Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
This page lists existing graphs on our help cluster at https://help.chinaeast2.kusto.chinacloudapi.cn in the Samples database and shows how to query them using the Kusto Query Language (KQL). These examples demonstrate querying prebuilt graph models without requiring any creation or setup steps.
Simple educational graph for learning fundamentals
Usage: graph("Simple")
Purpose: Basic graph operations and learning fundamental graph query patterns.
Description: A small educational graph containing people, companies, and cities with various relationships. Perfect for learning graph traversals and understanding basic patterns. This compact dataset includes 11 nodes (5 people, 3 companies, and 3 cities) connected through 20 relationships, making it ideal for understanding graph fundamentals without the complexity of larger datasets. The graph demonstrates common real-world scenarios like employment relationships, geographic locations, social connections, and personal preferences.
Use Cases:
- Learning graph query fundamentals
- Testing graph algorithms
- Understanding relationship patterns
- Educational examples for graph concepts
Schema Relationships:
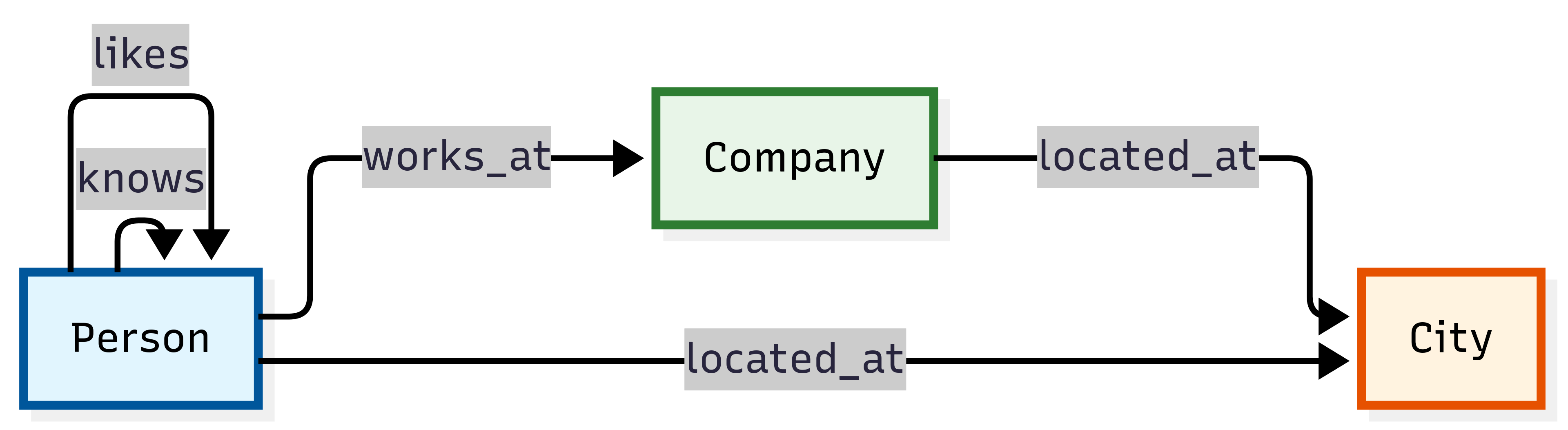
Schema and Counts:
Node Types:
Person- Individual people (5 nodes)Company- Business organizations (3 nodes)City- Geographic locations (3 nodes)
Relationship Types:
works_at- Employment relationships (5 edges)located_at- Geographic location assignments (8 edges)knows- Social connections between people (4 edges)likes- Personal preferences and interests (3 edges)
Graph Instance Example:
This example demonstrates basic graph relationships in a small, easy-to-understand network showing how people connect to companies and cities through various relationship types.
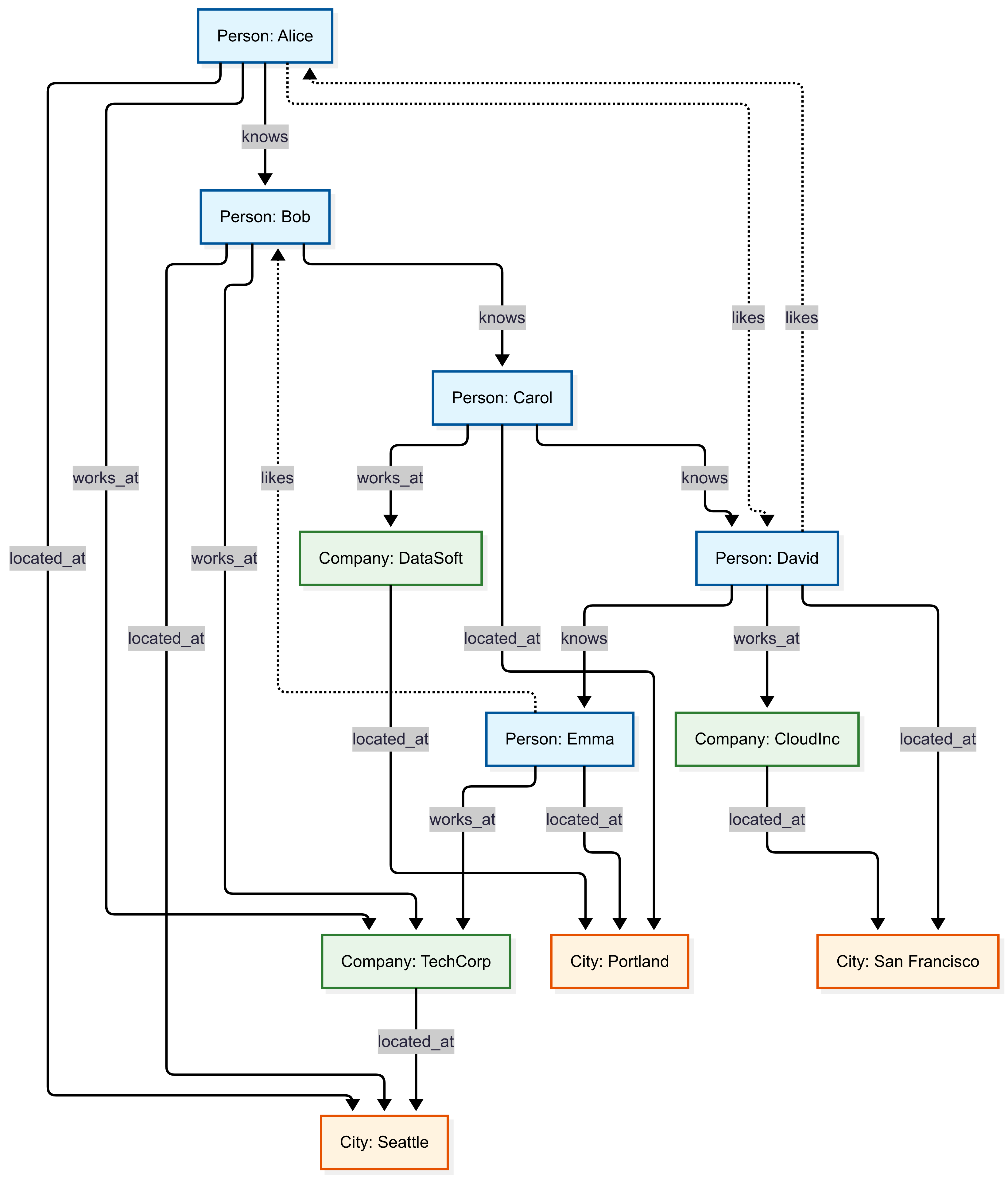
Example Queries:
Find all employees of a specific company:
graph("Simple")
| graph-match (person)-[works_at]->(company)
where company.name == "TechCorp"
project employee_name = person.name, employee_age = person.properties.age
| employee_name | employee_age |
|---|---|
| Alice | 25 |
| Bob | 30 |
| Emma | 26 |
Find colleagues (people working at the same company):
graph("Simple")
| graph-match (person1)-->(company)<--(person2)
where person1.id != person2.id and labels(company) has "Company"
project colleague1 = person1.name, colleague2 = person2.name, company = company.name
| take 1
| colleague1 | colleague2 | company |
|---|---|---|
| Alice | Bob | TechCorp |
LDBC SNB interactive
Usage: graph("LDBC_SNB_Interactive")
Purpose: Social network traversals and friend-of-friend exploration.
Note
This dataset is provided under the Apache License 2.0. The LDBC Social Network Benchmark datasets are created by the Linked Data Benchmark Council (LDBC).
Description: The Linked Data Benchmark Council (LDBC) Social Network Benchmark Interactive workload dataset represents a comprehensive social network modeling real-world social media platforms. This benchmark captures the complexity of modern social networks with over 327,000 nodes and multiple relationship types, including hierarchical geographic data, multi-level organizational structures, and rich content interactions. The dataset models realistic social media ecosystems with people creating posts and comments, participating in forums, working at organizations, and living in geographic locations across a detailed hierarchy from continents to cities.
Use Cases:
- Social network analysis and recommendation systems
- Community detection algorithms
- Influence propagation studies
- Content recommendation based on social connections
- Friend-of-friend discovery
- Social graph mining research
Graph Schema Overview:
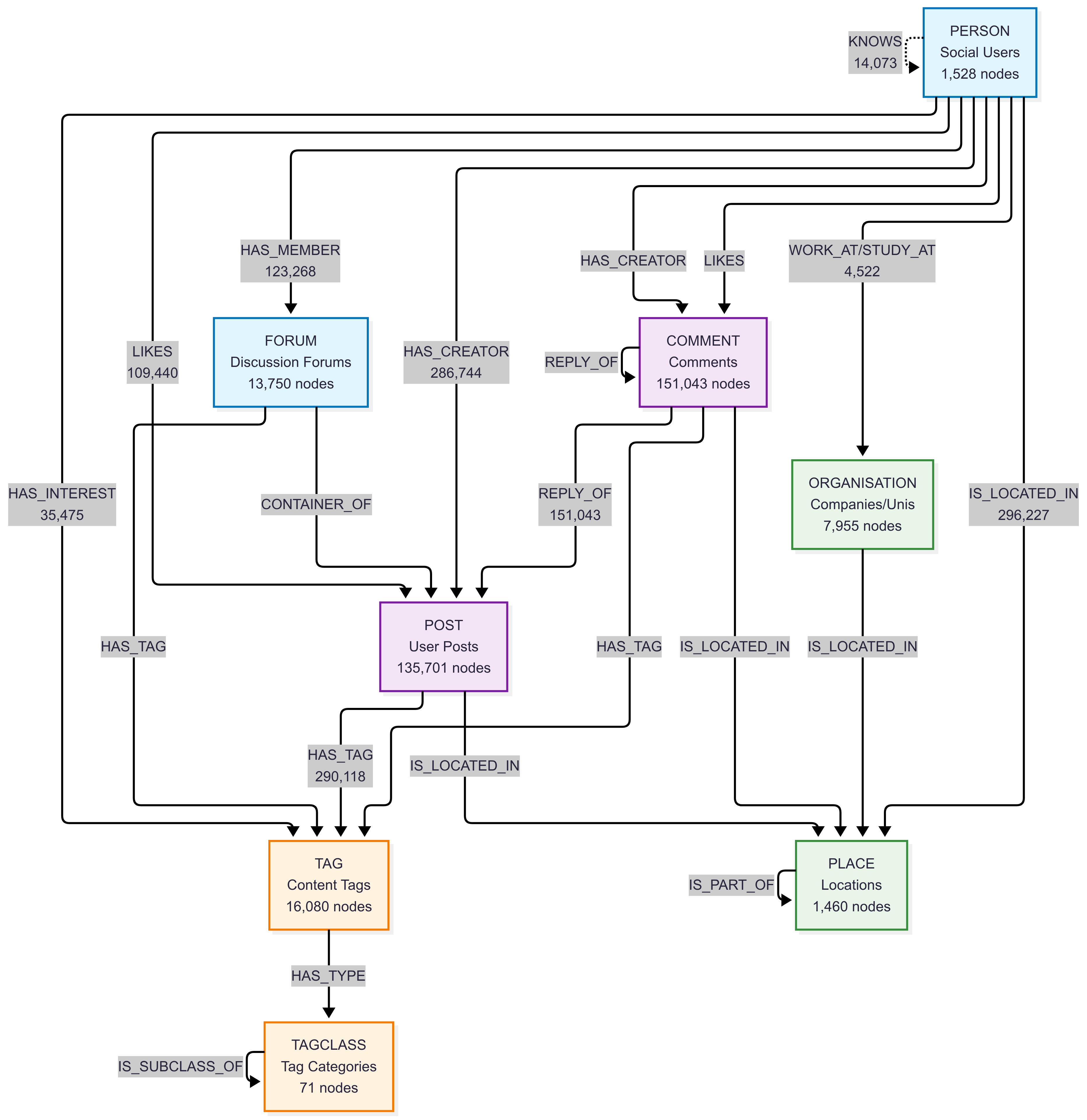
Schema and Counts:
Core Social Entity Types:
PERSON- Social network users (1,528 nodes)POST- User posts (135,701 nodes)COMMENT- Comments on posts (151,043 nodes)FORUM- Discussion forums (13,750 nodes)
Organizational and Geographic Types:
ORGANISATION- Universities and companies (7,955 nodes)PLACE- Geographic locations: continents (6), countries (111), cities (1,343) - total 1,460 nodes
Content Classification Types:
TAG- Content tags (16,080 nodes)TAGCLASS- Tag categories (71 nodes)
Key Relationship Types:
KNOWS- Friend relationships (14,073 edges)LIKES- Content likes: posts (47,215) + comments (62,225) = 109,440 total edgesHAS_CREATOR- Content authorship: posts (135,701) + comments (151,043) = 286,744 edgesHAS_MEMBER- Forum memberships (123,268 edges)HAS_TAG- Content tagging: posts (51,118) + comments (191,303) + forums (47,697) = 290,118 edgesIS_LOCATED_IN- Location relationships: people (1,528) + organizations (7,955) + posts (135,701) + comments (151,043) = 296,227 edgesREPLY_OF- Comment threading: comment-to-comment (76,787) + comment-to-post (74,256) = 151,043 edgesWORK_AT/STUDY_AT- Professional/educational history (4,522 edges)HAS_INTEREST- Personal interests (35,475 edges)- Other relationships:
HAS_MODERATOR,IS_PART_OF,CONTAINER_OF,HAS_TYPE,IS_SUBCLASS_OF
Graph Instance Example:
This example demonstrates complex social network interactions in a realistic social media environment, showing how users engage with content, participate in forums, and form social connections.
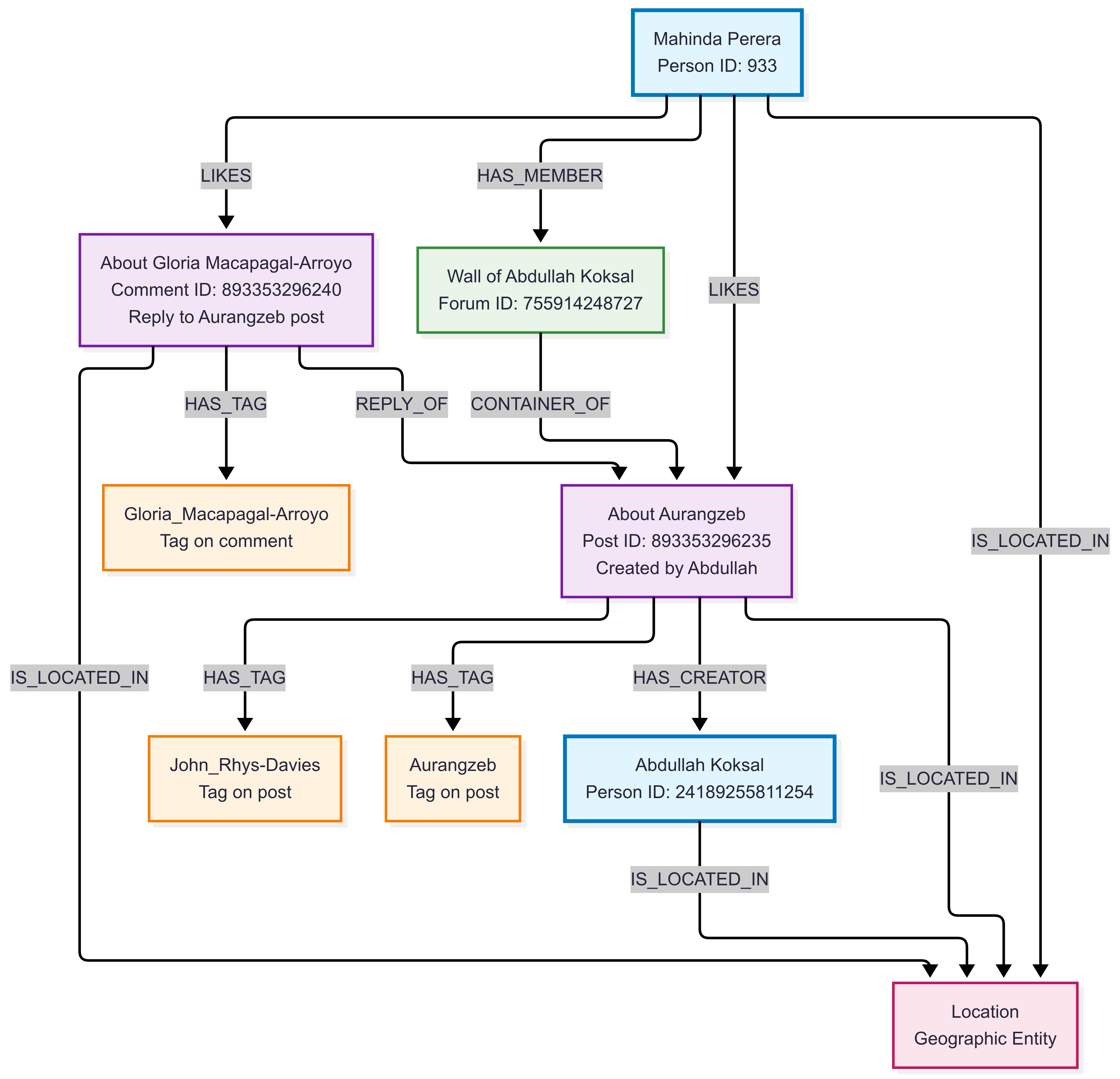
This example demonstrates:
- Social Engagement: Mahinda likes both Abdullah's post and a comment on that post
- Content Threading: The comment (about Gloria Macapagal-Arroyo) replies to the post (about Aurangzeb)
- Content Creation: Abdullah creates posts in his own forum wall
- Community Participation: Mahinda is a member of Abdullah's forum where the content appears
- Content Classification: Both posts and comments are tagged with relevant topics from their content
- Geographic Context: All entities have location relationships for geographic analysis
Use Cases:
- Social network analysis and recommendation systems
- Community detection algorithms
- Influence propagation studies
- Content recommendation based on social connections
- Friend-of-friend discovery
- Social graph mining research
Example Queries:
Find direct friendships with similar ages:
This query identifies pairs of people who are directly connected through a "KNOWS" relationship and have similar ages (birthdays within 30 days of each other). It traverses the LDBC social network graph to find existing friendships between people of similar age groups. The query returns the total count of such age-similar friendship pairs in the network, which can be useful for analyzing age-based social patterns or validating friend recommendation algorithms.
graph("LDBC_SNB_Interactive")
| graph-match (person1)-[knows]->(person2)
where labels(person1) has "PERSON" and labels(person2) has "PERSON" and
labels(knows) has "KNOWS"and abs(person1.birthday - person2.birthday) < 30d
project person_name = person1.firstName, friend_name = person2.firstName
| count
| Count |
|---|
| 225 |
Find popular posts by likes:
This query analyzes social engagement by identifying the most popular content creators based on how many unique people have liked their posts. It traverses the social network graph through the path: person → likes → post → has_creator → creator. The query aggregates the data to show each creator's total number of unique likers and distinct posts, then returns the top 3 creators with the most likes. This is useful for identifying influential content creators, understanding engagement patterns, and discovering viral content in the social network.
graph("LDBC_SNB_Interactive")
| graph-match (person)-[likes]->(post)-[has_creator]->(creator)
where labels(person) has "Person" and labels( post) has "POST" and labels(has_creator) has "HAS_CREATOR" and isnotempty(creator.lastName)
project personId = person.id, postId = post.id, creator = creator.lastName
| summarize Likes = dcount(personId), posts = dcount(postId) by creator
| top 3 by Likes desc
| creator | Likes | posts |
|---|---|---|
| Zhang | 371 | 207 |
| Hoffmann | 340 | 9 |
| Singh | 338 | 268 |
LDBC Financial
Usage: graph("LDBC_Financial")
Purpose: Financial transaction analysis and fraud detection patterns.
Note
This dataset is provided under the Apache License 2.0. The LDBC Financial Benchmark datasets are created by the Linked Data Benchmark Council (LDBC).
Description: LDBC Financial Benchmark dataset representing a comprehensive financial network with companies, persons, accounts, loans, and various financial transactions. This dataset models realistic financial ecosystems with 5,580 total nodes and over 31,000 financial transactions and relationships. Designed specifically for fraud detection, anti-money laundering (AML) analysis, and financial crime investigation scenarios, it captures complex patterns including account ownership, loan applications, guarantees, and multi-step transaction chains that are common in financial crime scenarios.
Use Cases:
- Financial fraud detection
- Anti-money laundering (AML) analysis
- Transaction pattern analysis
- Risk assessment and credit scoring
- Suspicious activity monitoring
- Financial network analysis
Graph Schema Overview:
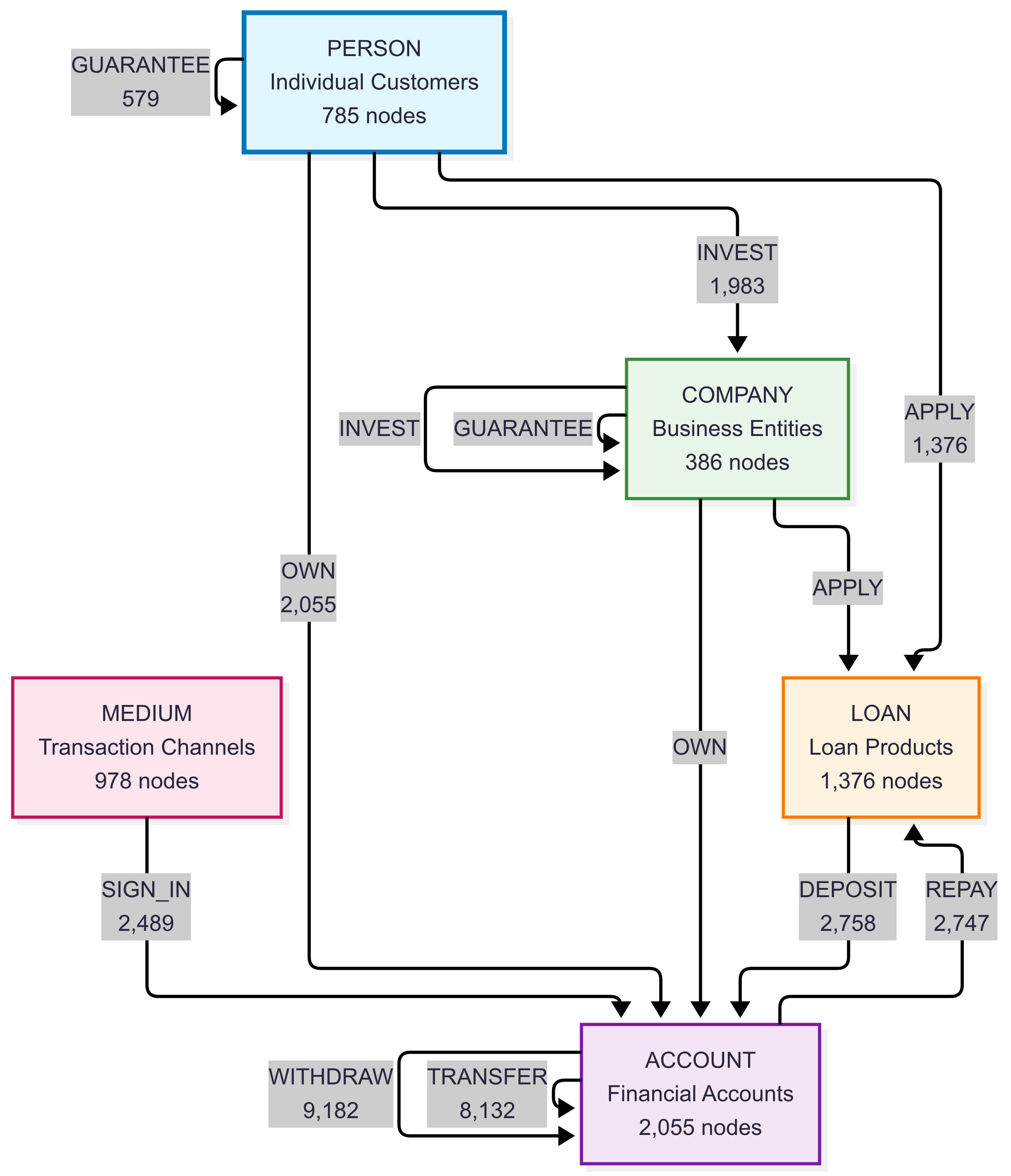
Schema and Counts:
Node Types:
COMPANY- Business entities (386 nodes)PERSON- Individual customers (785 nodes)ACCOUNT- Financial accounts (2,055 nodes)LOAN- Loan products (1,376 nodes)MEDIUM- Transaction mediums/channels (978 nodes)
Relationship Types:
TRANSFER- Money transfers between accounts (8,132 edges)WITHDRAW- Cash withdrawals from accounts (9,182 edges)DEPOSIT- Money deposits into accounts (2,758 edges)OWN- Account ownership relationships (2,055 edges)APPLY- Loan applications (1,376 edges)GUARANTEE- Loan guarantees (579 edges)INVEST- Investment transactions (1,983 edges)REPAY- Loan repayments (2,747 edges)SIGN_IN- Authentication events (2,489 edges)
Graph Instance Example:
This example illustrates a complex financial network with multiple entity types and transaction patterns, demonstrating how financial institutions can model relationships between customers, accounts, loans, and transaction flows for fraud detection and risk assessment.
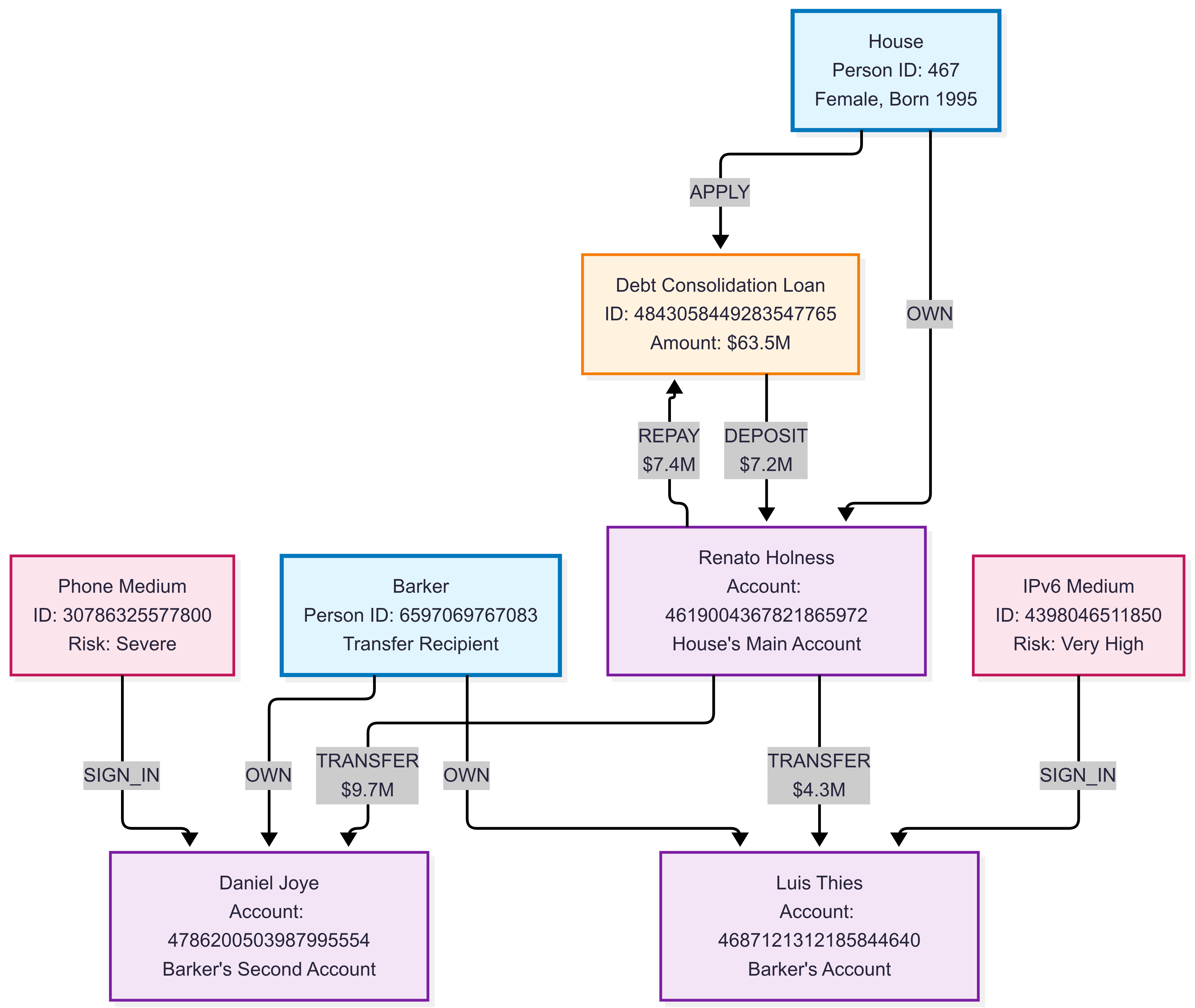
Example Queries:
Detect potential money laundering through circular transfers:
This query identifies suspicious circular transaction patterns that could indicate money laundering activities. It searches for accounts that send money to another account and then receive it back through a chain of 1 to 3 transfers, creating a circular flow. The query specifically looks for large initial transfers (over 10,000) and returns details about the suspicious accounts, including the transfer amount and the length of the circular chain. This pattern detection is useful for anti-money laundering (AML) systems and financial fraud investigations.
graph("LDBC_Financial")
| graph-match (account1)-[t1]->(account2)-[t2*1..3]->(account1)
where labels(t1) has "TRANSFER" and t1.amount > 10000 // Large initial transfer
project suspicious_account = account1.node_id,
amount = t1.amount,
transfer_chain_length = array_length(t2) + 1
| take 10
| suspicious_account | amount | transfer_chain_length |
|---|---|---|
| Account::4818007176356300028 | 5035377,73 | 2 |
| Account::4818007176356300028 | 5035377,73 | 2 |
| Account::4845310249097233848 | 359062,45 | 2 |
| Account::4818007176356300028 | 5035377,73 | 3 |
| Account::4818007176356300028 | 5035377,73 | 4 |
| Account::4840243699516440940 | 5753668,55 | 4 |
| Account::4818007176356300028 | 5035377,73 | 4 |
| Account::180143985094820389 | 465338,26 | 4 |
| Account::4814910951612482356 | 1684581,62 | 4 |
| Account::4816599801472746629 | 963626,42 | 4 |
Find high-risk loan guarantors:
This query identifies individuals or companies who guarantee multiple loans totaling significant amounts, which could indicate financial risk exposure. It traverses the financial network graph following the path: guarantor → guarantee → borrower → apply → loan. The query aggregates the total amount guaranteed and number of loans for each guarantor, then filters for those guaranteeing over 100,000 in total and returns the top 5 by total guaranteed amount. This analysis is useful for risk assessment, identifying over-leveraged guarantors, and evaluating systemic financial risks in lending networks.
graph("LDBC_Financial")
| graph-match (guarantor)-[guarantee]->(borrower)-[apply]->(loan)
where labels(guarantee) has "GUARANTEE" and labels(apply) has "APPLY"
project guarantor_id = guarantor.node_id,
borrower_id = borrower.node_id,
loan_amount = loan.loanAmount
| summarize total_guaranteed = sum(loan_amount), loan_count = count() by guarantor_id
| where total_guaranteed > 100000
| top 5 by total_guaranteed desc
| guarantor_id | total_guaranteed | loan_count |
|---|---|---|
| Person::44 | 439802195 | 8 |
| Person::15393162789155 | 411111642 | 8 |
| Company::12094627905931 | 404538891 | 6 |
| Company::4398046511208 | 366243272 | 8 |
| Person::19791209300551 | 338838223 | 6 |
BloodHound Entra dataset
Usage: graph("BloodHound_Entra")
Purpose: Microsoft Entra privilege escalation and attack path analysis.
Note
This dataset is provided under the Apache License 2.0. The BloodHound datasets are created by the BloodHound project.
Description: BloodHound dataset for Microsoft Entra environments. This comprehensive security dataset contains 13,526 Microsoft Entra objects including users, groups, applications, service principals, devices, and various cloud resources. With over 800,000 permission relationships and security edges, it models complex Microsoft Entra environments typical of enterprise organizations. The dataset captures detailed Microsoft Entra permissions, role assignments, group memberships, and resource ownership patterns essential for identifying privilege escalation paths and attack vectors in cloud environments.
Use Cases:
- Entra ID security assessments
- Privilege escalation path discovery
- Attack path visualization
- Identity governance analysis
- Risk-based security controls
- Compliance auditing for cloud environments
Graph Schema Overview:
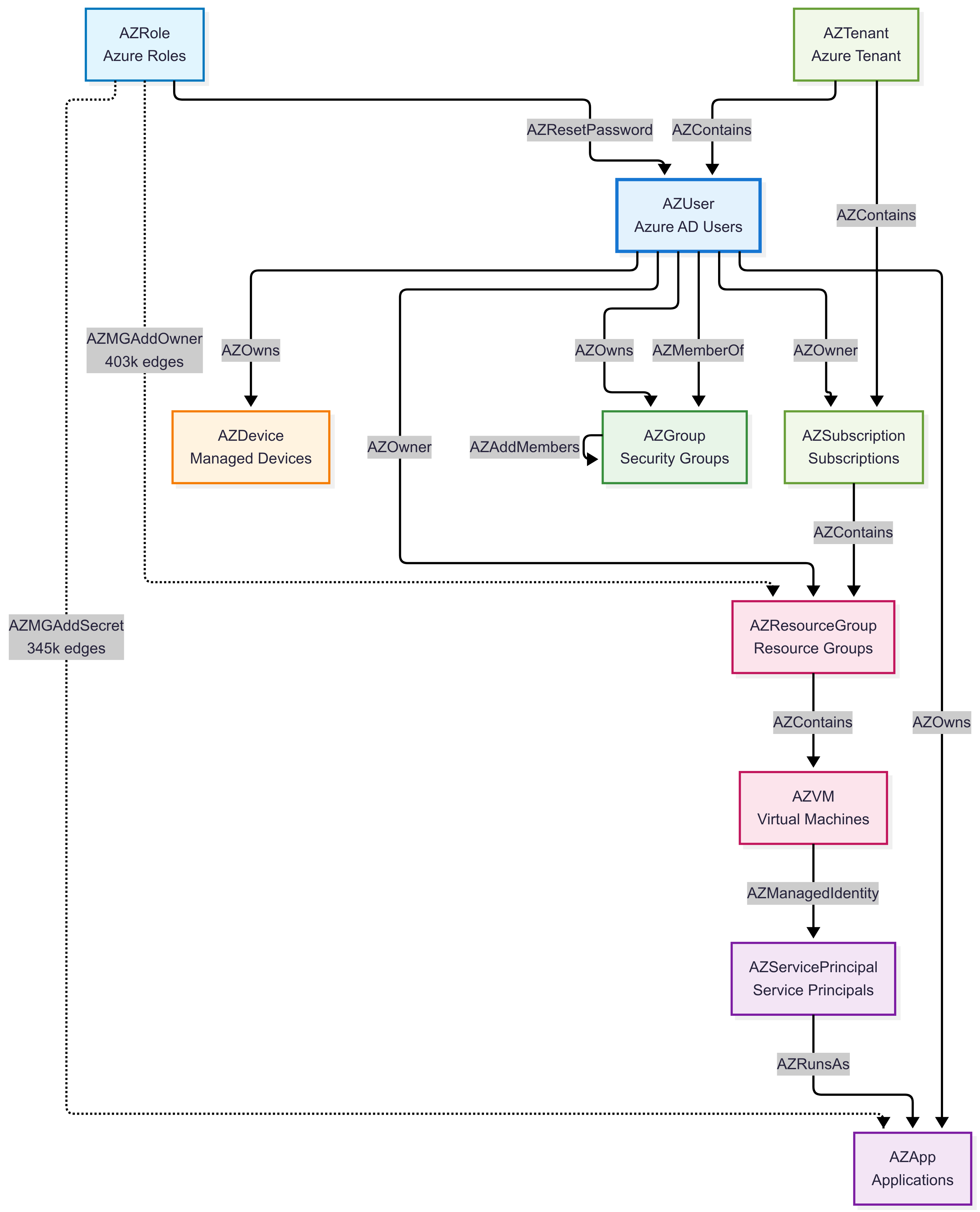
Schema and Counts:
Note
This dataset is provided under the Apache License 2.0. The BloodHound datasets are created by the BloodHound Community Edition project.
Description: BloodHound Community Edition dataset for Microsoft Entra environments. This comprehensive security dataset contains 13,526 Microsoft Entra objects including users, groups, applications, service principals, devices, and various cloud resources. With over 800,000 permission relationships and security edges, it models complex Microsoft Entra environments typical of enterprise organizations. The dataset captures detailed Microsoft Entra permissions, role assignments, group memberships, and resource ownership patterns essential for identifying privilege escalation paths and attack vectors in cloud environments.
Schema and Counts:
Primary Node Types:
AZUser- Microsoft Entra users (230 nodes)AZServicePrincipal- Service principals and applications (6,270 nodes)AZApp- Azure applications (6,648 nodes)AZGroup- Microsoft Entra groups (58 nodes)AZDevice- Managed devices (47 nodes)
Azure Resource Types:
AZResourceGroup- Resource groups (59 nodes)AZVM- Virtual machines (66 nodes)AZRole- Azure roles (116 nodes)AZSubscription- Azure subscriptions (3 nodes)AZTenant- Azure tenant (1 node)
Key Relationship Types (Top permissions by volume):
AZMGAddOwner- Management group owner permissions (403,412 edges)AZMGAddSecret- Secret management permissions (345,324 edges)AZAddSecret- Application secret permissions (24,666 edges)AZContains- Resource containment relationships (12,924 edges)AZRunsAs- Service execution permissions (6,269 edges)AZMemberOf- Group membership relationships (4,439 edges)AZOwns- Resource ownership (2,870 edges)
Graph Instance Example:
This example demonstrates Microsoft Entra and Entra identity relationships with complex privilege structures and potential attack paths in a cloud environment.
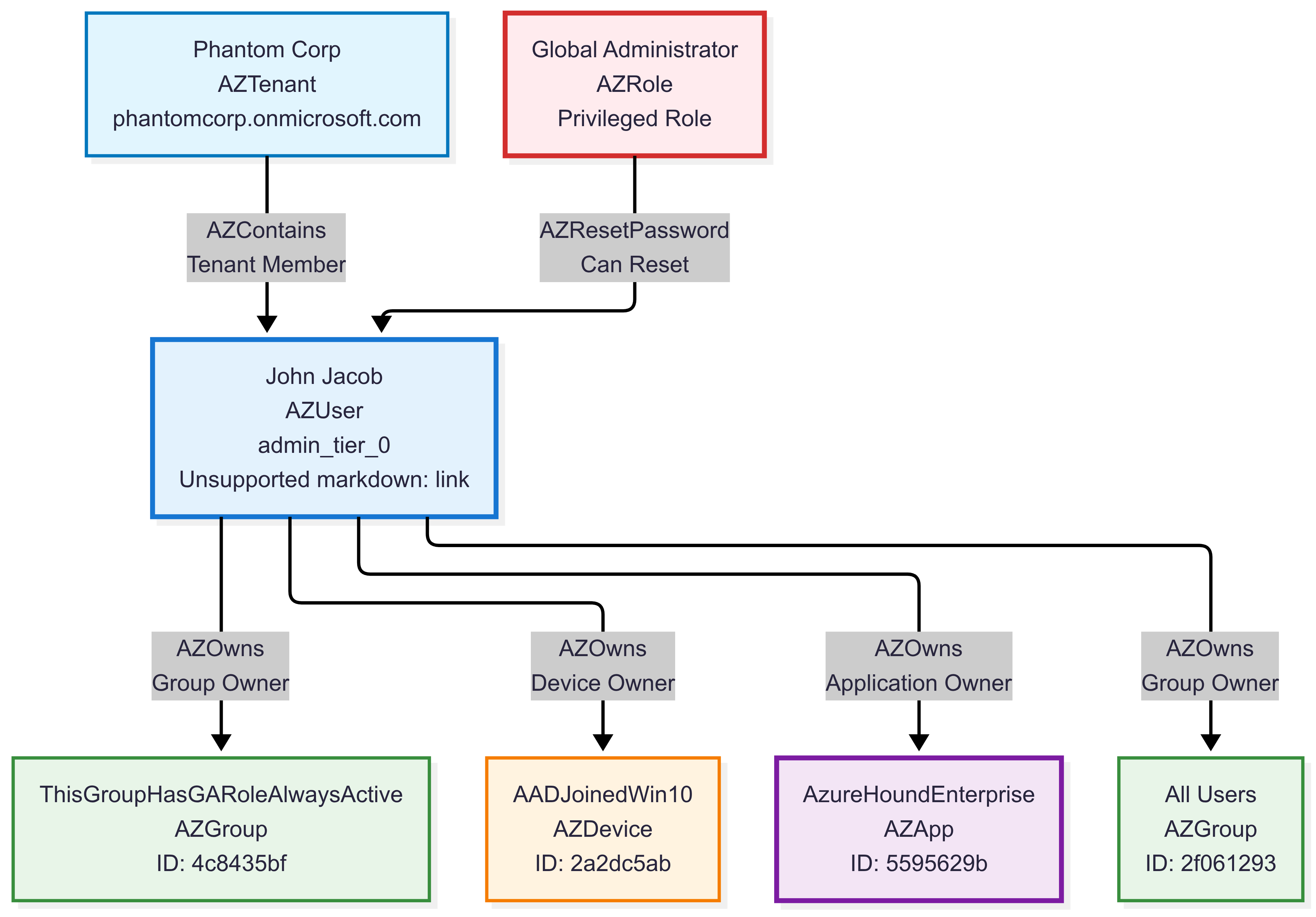
Use Cases:
- Entra ID security assessments
- Privilege escalation path discovery
- Attack path visualization
- Identity governance analysis
- Risk-based security controls
- Compliance auditing for cloud environments
Example Queries:
Find paths to administrative privileges:
This query identifies privilege escalation paths from regular users to administrative groups in Microsoft Entra environments. It searches for users who can reach admin groups (like Microsoft Entra DC Administrators, DnsAdmins, etc.) through 1-3 relationship hops, helping security teams understand potential attack paths and privilege escalation risks.
graph("BloodHound_Entra")
| graph-match (user)-[path*1..3]->(admingroup)
where labels(user) has_any ("User", "AZUser")
and labels(admingroup) has_any ("Group", "AZGroup")
and (admingroup.name contains "ADMIN" or admingroup.displayname contains "ADMIN")
project source_user = user.name,
path_length = array_length(path),
admin_group = coalesce(admingroup.displayname, admingroup.name)
| take 10
| source_user | path_length | admin_group |
|---|---|---|
| THISUSERHASINTUNEADMINROLE@PHANTOMCORP.ONMICROSOFT.COM | 1 | ADSyncAdmins |
| 097EF6C2-GROUPSADMINISTRATOR@PHANTOMCORP.ONMICROSOFT.COM | 1 | AAD DC Administrators |
| USERBELONGSTOGAGROUP@PHANTOMCORP.ONMICROSOFT.COM | 1 | ADSyncAdmins |
| THISUSERHASINTUNEADMINROLE@PHANTOMCORP.ONMICROSOFT.COM | 1 | DnsAdmins |
| RHADMIN@PHANTOMCORP.ONMICROSOFT.COM | 1 | DnsAdmins |
| CJACKSON@PHANTOMCORP.ONMICROSOFT.COM | 1 | Azure ATP phantom Administrators |
| 097EF6C2-INTUNEADMINISTRATOR@PHANTOMCORP.ONMICROSOFT.COM | 1 | AAD DC Administrators |
| RHADMIN_PHANTOMCORP.ONMICROSOFT.COM#EXT#@PHANTOMCORP.ONMICROSOFT.COM | 1 | Resource Group Admins |
| THISUSERHASKNOWLEDGEMANAGERROLE@PHANTOMCORP.ONMICROSOFT.COM | 1 | DnsAdmins |
| 097EF6C2-INTUNEADMINISTRATOR@PHANTOMCORP.ONMICROSOFT.COM | 1 | DnsAdmins |
Identify high-value targets (Tier 0 assets):
This query identifies critical administrative assets marked as "admin_tier_0" in the environment. These are the most sensitive and powerful accounts, service principals, and resources that pose the highest risk if compromised. Understanding these assets helps prioritize security monitoring and protection efforts.
graph("BloodHound_Entra")
| graph-match (asset)
where asset.properties.system_tags contains "admin_tier_0"
project asset_name = asset.name,
asset_type = tostring(labels(asset)[1]), // Get primary type (AZUser, AZServicePrincipal, etc.)
system_tags = asset.properties.system_tags
| take 10
| asset_name | asset_type | system_tags |
|---|---|---|
| JJACOB@PHANTOMCORP.ONMICROSOFT.COM | AZUser | admin_tier_0 |
| PLEWIS@PHANTOMCORP.ONMICROSOFT.COM | AZUser | admin_tier_0 |
| JMILLER@PHANTOMCORP.ONMICROSOFT.COM | AZUser | admin_tier_0 |
| CJACKSON@PHANTOMCORP.ONMICROSOFT.COM | AZUser | admin_tier_0 |
| RHALL@PHANTOMCORP.ONMICROSOFT.COM | AZUser | admin_tier_0 |
| THISAPPHASGLOBALADMIN@PHANTOMCORP | AZServicePrincipal | admin_tier_0 |
| MYCOOLAUTOMATIONACCOUNT@PHANTOMCORP | AZServicePrincipal | admin_tier_0 |
| SERVICEPRINCIPALE@PHANTOMCORP | AZServicePrincipal | admin_tier_0 |
| 31E3B75F-PRIVILEGED AUTHENTICATION ADMINISTRATOR@PHANTOMCORP | AZServicePrincipal | admin_tier_0 |
| 31E3B75F-PRIVILEGED ROLE ADMINISTRATOR@PHANTOMCORP | AZServicePrincipal | admin_tier_0 |
BloodHound Active Directory dataset
Usage: graph("BloodHound_AD")
Purpose: On-premises Active Directory security analysis and privilege mapping.
Note
This dataset is provided under the Apache License 2.0. The BloodHound datasets are created by the BloodHound project.
Description: BloodHound Community Edition dataset for on-premises Active Directory environments. This dataset contains 1,495 Active Directory objects representing a typical enterprise AD deployment with complex permission structures and attack paths. The dataset includes users, computers, groups, organizational units, group policy objects, and certificate authority components across multiple domains. With over 18,000 permission relationships and security edges, it captures realistic AD attack scenarios including privilege escalation paths, ACL-based permissions, group memberships, and certificate-based authentication vulnerabilities common in Windows domain environments.
Use Cases:
- Active Directory security assessments
- Attack path analysis and penetration testing
- Domain privilege mapping
- Group policy security analysis
- Kerberoasting and ASREPRoasting target identification
- Security control gap analysis
Graph Schema Overview:
Core AD Object Types:
User- Domain users (99 nodes)Computer- Domain computers (34 nodes)Group- Security and distribution groups (219 nodes)ADLocalGroup- Local groups on computers (28 nodes)GPO- Group Policy Objects (32 nodes)
AD Infrastructure Types:
Domain- Active Directory domains (5 nodes)OU- Organizational Units (20 nodes)Container- AD containers (939 nodes)CertTemplate- Certificate templates (106 nodes)EnterpriseCA- Certificate Authorities (4 nodes)RootCA- Root Certificate Authorities (5 nodes)
Key Permission Types (Top attack vectors):
GenericAll- Full control permissions (3,292 edges)WriteDacl- Modify permissions (2,221 edges)WriteOwner- Change ownership (2,187 edges)Owns- Object ownership (1,439 edges)Contains- Containment relationships (1,416 edges)GenericWrite- Write permissions (579 edges)MemberOf- Group memberships (301 edges)
Graph Schema Overview:
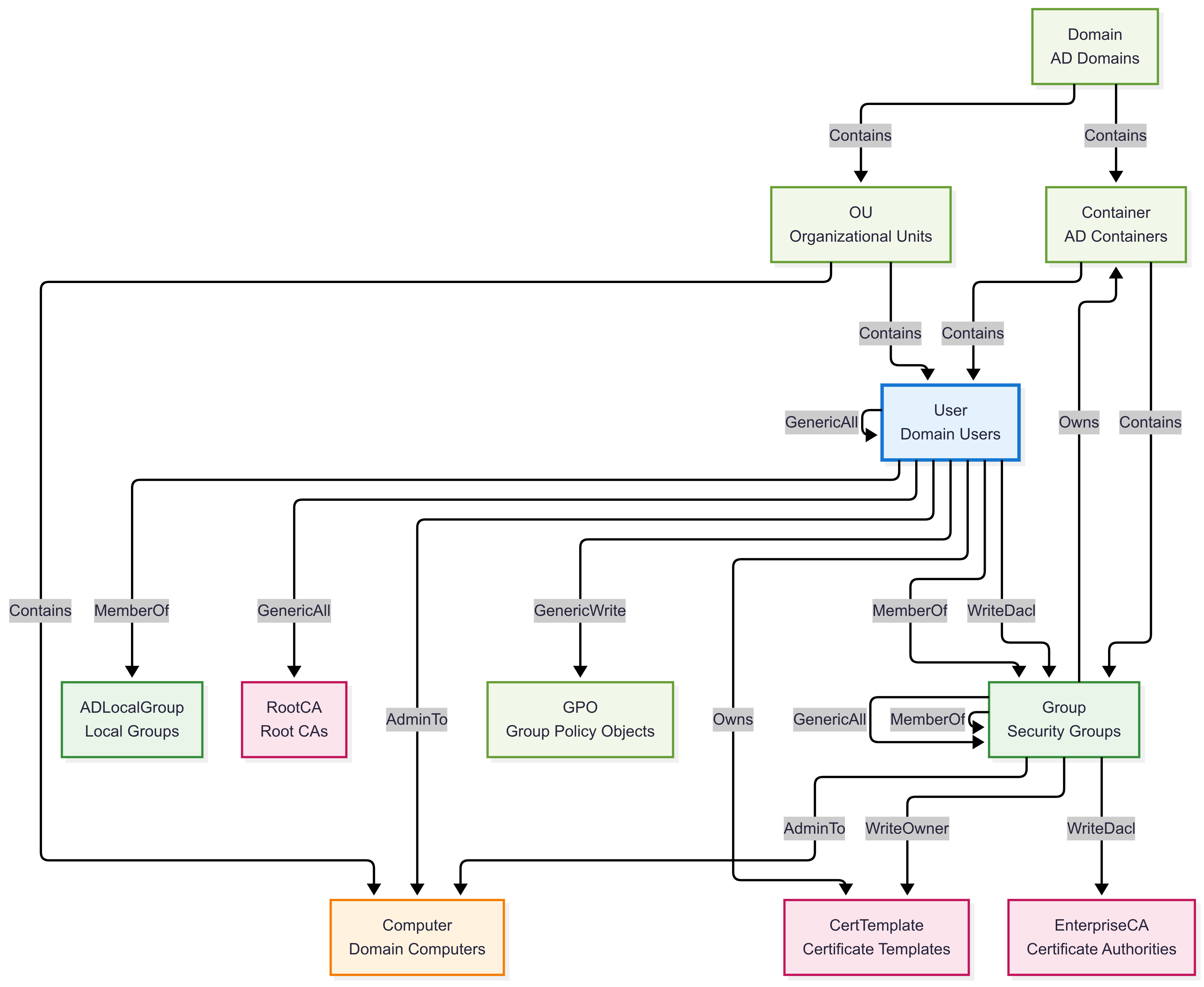
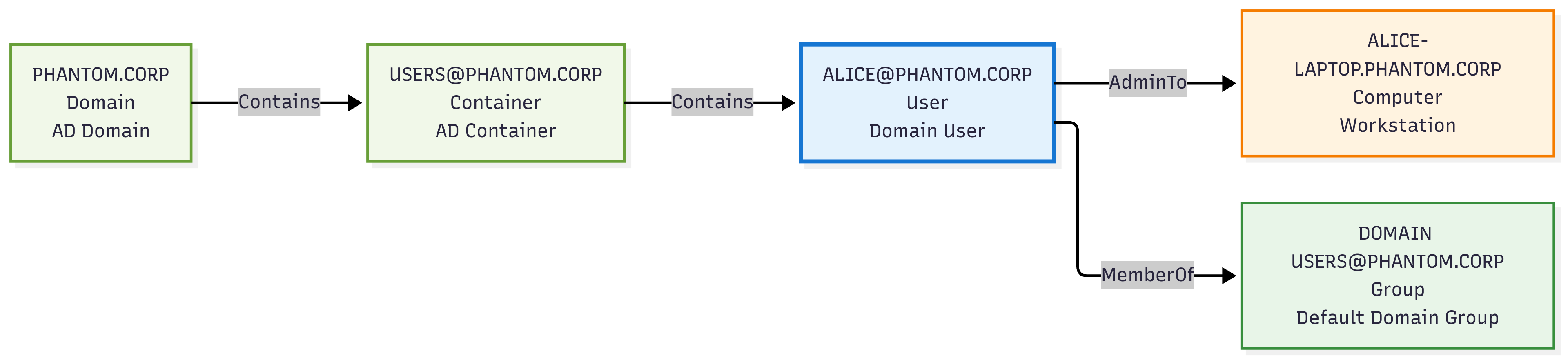
Graph Instance Example:
This example demonstrates on-premises Active Directory attack paths and potential security vulnerabilities in a traditional Windows domain environment.
Use Cases:
- Active Directory security assessments
- Attack path analysis and penetration testing
- Domain privilege mapping
- Group policy security analysis
- Kerberoasting and ASREPRoasting target identification
- Security control gap analysis
Example Queries:
Find potential privilege escalation:
This query counts how many non-admin users can potentially escalate to admin in Microsoft Entra. It traverses up to 10 MemberOf group hops (no cycles) from each user to groups that grant dangerous permissions (GenericAll, WriteDacl, WriteOwner, ForceChangePassword) over admin users (admincount=true), then returns the distinct number of such “potential attacker” users.
graph("BloodHound_AD")
| graph-match cycles=none (user)-[memberof*0..10]->(group)-[permission]->(target)
where labels(user) has "User"
and labels(group) has "Group"
and all(memberof, labels() has "MemberOf")
and user.properties.admincount == false
and (labels(permission) has_any ("GenericAll", "WriteDacl", "WriteOwner", "ForceChangePassword"))
and (labels(target) has "User" and target.properties.admincount == true)
project attack_user = user.name
| summarize ['Potential attackers'] = dcount(attack_user)
| Potential attackers |
|---|
| 2 |
Find Golden Certificate attack paths:
This query identifies entities that can perform Golden Certificate attacks, which allow attackers to forge certificates as any user in the domain. These are critical vulnerabilities as they enable complete domain compromise by allowing the attacker to impersonate any user, including domain administrators, through forged certificates.
graph("BloodHound_AD")
| graph-match (attacker)-[goldencert]->(target)
where labels(goldencert) has "GoldenCert"
project
Attacker = attacker.name,
AttackerType = case(
attacker.name has "DC", "Domain Controller",
attacker.name has "CA", "Certificate Authority",
attacker.name has "SRV", "Server",
"Unknown System"
),
Target = target.name,
RiskLevel = "CRITICAL",
AttackCapability = case(
attacker.name has "DC", "Primary domain controller with certificate services",
attacker.name has "EXTCA", "External Certificate Authority with root access",
attacker.name has "SRV", "Compromised server with certificate generation rights",
"System with certificate forging capabilities"
)
| Attacker | AttackerType | Target | RiskLevel | AttackCapability |
|---|---|---|---|---|
| DC01.PHANTOM.CORP | Unknown System | PHANTOM.CORP | CRITICAL | System with certificate forging capabilities |
| SRV-SHARPHOUND.PHANTOM.CORP | Server | PHANTOM.CORP | CRITICAL | Compromised server with certificate generation rights |
| EXTCA01.WRAITH.CORP | Unknown System | WRAITH.CORP | CRITICAL | System with certificate forging capabilities |
| EXTCA02.WRAITH.CORP | Unknown System | WRAITH.CORP | CRITICAL | System with certificate forging capabilities |