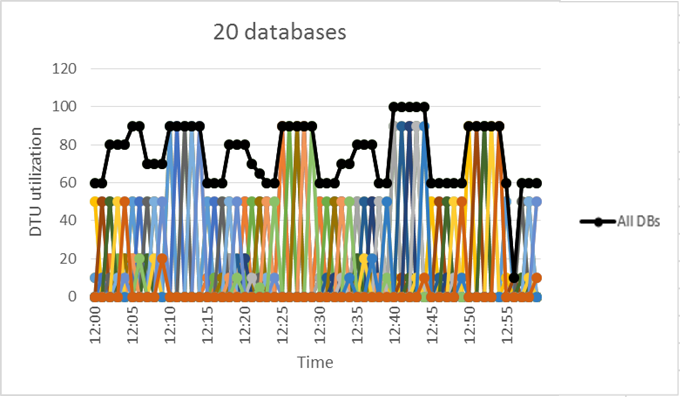
The black line in the preceding chart illustrates the aggregate DTU utilization across all 20 databases. This line shows that the aggregate DTU utilization never exceeds 100 DTUs and indicates that the 20 databases can share 100 eDTUs over this period. The result is a 20-time reduction in DTUs and a 13-time price reduction compared to placing each database in S3 compute sizes for single databases.
This example is ideal because:
- There are large differences between peak utilization and average utilization per database.
- The peak utilization for each database occurs at different points in time.
- eDTUs are shared between many databases.
In the DTU purchasing model, the price of a pool is a function of the pool eDTUs. While the eDTU unit price for a pool is 1.5 times greater than the DTU unit price for a single database, pool eDTUs can be shared by many databases, and fewer total eDTUs are needed. These distinctions in pricing and eDTU sharing are the basis of the price savings potential that pools can provide.
In the vCore purchasing model, the vCore unit price for elastic pools is the same as the vCore unit price for single databases.
How do I choose the correct pool size?
The best size for a pool depends on the aggregate resources needed for all databases in the pool. You need to determine:
- Maximum compute resources utilized by all databases in the pool. Compute resources are indexed by either eDTUs or vCores, depending on your choice of purchasing model.
- Maximum storage bytes utilized by all databases in the pool.
For service tiers and resource limits in each purchasing model, see the DTU-based purchasing model or the vCore-based purchasing model.
The following steps can help you estimate whether a pool is more cost-effective than single databases:
Estimate the eDTUs or vCores needed for the pool:
- For the DTU-based purchasing model:
- MAX(<Total number of DBs × Average DTU utilization per DB>, <Number of concurrently peaking DBs × Peak DTU utilization per DB>)
- For the vCore-based purchasing model:
- MAX(<Total number of DBs × Average vCore utilization per DB>, <Number of concurrently peaking DBs × Peak vCore utilization per DB>)
- For the DTU-based purchasing model:
Estimate the total storage space needed for the pool by adding the data size needed for all the databases in the pool. For the DTU purchasing model, determine the eDTU pool size that provides this amount of storage.
For the DTU-based purchasing model, take the larger of the eDTU estimates from step 1 and step 2.
- For the vCore-based purchasing model, take the vCore estimate from step 1.
See the SQL Database pricing page.
- Find the smallest pool size greater than the estimate from step 3.
Compare the pool price from step 4 to using the appropriate compute sizes for single databases.
Important
If the number of databases in a pool approaches the maximum supported, make sure to consider resource management in dense elastic pools.
Per-database properties
Optionally set per-database properties to modify resource consumption patterns in elastic pools. For more information, see resource limits documentation for DTU and vCore elastic pools.
Use other SQL Database features with elastic pools
You can use other SQL Database features with elastic pools.
Elastic jobs and elastic pools
With a pool, management tasks are simplified by running scripts in elastic jobs. An elastic job eliminates most of the tedium associated with large numbers of databases.
For more information about other database tools for working with multiple databases, see Scale out with Azure SQL Database.
Hyperscale elastic pools
Hyperscale elastic pools overview in Azure SQL Database are generally available.
Read-only scale out instances
You cannot use read-only scale out instances of Azure SQL Database with elastic query.
Business continuity options for databases in an elastic pool
Pooled databases generally support the same business-continuity features that are available to single databases:
- Point-in-time restore: Point-in-time restore uses automatic database backups to recover a database in a pool to a specific point in time. See Point-in-time restore.
- Geo-restore: Geo-restore provides the default recovery option when a database is unavailable because of an incident in the region where the database is hosted. See Geo-restore.
- Active geo-replication: For applications that have more aggressive recovery requirements than geo-restore can offer, configure active geo-replication or a failover group.
For more information on the above strategies, see Disaster recovery guidance - Azure SQL Database.
Create a new SQL Database elastic pool by using the Azure portal
You can create an elastic pool in the Azure portal in two ways:
- Create an elastic pool and select an existing or new server.
- Create an elastic pool from an existing server.
To create an elastic pool and select an existing or new server:
Go to Azure SQL hub.
In the resource menu, expand Azure SQL Database and select Elastic pools.
In the toolbar, select + Create.
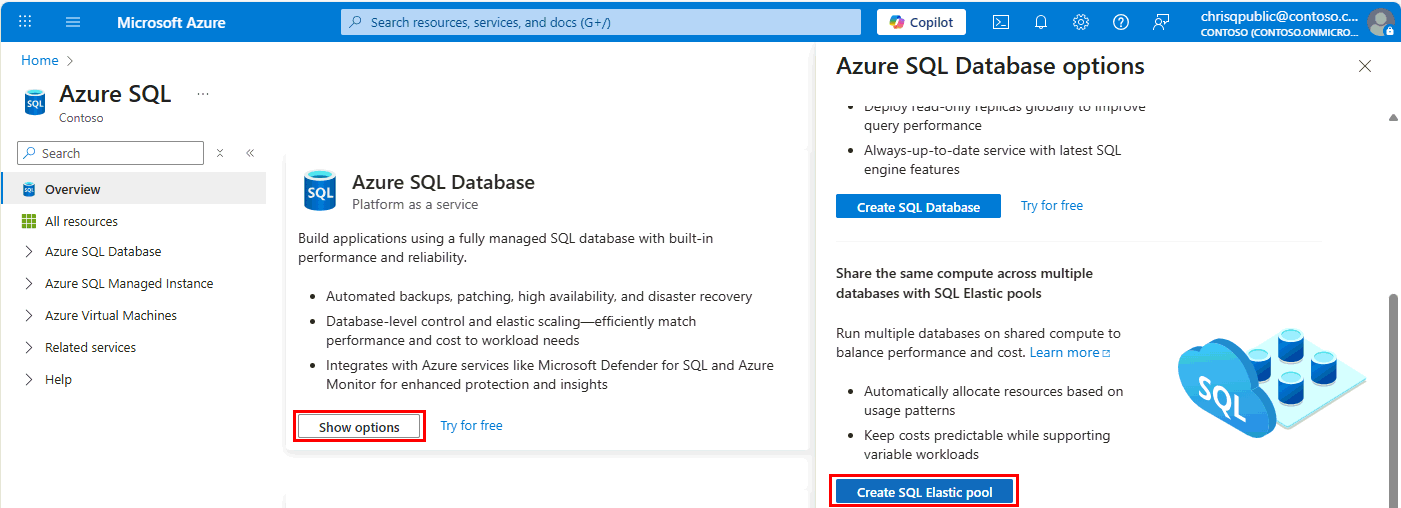
Choose a Subscription, Resource group, Elastic Pool Name, and a host logical Server, which can be an existing or new server.
To configure the resources and pricing of the pool, select Configure pool. Then select a service tier, add databases to the pool, and configure the resource limits for the pool and its databases.
After configuring the pool, select Apply, name the pool, and select OK to create the pool.
Then, manage your elastic pool via the Azure portal, PowerShell, Azure CLI, REST API, or T-SQL.

To create an elastic pool from an existing server:
Go to an existing server and select New pool to create a pool directly in that server.
Note
You can create multiple pools on a server, but you can't add databases from different servers into the same pool.
The pool's service tier determines the features available to the elastics in the pool, and the maximum amount of resources available to each database. For more information, see resource limits for elastic pools in the DTU model. For vCore-based resource limits for elastic pools, see vCore-based resource limits - elastic pools.
To configure the resources and pricing of the pool, select Configure pool. Then select a service tier, add databases to the pool, and configure the resource limits for the pool and its databases.
After configuring the pool, select Apply, name the pool, and select OK to create the pool.
Then, manage your elastic pool via the Azure portal, PowerShell, Azure CLI, REST API, or T-SQL.
Monitor an elastic pool and its databases
In the Azure portal, you can monitor the utilization of an elastic pool and the databases within that pool. You can also make a set of changes to your elastic pool and submit all changes at the same time. These changes include adding or removing databases, changing your elastic pool settings, or changing your database settings.
You can use the built-in performance monitoring and alerting tools combined with performance ratings. SQL Database can also emit metrics and resource logs for easier monitoring.
Related content
- For pricing information, see Elastic pool pricing.
- To scale elastic pools, see Scale elastic pools and Scale an elastic pool - sample code.
- Learn how to manage elastic pools in Azure SQL Database.
- To learn about resource management in elastic pools with many databases, see Resource management in dense elastic pools.
- Learn more about Hyperscale elastic pools.