How to ingest data using pg_azure_storage in Azure Cosmos DB for PostgreSQL
APPLIES TO:
![]() Azure Cosmos DB for PostgreSQL (powered by the Citus database
extension to PostgreSQL)
Azure Cosmos DB for PostgreSQL (powered by the Citus database
extension to PostgreSQL)
This article shows how to use the pg_azure_storage PostgreSQL extension to manipulate and load data into your Azure Cosmos DB for PostgreSQL directly from Azure Blob Storage (ABS). ABS is a cloud-native scalable, durable and secure storage service. These characteristics make it a good choice of storing and moving existing data into the cloud.
Prepare database and blob storage
To load data from Azure Blob Storage, install the pg_azure_storage PostgreSQL extension in your database:
SELECT * FROM create_extension('azure_storage');
Important
The pg_azure_storage extension is available only on Azure Cosmos DB for PostgreSQL clusters running PostgreSQL 13 and above.
We've prepared a public demonstration dataset for this article. To use your own dataset, follow migrate your on-premises data to cloud storage to learn how to get your datasets efficiently into Azure Blob Storage.
Note
Selecting "Container (anonymous read access for containers and blobs)" will allow you to ingest files from Azure Blob Storage using their public URLs and enumerating the container contents without the need to configure an account key in pg_azure_storage. Containers set to access level "Private (no anonymous access)" or "Blob (anonymous read access for blobs only)" will require an access key.
List container contents
There's a demonstration Azure Blob Storage account and container pre-created for this how-to. The container's name is github, and it's in the pgquickstart account. We can easily see which files are present in the container by using the azure_storage.blob_list(account, container) function.
SELECT path, bytes, pg_size_pretty(bytes), content_type
FROM azure_storage.blob_list('pgquickstart','github');
-[ RECORD 1 ]--+-------------------
path | events.csv.gz
bytes | 41691786
pg_size_pretty | 40 MB
content_type | application/x-gzip
-[ RECORD 2 ]--+-------------------
path | users.csv.gz
bytes | 5382831
pg_size_pretty | 5257 kB
content_type | application/x-gzip
You can filter the output either by using a regular SQL WHERE clause, or by using the prefix parameter of the blob_list UDF. The latter filters the returned rows on the Azure Blob Storage side.
Note
Listing container contents requires an account and access key or a container with enabled anonymous access.
SELECT * FROM azure_storage.blob_list('pgquickstart','github','e');
-[ RECORD 1 ]----+---------------------------------
path | events.csv.gz
bytes | 41691786
last_modified | 2022-10-12 18:49:51+00
etag | 0x8DAAC828B970928
content_type | application/x-gzip
content_encoding |
content_hash | 473b6ad25b7c88ff6e0a628889466aed
SELECT *
FROM azure_storage.blob_list('pgquickstart','github')
WHERE path LIKE 'e%';
-[ RECORD 1 ]----+---------------------------------
path | events.csv.gz
bytes | 41691786
last_modified | 2022-10-12 18:49:51+00
etag | 0x8DAAC828B970928
content_type | application/x-gzip
content_encoding |
content_hash | 473b6ad25b7c88ff6e0a628889466aed
Load data from ABS
Load data with the COPY command
Start by creating a sample schema.
CREATE TABLE github_users
(
user_id bigint,
url text,
login text,
avatar_url text,
gravatar_id text,
display_login text
);
CREATE TABLE github_events
(
event_id bigint,
event_type text,
event_public boolean,
repo_id bigint,
payload jsonb,
repo jsonb,
user_id bigint,
org jsonb,
created_at timestamp
);
CREATE INDEX event_type_index ON github_events (event_type);
CREATE INDEX payload_index ON github_events USING GIN (payload jsonb_path_ops);
SELECT create_distributed_table('github_users', 'user_id');
SELECT create_distributed_table('github_events', 'user_id');
Loading data into the tables becomes as simple as calling the COPY command.
-- download users and store in table
COPY github_users
FROM 'https://pgquickstart.blob.core.chinacloudapi.cn/github/users.csv.gz';
-- download events and store in table
COPY github_events
FROM 'https://pgquickstart.blob.core.chinacloudapi.cn/github/events.csv.gz';
Notice how the extension recognized that the URLs provided to the copy command are from Azure Blob Storage, the files we pointed were gzip compressed and that was also automatically handled for us.
The COPY command supports more parameters and formats. In the above example, the format and compression were auto-selected based on the file extensions. You can however provide the format directly similar to the regular COPY command.
COPY github_users
FROM 'https://pgquickstart.blob.core.chinacloudapi.cn/github/users.csv.gz'
WITH (FORMAT 'csv');
Currently the extension supports the following file formats:
| format | description |
|---|---|
| csv | Comma-separated values format used by PostgreSQL COPY |
| tsv | Tab-separated values, the default PostgreSQL COPY format |
| binary | Binary PostgreSQL COPY format |
| text | A file containing a single text value (for example, large JSON or XML) |
Load data with blob_get()
The COPY command is convenient, but limited in flexibility. Internally COPY uses the blob_get function, which you can use directly to manipulate data in more complex scenarios.
SELECT *
FROM azure_storage.blob_get(
'pgquickstart', 'github',
'users.csv.gz', NULL::github_users
)
LIMIT 3;
-[ RECORD 1 ]-+--------------------------------------------
user_id | 21
url | https://api.github.com/users/technoweenie
login | technoweenie
avatar_url | https://avatars.githubusercontent.com/u/21?
gravatar_id |
display_login | technoweenie
-[ RECORD 2 ]-+--------------------------------------------
user_id | 22
url | https://api.github.com/users/macournoyer
login | macournoyer
avatar_url | https://avatars.githubusercontent.com/u/22?
gravatar_id |
display_login | macournoyer
-[ RECORD 3 ]-+--------------------------------------------
user_id | 38
url | https://api.github.com/users/atmos
login | atmos
avatar_url | https://avatars.githubusercontent.com/u/38?
gravatar_id |
display_login | atmos
Note
In the above query, the file is fully fetched before LIMIT 3 is applied.
With this function, you can manipulate data on the fly in complex queries, and do imports as INSERT FROM SELECT.
INSERT INTO github_users
SELECT user_id, url, UPPER(login), avatar_url, gravatar_id, display_login
FROM azure_storage.blob_get('pgquickstart', 'github', 'users.csv.gz', NULL::github_users)
WHERE gravatar_id IS NOT NULL;
INSERT 0 264308
In the above command, we filtered the data to accounts with a gravatar_id present and upper cased their logins on the fly.
Options for blob_get()
In some situations, you may need to control exactly what blob_get attempts to do by using the decoder, compression and options parameters.
Decoder can be set to auto (default) or any of the following values:
| format | description |
|---|---|
| csv | Comma-separated values format used by PostgreSQL COPY |
| tsv | Tab-separated values, the default PostgreSQL COPY format |
| binary | Binary PostgreSQL COPY format |
| text | A file containing a single text value (for example, large JSON or XML) |
compression can be either auto (default), none or gzip.
Finally, the options parameter is of type jsonb. There are four utility functions that help building values for it.
Each utility function is designated for the decoder matching its name.
| decoder | options function |
|---|---|
| csv | options_csv_get |
| tsv | options_tsv |
| binary | options_binary |
| text | options_copy |
By looking at the function definitions, you can see which parameters are supported by which decoder.
options_csv_get - delimiter, null_string, header, quote, escape, force_not_null, force_null, content_encoding
options_tsv - delimiter, null_string, content_encoding
options_copy - delimiter, null_string, header, quote, escape, force_quote, force_not_null, force_null, content_encoding.
options_binary - content_encoding
Knowing the above, we can discard recordings with null gravatar_id during parsing.
INSERT INTO github_users
SELECT user_id, url, UPPER(login), avatar_url, gravatar_id, display_login
FROM azure_storage.blob_get('pgquickstart', 'github', 'users.csv.gz', NULL::github_users,
options := azure_storage.options_csv_get(force_not_null := ARRAY['gravatar_id']));
INSERT 0 264308
Access private storage
Obtain your account name and access key
Without an access key, we won't be allowed to list containers that are set to Private or Blob access levels.
SELECT * FROM azure_storage.blob_list('mystorageaccount','privdatasets');ERROR: azure_storage: missing account access key HINT: Use SELECT azure_storage.account_add('<account name>', '<access key>')In your storage account, open Access keys. Copy the Storage account name and copy the Key from key1 section (you have to select Show next to the key first).
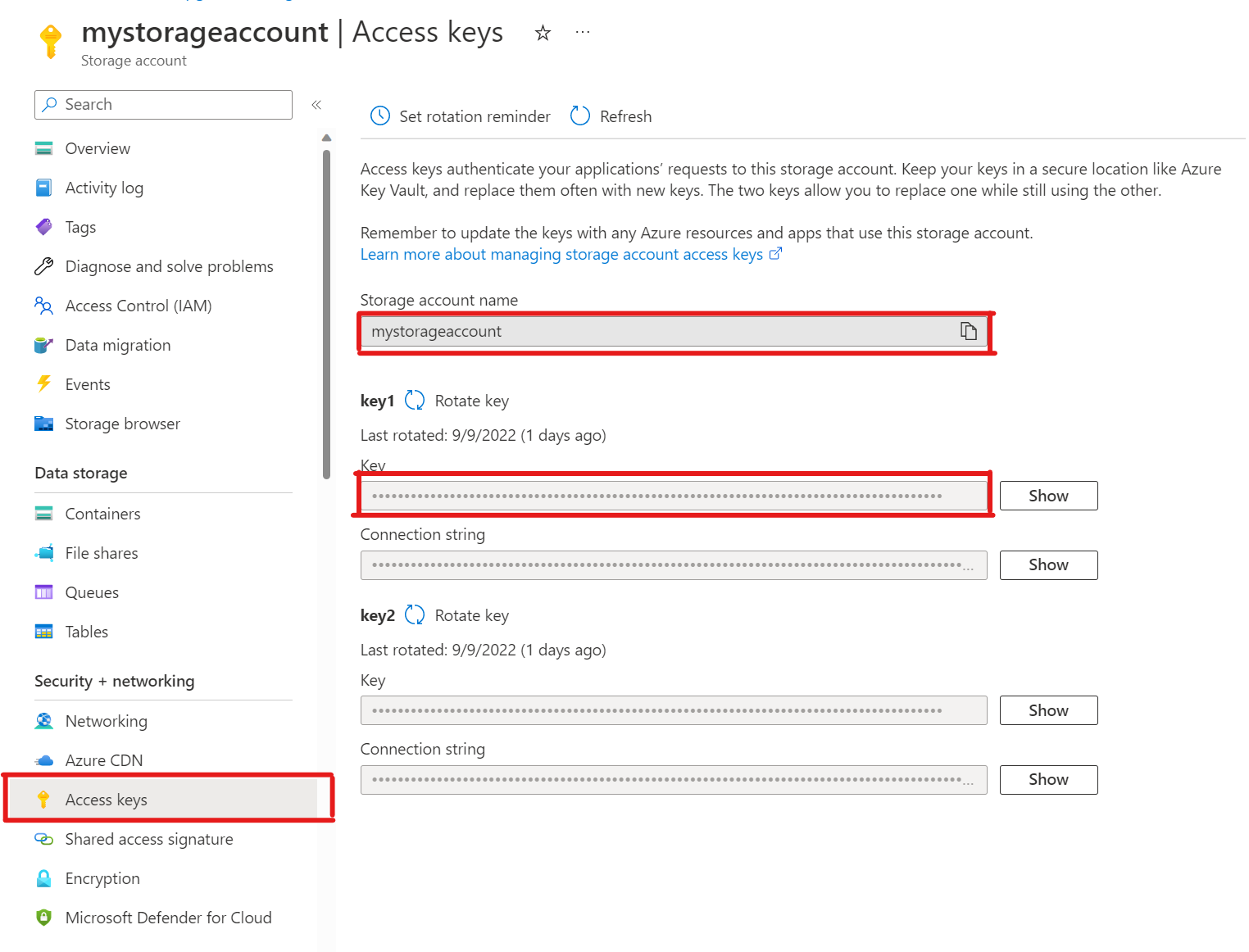
Adding an account to pg_azure_storage
SELECT azure_storage.account_add('mystorageaccount', 'SECRET_ACCESS_KEY');Now you can list containers set to Private and Blob access levels for that storage but only as the
citususer, which has theazure_storage_adminrole granted to it. If you create a new user namedsupport, it won't be allowed to access container contents by default.SELECT * FROM azure_storage.blob_list('pgabs','dataverse');ERROR: azure_storage: current user support is not allowed to use storage account pgabsAllow the
supportuser to use a specific Azure Blob Storage accountGranting the permission is as simple as calling
account_user_add.SELECT * FROM azure_storage.account_user_add('mystorageaccount', 'support');We can see the allowed users in the output of
account_list, which shows all accounts with access keys defined.SELECT * FROM azure_storage.account_list();account_name | allowed_users ------------------+--------------- mystorageaccount | {support} (1 row)If you ever decide, that the user should no longer have access. Just call
account_user_remove.SELECT * FROM azure_storage.account_user_remove('mystorageaccount', 'support');
Next steps
Congratulations, you just learned how to load data into Azure Cosmos DB for PostgreSQL directly from Azure Blob Storage.
- Learn how to create a real-time dashboard with Azure Cosmos DB for PostgreSQL.
- Learn more about pg_azure_storage.
- Learn about Postgres COPY support.