Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
The function dbscan_fl() is a UDF (user-defined function) that clusterizes a dataset using the DBSCAN algorithm.
Prerequisites
- The Python plugin must be enabled on the cluster. This is required for the inline Python used in the function.
Syntax
T | invoke dbscan_fl(features, cluster_col, epsilon, min_samples, metric, metric_params)
Learn more about syntax conventions.
Parameters
| Name | Type | Required | Description |
|---|---|---|---|
| features | dynamic |
✔️ | An array containing the names of the features columns to use for clustering. |
| cluster_col | string |
✔️ | The name of the column to store the output cluster ID for each record. |
| epsilon | real |
✔️ | The maximum distance between two samples to be considered as neighbors. |
| min_samples | int |
The number of samples in a neighborhood for a point to be considered as a core point. | |
| metric | string |
The metric to use when calculating distance between points. | |
| metric_params | dynamic |
Extra keyword arguments for the metric function. |
- For detailed description of the parameters, see DBSCAN documentation
- For the list of metrics see distance computations
Function definition
You can define the function by either embedding its code as a query-defined function, or creating it as a stored function in your database, as follows:
Define the function using the following let statement. No permissions are required.
Important
A let statement can't run on its own. It must be followed by a tabular expression statement. To run a working example of kmeans_fl(), see example.
let dbscan_fl=(tbl:(*), features:dynamic, cluster_col:string, epsilon:double, min_samples:int=10,
metric:string='minkowski', metric_params:dynamic=dynamic({'p': 2}))
{
let kwargs = bag_pack('features', features, 'cluster_col', cluster_col, 'epsilon', epsilon, 'min_samples', min_samples,
'metric', metric, 'metric_params', metric_params);
let code = ```if 1:
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
features = kargs["features"]
cluster_col = kargs["cluster_col"]
epsilon = kargs["epsilon"]
min_samples = kargs["min_samples"]
metric = kargs["metric"]
metric_params = kargs["metric_params"]
df1 = df[features]
mat = df1.values
# Scale the dataframe
scaler = StandardScaler()
mat = scaler.fit_transform(mat)
# see https://docs.scipy.org/doc/scipy/reference/spatial.distance.html for the various distance metrics
dbscan = DBSCAN(eps=epsilon, min_samples=min_samples, metric=metric, metric_params=metric_params) # 'minkowski', 'chebyshev'
labels = dbscan.fit_predict(mat)
result = df
result[cluster_col] = labels
```;
tbl
| evaluate python(typeof(*),code, kwargs)
};
// Write your query to use the function here.
Example
The following example uses the invoke operator to run the function.
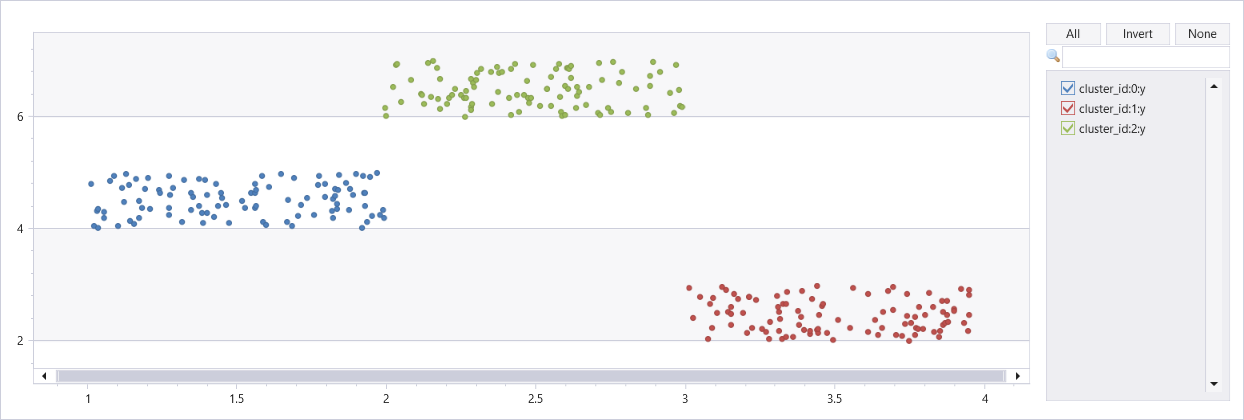
Clustering of artificial dataset with three clusters
To use a query-defined function, invoke it after the embedded function definition.
let dbscan_fl=(tbl:(*), features:dynamic, cluster_col:string, epsilon:double, min_samples:int=10,
metric:string='minkowski', metric_params:dynamic=dynamic({'p': 2}))
{
let kwargs = bag_pack('features', features, 'cluster_col', cluster_col, 'epsilon', epsilon, 'min_samples', min_samples,
'metric', metric, 'metric_params', metric_params);
let code = ```if 1:
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
features = kargs["features"]
cluster_col = kargs["cluster_col"]
epsilon = kargs["epsilon"]
min_samples = kargs["min_samples"]
metric = kargs["metric"]
metric_params = kargs["metric_params"]
df1 = df[features]
mat = df1.values
# Scale the dataframe
scaler = StandardScaler()
mat = scaler.fit_transform(mat)
# see https://docs.scipy.org/doc/scipy/reference/spatial.distance.html for the various distance metrics
dbscan = DBSCAN(eps=epsilon, min_samples=min_samples, metric=metric, metric_params=metric_params) # 'minkowski', 'chebyshev'
labels = dbscan.fit_predict(mat)
result = df
result[cluster_col] = labels
```;
tbl
| evaluate python(typeof(*),code, kwargs)
};
union
(range x from 1 to 100 step 1 | extend x=rand()+3, y=rand()+2),
(range x from 101 to 200 step 1 | extend x=rand()+1, y=rand()+4),
(range x from 201 to 300 step 1 | extend x=rand()+2, y=rand()+6)
| extend cluster_id=int(null)
| invoke dbscan_fl(pack_array("x", "y"), "cluster_id", epsilon=0.6, min_samples=4, metric_params=dynamic({'p':2}))
| render scatterchart with(series=cluster_id)