Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Azure Cosmos DB offers various options to enable large-scale analytics and BI reporting on your operational data.
To get meaningful insights on your Azure Cosmos DB data, you may need to query with aggregate functions such as sum, count, etc., across multiple databases and collections in Cosmos DB and possibly query against other data sources such as Azure SQL Database, or a lakehouse. Such queries need heavy computational power, which likely consumes more request units (RUs) and as a result, these queries might potentially affect your mission critical workload performance.
To isolate transactional workloads from the performance impact of complex analytical queries, as well as help to combine that data with other sources of data in your organization, Azure Cosmos DB and Microsoft Fabric address these challenges by providing zero ETL, cost-effective analytics offerings with Azure Cosmos DB Mirroring and Cosmos DB in Microsoft Fabric.
Important
Synapse Link for Cosmos DB is no longer supported for new projects. Don't use this feature.
Please use Azure Cosmos DB Mirroring for Microsoft Fabric which is now GA. Mirroring provides the same zero-ETL benefits and is fully integrated with Microsoft Fabric.
Option 1: Mirroring your Azure Cosmos DB data into Microsoft Fabric
Mirroring in Microsoft Fabric provides a seamless no-ETL experience to integrate your existing Azure Cosmos DB data with the rest of your data in Microsoft Fabric for true Hybrid Transactional/Analytical Processing (HTAP) with complete workload isolation between transactional and analytical systems. Your Azure Cosmos DB data is continuously replicated directly into Fabric OneLake in near real-time, without any performance impact on your transactional workloads or consuming Request Units (RUs).
Data in OneLake is stored in the open-source delta format and automatically made available to all analytical engines on Fabric.
You can use built-in Power BI capabilities to access data in OneLake in DirectLake mode. With Copilot enhancements in Fabric, you can use the power of generative AI to get key insights on your business data. In addition to Power BI, you can use T-SQL to run complex aggregate queries or use Spark for data exploration. You can seamlessly access the data in notebooks and use data science to build machine learning models.
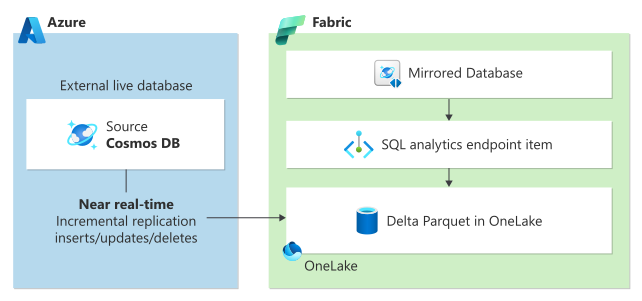
To get started with mirroring, visit "Get started with mirroring tutorial".
Option 2: Azure Cosmos DB in Fabric
Cosmos DB in Microsoft Fabric is an AI-optimized NoSQL database with a simplified management experience. As a developer, you can use Cosmos DB in Fabric to build AI applications with less friction and without having to take on typical database management tasks. As an analytics user, Cosmos DB can be used as a low-latency serving layer, making reports faster and able to serve thousands of users simultaneously.
Cosmos DB in Microsoft Fabric uses the same engine, same infrastructure as Azure Cosmos DB for NoSQL, but is tightly integrated into Fabric. Cosmos DB provides a schemaless data model ideal for semi-structured data or evolving data models; offering limitless, automatic, and instantaneous scaling, with low latency and built-in high availability.