Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
In this tutorial, you use the Azure portal to create a data factory. Then, you use the Copy Data tool to create a pipeline that incrementally copies new files based on time partitioned file name from Azure Blob storage to Azure Blob storage.
Note
If you're new to Azure Data Factory, see Introduction to Azure Data Factory.
In this tutorial, you perform the following steps:
- Create a data factory.
- Use the Copy Data tool to create a pipeline.
- Monitor the pipeline and activity runs.
Prerequisites
- Azure subscription: If you don't have an Azure subscription, create a trial account before you begin.
- Azure storage account: Use Blob storage as the source and sink data store. If you don't have an Azure storage account, see the instructions in Create a storage account.
Create two containers in Blob storage
Prepare your Blob storage for the tutorial by performing these steps.
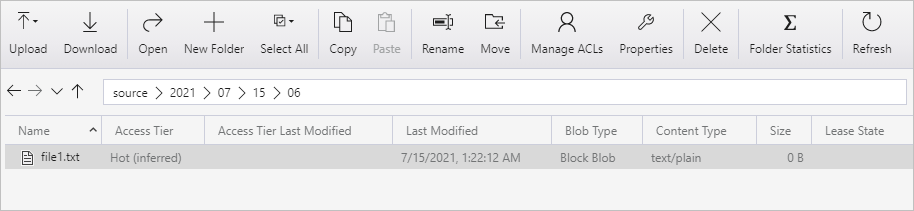
Create a container named source. Create a folder path as 2021/07/15/06 in your container. Create an empty text file, and name it as file1.txt. Upload the file1.txt to the folder path source/2021/07/15/06 in your storage account. You can use various tools to perform these tasks, such as Azure Storage Explorer.
Note
Please adjust the folder name with your UTC time. For example, if the current UTC time is 6:10 AM on July 15, 2021, you can create the folder path as source/2021/07/15/06/ by the rule of source/{Year}/{Month}/{Day}/{Hour}/.
Create a container named destination. You can use various tools to perform these tasks, such as Azure Storage Explorer.
Create a data factory
On the top menu, select Create a resource > Data + Analytics > Data Factory :
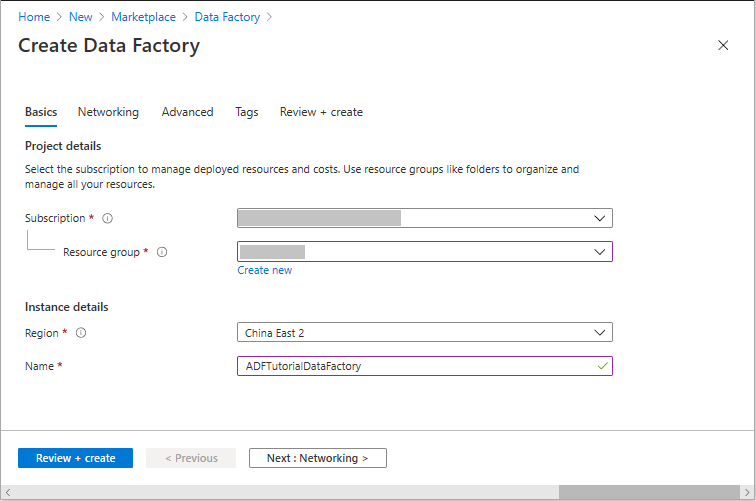
On the New data factory page, under Name, enter ADFTutorialDataFactory.
The name for your data factory must be globally unique. You might receive the following error message:
If you receive an error message about the name value, enter a different name for the data factory. For example, use the name yournameADFTutorialDataFactory. For the naming rules for Data Factory artifacts, see Data Factory naming rules.
Select the Azure subscription in which to create the new data factory.
For Resource Group, take one of the following steps:
a. Select Use existing, and select an existing resource group from the drop-down list.
b. Select Create new, and enter the name of a resource group.
To learn about resource groups, see Use resource groups to manage your Azure resources.
Under location, select the location for the data factory. Only supported locations are displayed in the drop-down list. The data stores (for example, Azure Storage and SQL Database) and computes (for example, Azure HDInsight) that are used by your data factory can be in other locations and regions.
Select Create.
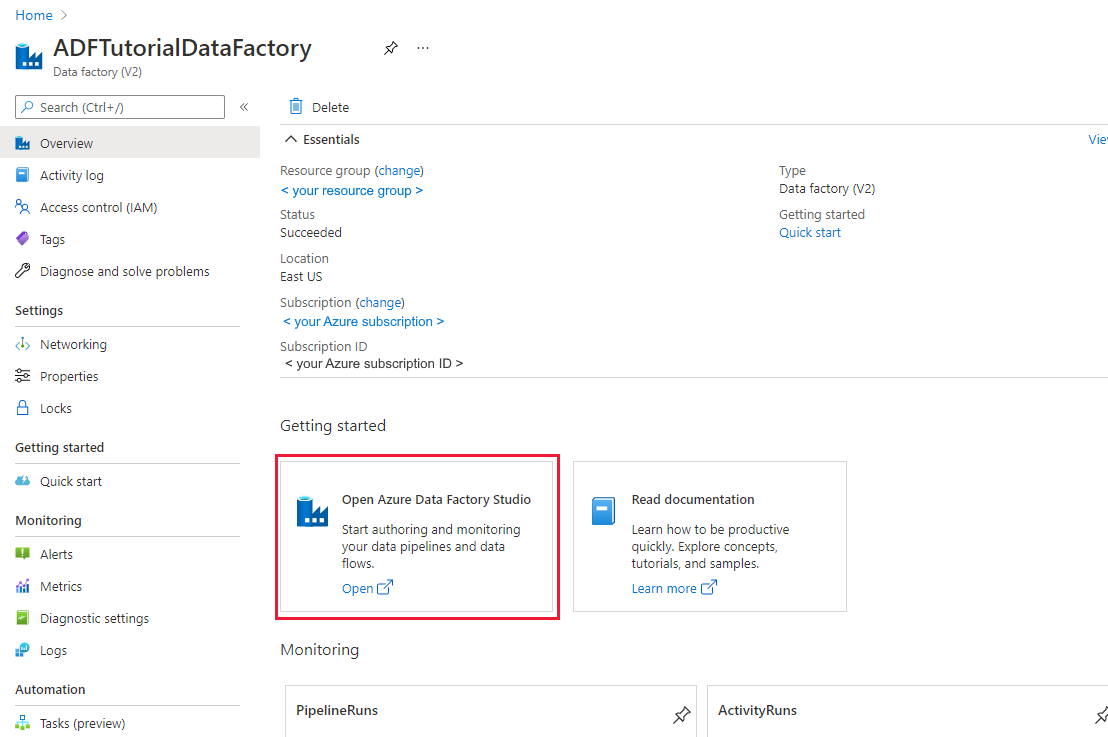
After creation is finished, the Data Factory home page is displayed.
To launch the Azure Data Factory user interface (UI) in a separate tab, select Open on the Open Azure Data Factory Studio tile.
Use the Copy Data tool to create a pipeline
On the Azure Data Factory home page, select the Ingest title to launch the Copy Data tool.
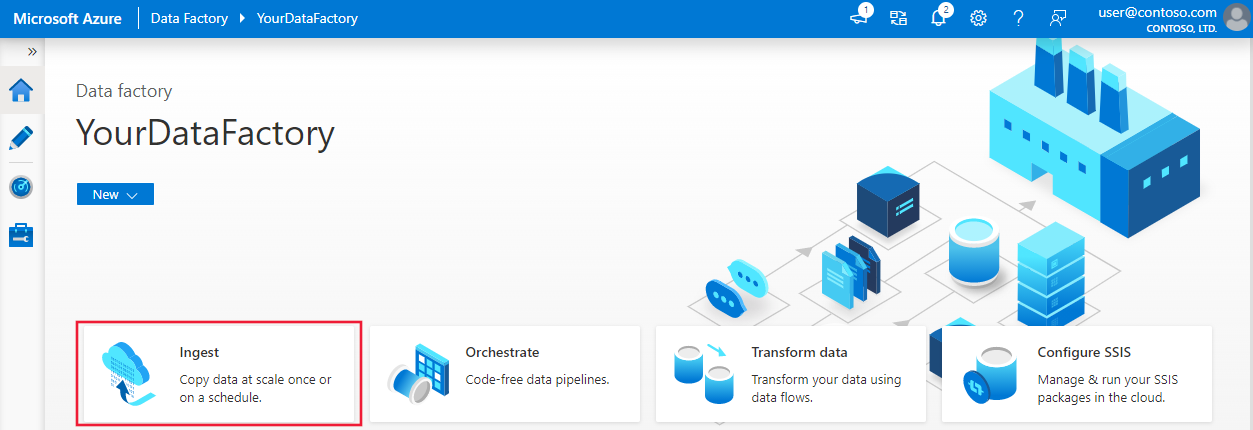
On the Properties page, take the following steps:
Under Task type, choose Built-in copy task.
Under Task cadence or task schedule, select Tumbling window.
Under Recurrence, enter 1 Hour(s).
Select Next.
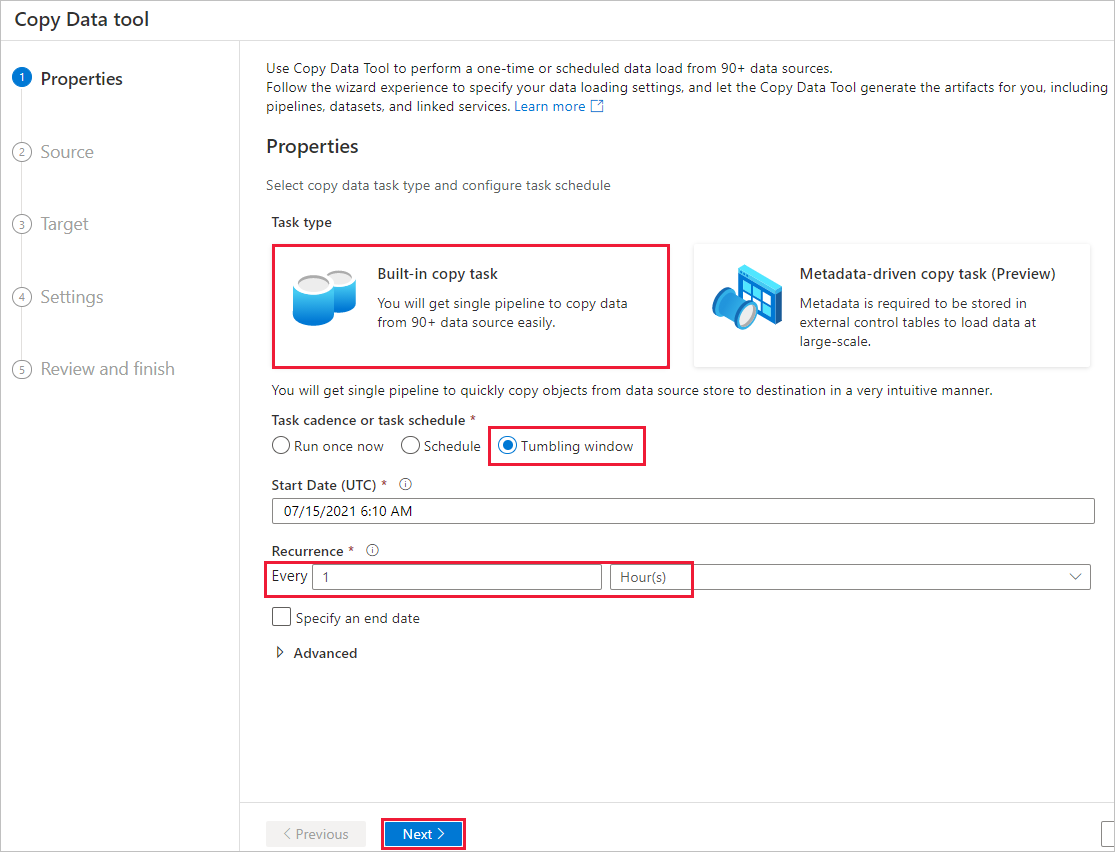
On the Source data store page, complete the following steps:
a. Select + New connection to add a connection.
b. Select Azure Blob Storage from the gallery, and then select Continue.
c. On the New connection (Azure Blob Storage) page, enter a name for the connection. Select your Azure subscription, and select your storage account from the Storage account name list. Test connection and then select Create.
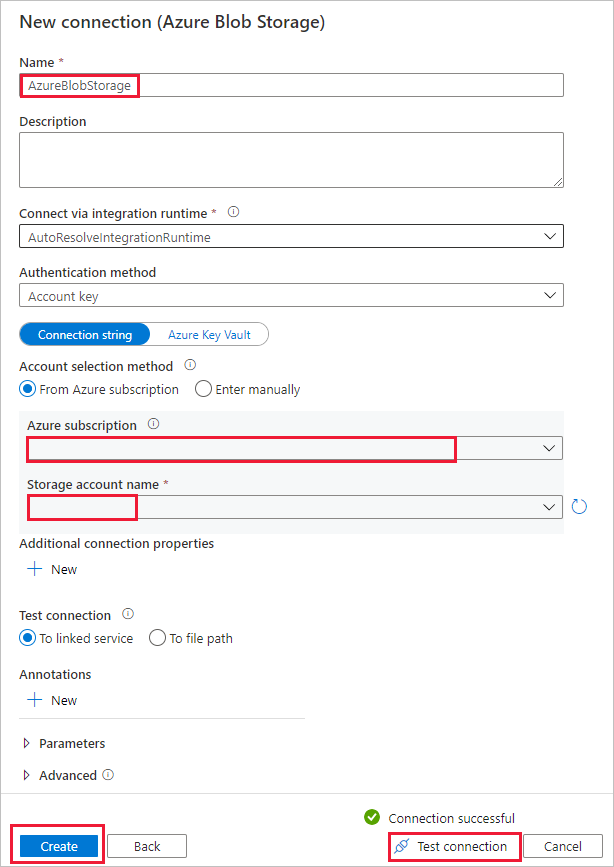
d. On the Source data store page, select the newly created connection in the Connection section.
e. In the File or folder section, browse and select the source container, then select OK.
f. Under File loading behavior, select Incremental load: time-partitioned folder/file names.
g. Write the dynamic folder path as source/{year}/{month}/{day}/{hour}/, and change the format as shown in the following screenshot.
h. Check Binary copy and select Next.
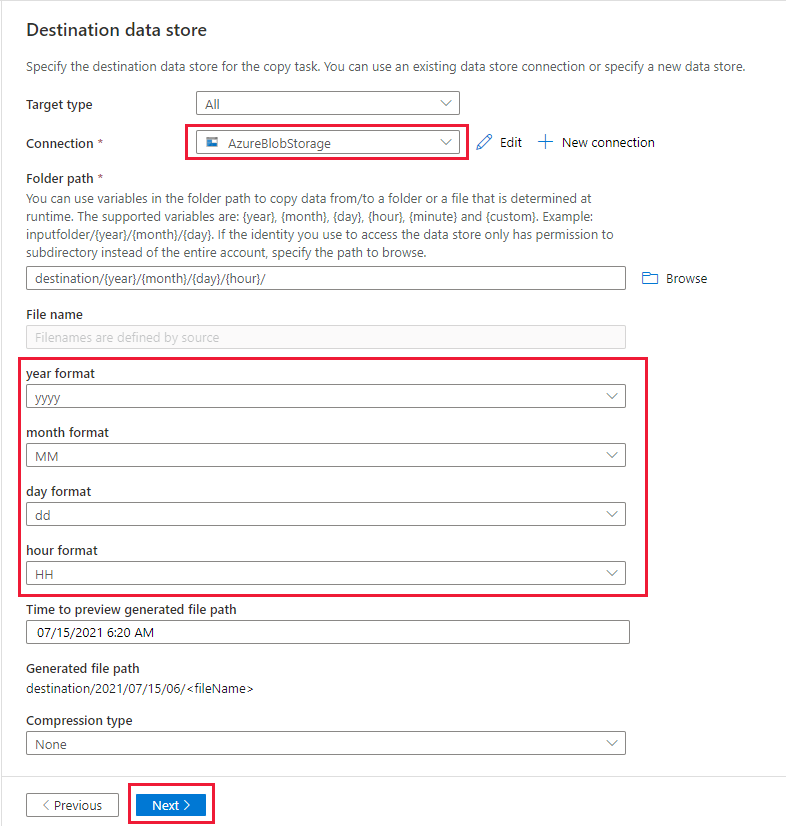
On the Destination data store page, complete the following steps:
Select the AzureBlobStorage, which is the same storage account as data source store.
Browse and select the destination folder, then select OK.
Write the dynamic folder path as destination/{year}/{month}/{day}/{hour}/, and change the format as shown in the following screenshot.
Select Next.
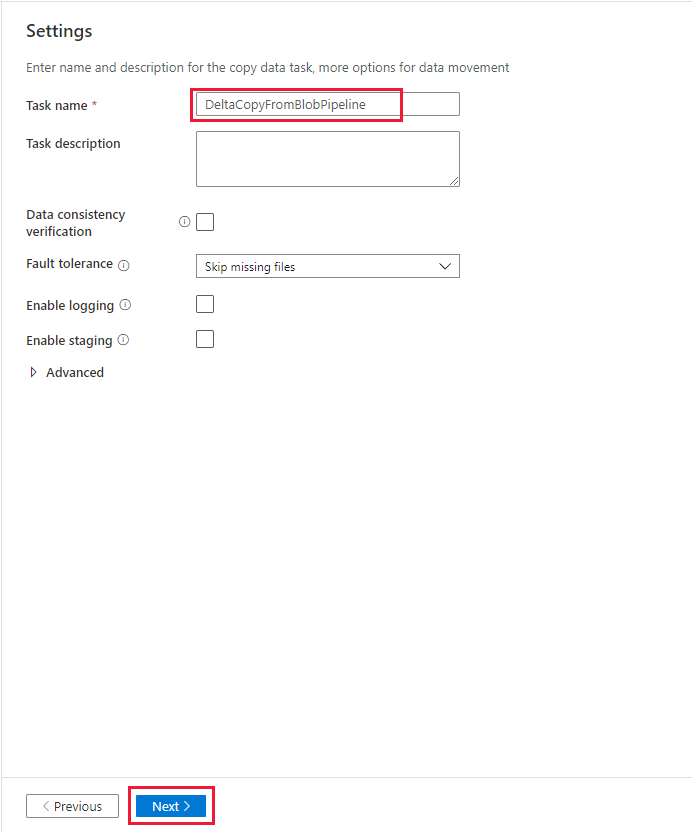
On the Settings page, under Task name, enter DeltaCopyFromBlobPipeline, and then select Next. The Data Factory UI creates a pipeline with the specified task name.
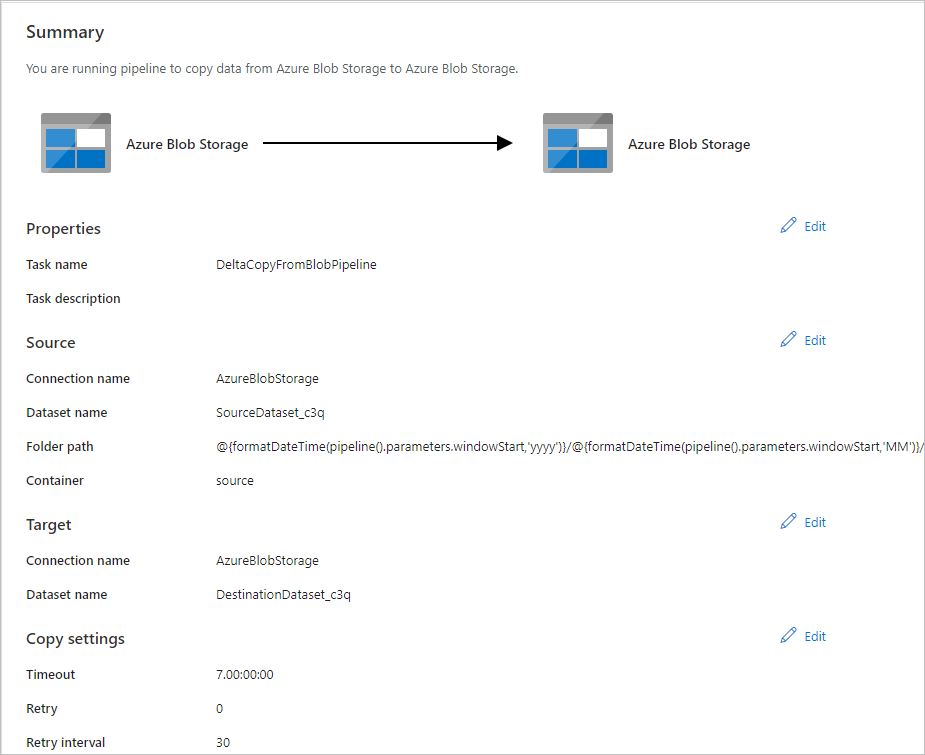
On the Summary page, review the settings, and then select Next.
On the Deployment page, select Monitor to monitor the pipeline (task).
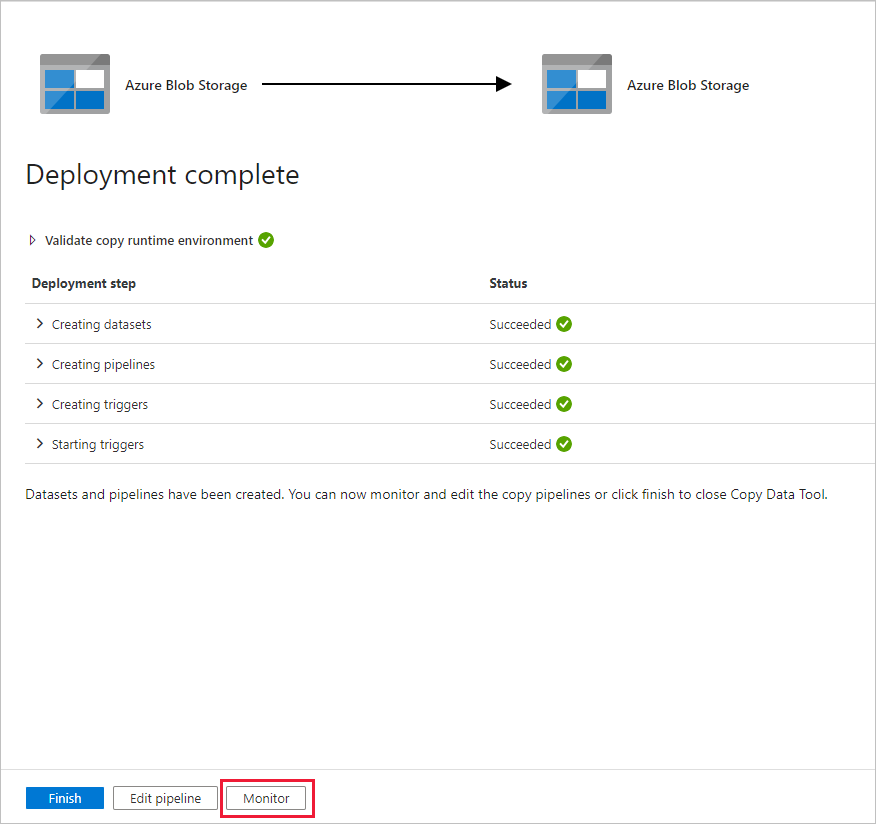
Notice that the Monitor tab on the left is automatically selected. You need wait for the pipeline run when it is triggered automatically (about after one hour). When it runs, select the pipeline name link DeltaCopyFromBlobPipeline to view activity run details or rerun the pipeline. Select Refresh to refresh the list.
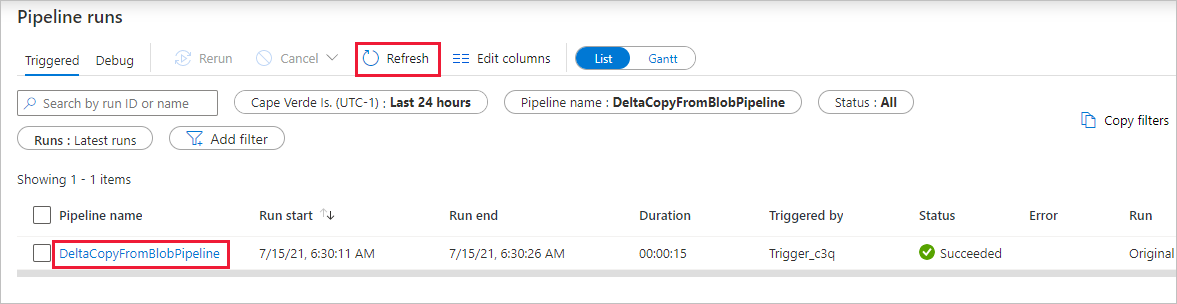
There's only one activity (copy activity) in the pipeline, so you see only one entry. Adjust the column width of the Source and Destination columns (if necessary) to display more details, you can see the source file (file1.txt) has been copied from source/2021/07/15/06/ to destination/2021/07/15/06/ with the same file name.
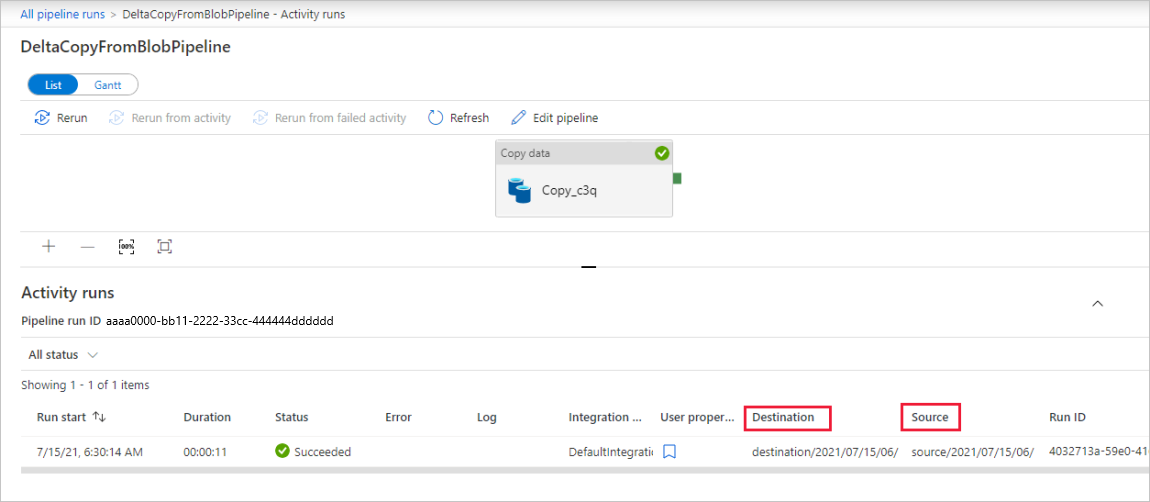
You can also verify the same by using Azure Storage Explorer (https://storageexplorer.com/) to scan the files.
Create another empty text file with the new name as file2.txt. Upload the file2.txt file to the folder path source/2021/07/15/07 in your storage account. You can use various tools to perform these tasks, such as Azure Storage Explorer.
Note
You might be aware that a new folder path is required to be created. Please adjust the folder name with your UTC time. For example, if the current UTC time is 7:30 AM on July. 15th, 2021, you can create the folder path as source/2021/07/15/07/ by the rule of {Year}/{Month}/{Day}/{Hour}/.
To go back to the Pipeline runs view, select All pipelines runs, and wait for the same pipeline being triggered again automatically after another one hour.
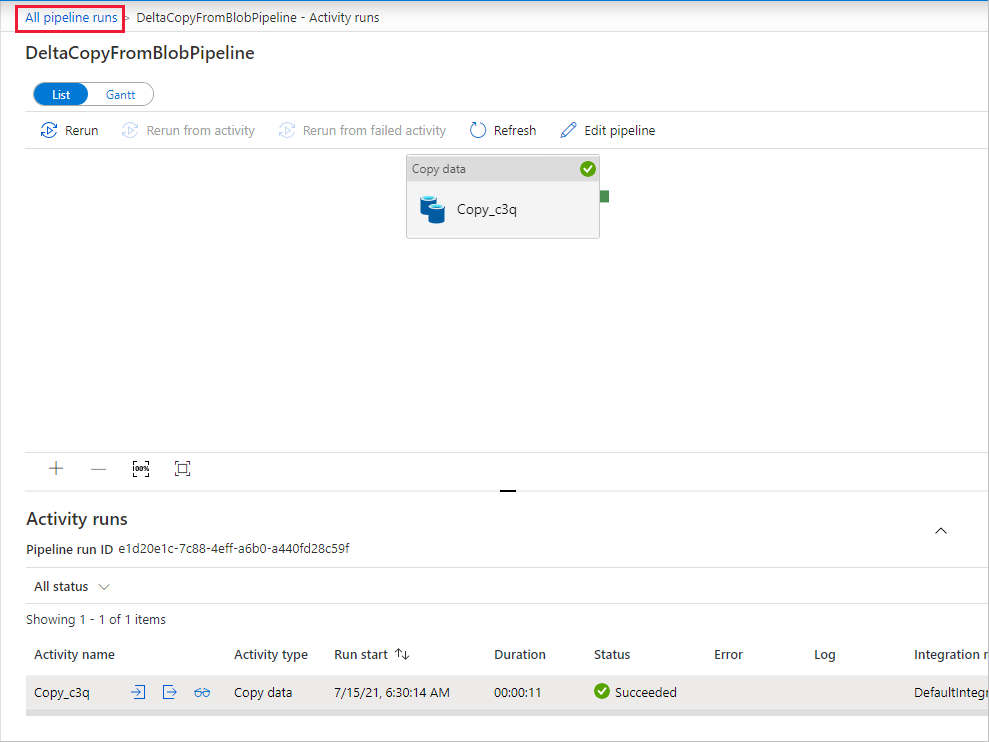
Select the new DeltaCopyFromBlobPipeline link for the second pipeline run when it comes, and do the same to review details. You will see the source file (file2.txt) has been copied from source/2021/07/15/07/ to destination/2021/07/15/07/ with the same file name. You can also verify the same by using Azure Storage Explorer (https://storageexplorer.com/) to scan the files in destination container.
Related content
Advance to the following tutorial to learn about transforming data by using a Spark cluster on Azure: