Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
The Common Data Model (CDM) metadata system makes it possible for data and its meaning to be easily shared across applications and business processes. To learn more, see the Common Data Model overview.
In Azure Data Factory and Synapse pipelines, users can transform data from CDM entities in both model.json and manifest form stored in Azure Data Lake Store Gen2 (ADLS Gen2) using mapping data flows. You can also sink data in CDM format using CDM entity references that will land your data in CSV or Parquet format in partitioned folders.
Mapping data flow properties
The Common Data Model is available as an inline dataset in mapping data flows as both a source and a sink.
Note
When writing CDM entities, you must have an existing CDM entity definition (metadata schema) already defined to use as a reference. The data flow sink will read that CDM entity file and import the schema into your sink for field mapping.
Note
When using CDM with Change Data Capture (CDC) in Data Flows, updates are detected using a file-based CDC approach driven by file last modified timestamps.
Source properties
The below table lists the properties supported by a CDM source. You can edit these properties in the Source options tab.
| Name | Description | Required | Allowed values | Data flow script property |
|---|---|---|---|---|
| Format | Format must be cdm |
yes | cdm |
format |
| Metadata format | Where the entity reference to the data is located. If using CDM version 1.0, choose manifest. If using a CDM version before 1.0, choose model.json. | Yes | 'manifest' or 'model' |
manifestType |
| Root location: container | Container name of the CDM folder | yes | String | fileSystem |
| Root location: folder path | Root folder location of CDM folder | yes | String | folderPath |
| Manifest file: Entity path | Folder path of the entity within the root folder | no | String | entityPath |
| Manifest file: Manifest name | Name of the manifest file. Default value is 'default' | No | String | manifestName |
| Filter by last modified | Choose to filter files based upon when they were last altered | no | Timestamp | modifiedAfter modifiedBefore |
| Schema linked service | The linked service where the corpus is located | yes, if using manifest | 'adlsgen2' or 'github' |
corpusStore |
| Entity reference container | Container corpus is in | yes, if using manifest and corpus in ADLS Gen2 | String | adlsgen2_fileSystem |
| Entity reference Repository | GitHub repository name | yes, if using manifest and corpus in GitHub | String | github_repository |
| Entity reference Branch | GitHub repository branch | yes, if using manifest and corpus in GitHub | String | github_branch |
| Corpus folder | the root location of the corpus | yes, if using manifest | String | corpusPath |
| Corpus entity | Path to entity reference | yes | String | entity |
| Allow no files found | If true, an error is not thrown if no files are found | no | true or false |
ignoreNoFilesFound |
When selecting "Entity Reference" both in the Source and Sink transformations, you can select from these three options for the location of your entity reference:
- Local uses the entity defined in the manifest file already being used by the service
- Custom will ask you to point to an entity manifest file that is different from the manifest file the service is using
- Standard will use an entity reference from the standard library of CDM entities maintained in
GitHub.
Sink settings
- Point to the CDM entity reference file that contains the definition of the entity you would like to write.
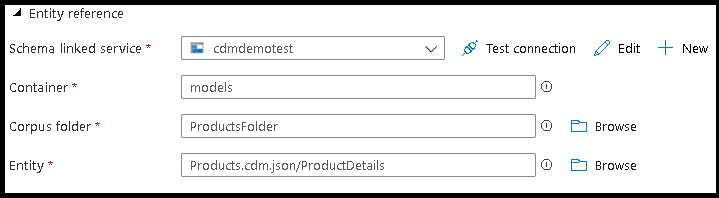
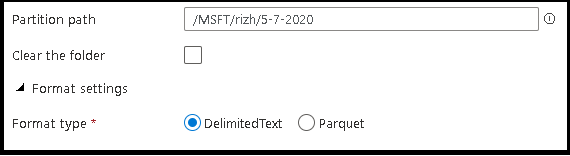
- Define the partition path and format of the output files that you want the service to use for writing your entities.
- Set the output file location and the location and name for the manifest file.

Import schema
CDM is only available as an inline dataset and, by default, doesn't have an associated schema. To get column metadata, click the Import schema button in the Projection tab. This will allow you to reference the column names and data types specified by the corpus. To import the schema, a data flow debug session must be active and you must have an existing CDM entity definition file to point to.
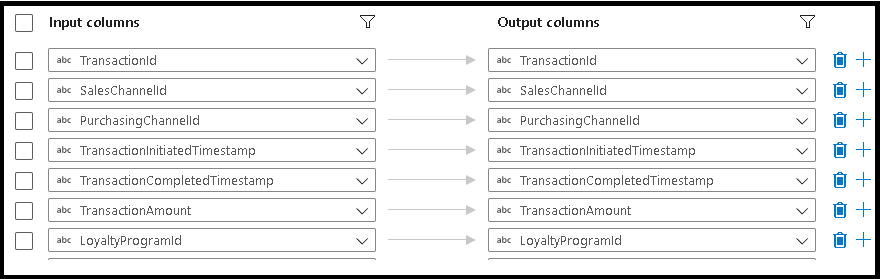
When mapping data flow columns to entity properties in the Sink transformation, click on the "Mapping" tab and select "Import Schema". The service will read the entity reference that you pointed to in your Sink options, allowing you to map to the target CDM schema.
Note
When using model.json source type that originates from Power BI or Power Platform dataflows, you may encounter "corpus path is null or empty" errors from the source transformation. This is likely due to formatting issues of the partition location path in the model.json file. To fix this, follow these steps:
- Open the model.json file in a text editor
- Find the partitions.Location property
- Change "blob.core.chinacloudapi.cn" to "dfs.core.chinacloudapi.cn"
- Fix any "%2F" encoding in the URL to "/"
- If using ADF Data Flows, Special characters in the partition file path must be replaced with alpha-numeric values, or switch to Azure Synapse Data Flows
CDM source data flow script example
source(output(
ProductSizeId as integer,
ProductColor as integer,
CustomerId as string,
Note as string,
LastModifiedDate as timestamp
),
allowSchemaDrift: true,
validateSchema: false,
entity: 'Product.cdm.json/Product',
format: 'cdm',
manifestType: 'manifest',
manifestName: 'ProductManifest',
entityPath: 'Product',
corpusPath: 'Products',
corpusStore: 'adlsgen2',
adlsgen2_fileSystem: 'models',
folderPath: 'ProductData',
fileSystem: 'data') ~> CDMSource
Sink properties
The below table lists the properties supported by a CDM sink. You can edit these properties in the Settings tab.
| Name | Description | Required | Allowed values | Data flow script property |
|---|---|---|---|---|
| Format | Format must be cdm |
yes | cdm |
format |
| Root location: container | Container name of the CDM folder | yes | String | fileSystem |
| Root location: folder path | Root folder location of CDM folder | yes | String | folderPath |
| Manifest file: Entity path | Folder path of the entity within the root folder | no | String | entityPath |
| Manifest file: Manifest name | Name of the manifest file. Default value is 'default' | No | String | manifestName |
| Schema linked service | The linked service where the corpus is located | yes | 'adlsgen2' or 'github' |
corpusStore |
| Entity reference container | Container corpus is in | yes, if corpus in ADLS Gen2 | String | adlsgen2_fileSystem |
| Entity reference Repository | GitHub repository name | yes, if corpus in GitHub | String | github_repository |
| Entity reference Branch | GitHub repository branch | yes, if corpus in GitHub | String | github_branch |
| Corpus folder | the root location of the corpus | yes | String | corpusPath |
| Corpus entity | Path to entity reference | yes | String | entity |
| Partition path | Location where the partition will be written | no | String | partitionPath |
| Clear the folder | If the destination folder is cleared prior to write | no | true or false |
truncate |
| Format type | Choose to specify parquet format | no | parquet if specified |
subformat |
| Column delimiter | If writing to DelimitedText, how to delimit columns | yes, if writing to DelimitedText | String | columnDelimiter |
| First row as header | If using DelimitedText, whether the column names are added as a header | no | true or false |
columnNamesAsHeader |
CDM sink data flow script example
The associated data flow script is:
CDMSource sink(allowSchemaDrift: true,
validateSchema: false,
entity: 'Product.cdm.json/Product',
format: 'cdm',
entityPath: 'ProductSize',
manifestName: 'ProductSizeManifest',
corpusPath: 'Products',
partitionPath: 'adf',
folderPath: 'ProductSizeData',
fileSystem: 'cdm',
subformat: 'parquet',
corpusStore: 'adlsgen2',
adlsgen2_fileSystem: 'models',
truncate: true,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> CDMSink
Related content
Create a source transformation in mapping data flow.