Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Note
This page uses JSON examples of policy definitions. You can define a policy using JSON, or use the compute policy UI to configure the policy definitions using dropdown menus and other UI elements.
This page is a reference for compute policy definitions, including a list of available policy attributes and limitation types. There are also sample policies you can reference for common use cases.
What are policy definitions?
Policy definitions are individual policy rules expressed in JSON.
A definition can add a rule to any of the attributes controlled with the Clusters API. For example, these definitions set a default autotermination time, forbid users from using pools, and enforce the use of Photon:
{
"autotermination_minutes": {
"type": "unlimited",
"defaultValue": 4320,
"isOptional": true
},
"instance_pool_id": {
"type": "forbidden",
"hidden": true
},
"runtime_engine": {
"type": "fixed",
"value": "PHOTON",
"hidden": true
}
}
There can only be one limitation per attribute. An attribute's path reflects the API attribute name. For nested attributes, the path concatenates the nested attribute names using dots. Attributes that aren't defined in a policy definition won't be limited.
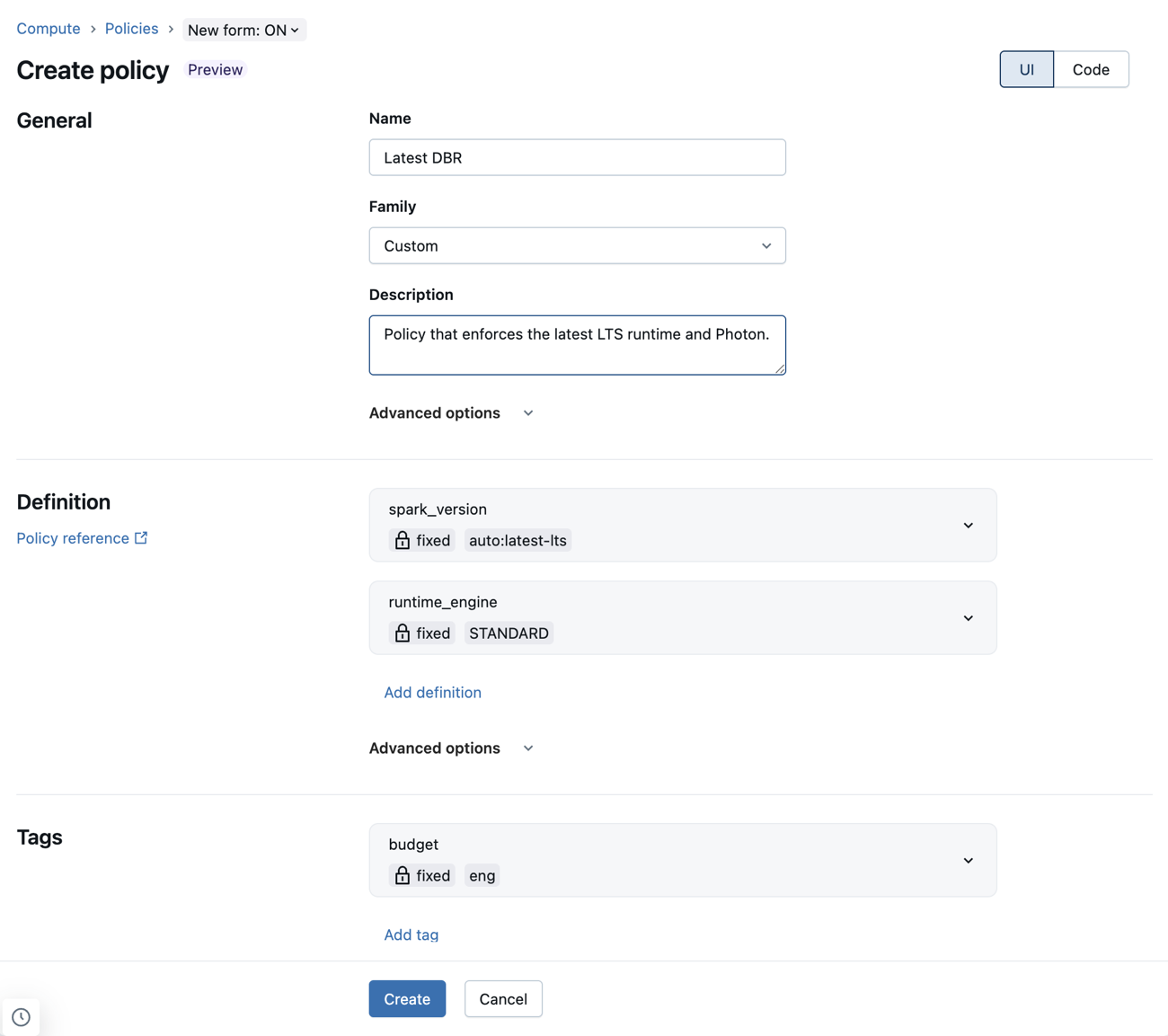
Configure policy definitions using UI elements
The policy form allows you to configure policy definitions using dropdown menus and other UI elements. This means admins can write policies without having to learn or reference the policy syntax.
The form also supports editing the full policy definition directly as JSON. To edit the JSON:
- Click the Edit definition as JSON button in the Definition section's Advanced options to open a JSON editor.
- Click the JSON tab to view the definition JSON. From this tab, you can also click Edit definition as JSON to open the editor.
Additionally, individual JSON rules can be added to the Custom JSON field under Advanced options.
Known limitations using the new policy form
If a policy is not supported by the new compute policy form, any incompatible definitions will appear in the custom JSON field in the Advanced options section. For the fields below, only a subset of valid policies are supported:
- workload_type: Policy must define both
workload_type.clients.notebooksandworkload_type.clients.jobs. Each of these rules must be fixed to eithertrueorfalse. - dbus_per_hour: Only range policies that specify
maxValueand do not specifyminValueare supported. - ssh_public_keys: Only fixed policies are supported. The
ssh_public_keyspolicies must not skip any indices. For example,ssh_public_keys.0,ssh_public_keys.1,ssh_public_keys.2is valid, butssh_public_keys.0,ssh_public_keys.2,ssh_public_keys.3is not valid. - cluster_log_conf: The
cluster_log_conf.pathcannot be an allowlist or blocklist. - init_scripts: Indexed policies (that is,
init_scripts.0.volumes.destination) must be fixed. Wildcard policies (that is,init_scripts.*.volumes.destination) must be forbidden. Indexed policies must not skip any indices.
Supported attributes
Policies support all attributes controlled with the Clusters API. The type of restrictions you can place on attributes may vary per setting based on their type and relation to the UI elements. You cannot use policies to define compute permissions.
You can also use policies to set the max DBUs per hour and cluster type. See Virtual attribute paths.
The following table lists the supported policy attribute paths:
| Attribute path | Type | Description |
|---|---|---|
autoscale.max_workers |
optional number | When hidden, removes the maximum worker number field from the UI. |
autoscale.min_workers |
optional number | When hidden, removes the minimum worker number field from the UI. |
autotermination_minutes |
number | A value of 0 represents no auto termination. When hidden, removes the auto termination checkbox and value input from the UI. |
azure_attributes.availability |
string | Controls whether the compute usage uses on-demand or spot instances (SPOT_AZURE, ON_DEMAND_AZURE, or SPOT_WITH_FALLBACK_AZURE). |
azure_attributes.first_on_demand |
number | Controls how many cluster nodes use on-demand instances, starting with the driver node. For example, a value of 1 sets the driver node to on-demand. A value of 2 sets the driver node and one worker node to on-demand. |
azure_attributes.spot_bid_max_price |
number | Controls the maximum price for Azure spot instances. |
cluster_log_conf.path |
string | The destination URL of the log files. |
cluster_log_conf.type |
string | The type of log destination. DBFS and VOLUMES are the only acceptable values. |
cluster_name |
string | The cluster name. |
custom_tags.* |
string | Control specific tag values by appending the tag name, for example: custom_tags.<mytag>. |
data_security_mode |
string | Sets the access mode of the cluster. Unity Catalog requires SINGLE_USER or USER_ISOLATION (Standard access mode in the UI). A value of NONE means no security features are enabled. |
docker_image.basic_auth.password |
string | The password for the Databricks Container Services image basic authentication. |
docker_image.basic_auth.username |
string | The user name for the Databricks Container Services image basic authentication. |
docker_image.url |
string | Controls the Databricks Container Services image URL. When hidden, removes the Databricks Container Services section from the UI. |
driver_node_type_id |
optional string | When hidden, removes the driver node type selection from the UI. |
driver_node_type_flexibility.alternate_node_type_ids |
string | Specifies alternate node types for the driver node. Only fixed policies are supported. See Flexible node types. |
enable_local_disk_encryption |
boolean | Set to true to enable, or false to disable, encrypting disks that are locally attached to the cluster (as specified through the API). |
init_scripts.*.workspace.destination init_scripts.*.volumes.destination init_scripts.*.abfss.destination init_scripts.*.file.destination |
string | * refers to the index of the init script in the attribute array. See Writing policies for array attributes. |
instance_pool_id |
string | Controls the pool used by worker nodes if driver_instance_pool_id is also defined, or for all cluster nodes otherwise. If you use pools for worker nodes, you must also use pools for the driver node. When hidden, removes pool selection from the UI. |
driver_instance_pool_id |
string | If specified, configures different pool for the driver node than for worker nodes. If not specified, inherits instance_pool_id. If you use pools for worker nodes, you must also use pools for the driver node. When hidden, removes driver pool selection from the UI. |
is_single_node |
boolean | When set to true, the compute must be single node. This attribute is only supported when the user uses the simple form. |
node_type_id |
string | When hidden, removes the worker node type selection from the UI. |
worker_node_type_flexibility.alternate_node_type_ids |
string | Specifies alternate node types for worker nodes. Only fixed policies are supported. See Flexible node types. |
num_workers |
optional number | When hidden, removes the worker number specification from the UI. |
runtime_engine |
string | Determines whether the cluster uses Photon or not. Possible values are PHOTON or STANDARD. |
single_user_name |
string | Controls which users or groups can be assigned to the compute resource. |
spark_conf.* |
optional string | Controls specific configuration values by appending the configuration key name, for example: spark_conf.spark.executor.memory. |
spark_env_vars.* |
optional string | Controls specific Spark environment variable values by appending the environment variable, for example: spark_env_vars.<environment variable name>. |
spark_version |
string | The Spark image version name as specified through the API (the Databricks Runtime). You can also use special policy values that dynamically select the Databricks Runtime. See Special policy values for Databricks Runtime selection. |
use_ml_runtime |
boolean | Controls whether an ML version of the Databricks Runtime must be used. This attribute is only supported when the user uses the simple form. |
workload_type.clients.jobs |
boolean | Defines whether the compute resource can be used for jobs. See Prevent compute from being used with jobs. |
workload_type.clients.notebooks |
boolean | Defines whether the compute resource can be used with notebooks. See Prevent compute from being used with jobs. |
Virtual attribute paths
This table includes two additional synthetic attributes supported by policies. If you use the new policy form, these attributes can be set in the Advanced options section.
| Attribute path | Type | Description |
|---|---|---|
dbus_per_hour |
number | Calculated attribute representing the maximum DBUs a resource can use on an hourly basis including the driver node. This metric is a direct way to control cost at the individual compute level. Use with range limitation. |
cluster_type |
string | Represents the type of cluster that can be created:
Allow or block specified types of compute to be created from the policy. If the all-purpose value is not allowed, the policy is not shown in the all-purpose create compute UI. If the job value is not allowed, the policy is not shown in the create job compute UI. |
Flexible node types
The flexible node types attributes allow you to specify alternate node types that the compute resource can use if the primary node type is unavailable. These attributes have special policy requirements:
- Only fixed policies are supported. All other policy types are not allowed and will be rejected at policy creation time.
- An empty string in the policy maps to an empty list of alternate node types, effectively disabling flexible node types.
Fix to a specific list of node types
Unlike the corresponding Clusters API fields which use an array of strings, the compute policy attributes use a single string value that encodes the array of node types as a comma-separated list. For example:
{
"worker_node_type_flexibility.alternate_node_type_ids": {
"type": "fixed",
"value": "nodeA,nodeB"
}
}
If you use the Clusters API to create a compute resource with an assigned policy, Databricks recommends not setting the worker_node_type_flexibility or driver_node_type_flexibility fields. If you do set these fields, the node types and order of the array must match the policy's comma-separated list exactly or else the compute cannot be created. For example, the policy definition from above would be set as:
"worker_node_type_flexibility": {
"alternate_node_type_ids": ["nodeA", "nodeB"]
}
Disable flexible node types
To disable flexible node types, set the value to an empty string. For example:
{
"worker_node_type_flexibility.alternate_node_type_ids": {
"type": "fixed",
"value": ""
}
}
Special policy values for Databricks Runtime selection
The spark_version attribute supports special values that dynamically map to a Databricks Runtime version based on the current set of supported Databricks Runtime versions.
The following values can be used in the spark_version attribute:
auto:latest: Maps to the latest GA Databricks Runtime version.auto:latest-ml: Maps to the latest Databricks Runtime ML version.auto:latest-lts: Maps to the latest long-term support (LTS) Databricks Runtime version.auto:latest-lts-ml: Maps to the latest LTS Databricks Runtime ML version.auto:prev-major: Maps to the second-latest GA Databricks Runtime version. For example, ifauto:latestis 14.2, thenauto:prev-majoris 13.3.auto:prev-major-ml: Maps to the second-latest GA Databricks Runtime ML version. For example, ifauto:latestis 14.2, thenauto:prev-majoris 13.3.auto:prev-lts: Maps to the second-latest LTS Databricks Runtime version. For example, ifauto:latest-ltsis 13.3, thenauto:prev-ltsis 12.2.auto:prev-lts-ml: Maps to the second-latest LTS Databricks Runtime ML version. For example, ifauto:latest-ltsis 13.3, thenauto:prev-ltsis 12.2.
Note
Using these values does not make the compute auto-update when a new runtime version is released. A user must explicitly edit the compute for the Databricks Runtime version to change.
Supported policy types
This section includes a reference for each of the available policy types. There are two categories of policy types: fixed policies and limiting policies.
Fixed policies prevent user configuration on an attribute. The two types of fixed policies are:
Limiting policies limit a user's options for configuring an attribute. Limiting policies also allow you to set default values and make attributes optional. See Additional limiting policy fields.
Your options for limiting policies are:
Fixed policy
Fixed policies limit the attribute to the specified value. For attribute values other than numeric and boolean, the value must be represented by or convertible to a string.
With fixed policies, you can also hide the attribute from the UI by setting the hidden field to true.
interface FixedPolicy {
type: "fixed";
value: string | number | boolean;
hidden?: boolean;
}
This example policy fixes the Databricks Runtime version and hides the field from the user's UI:
{
"spark_version": { "type": "fixed", "value": "auto:latest-lts", "hidden": true }
}
Forbidden policy
A forbidden policy prevents users from configuring an attribute. Forbidden policies are only compatible with optional attributes.
interface ForbiddenPolicy {
type: "forbidden";
}
This policy forbids attaching pools to the compute for worker nodes. Pools are also forbidden for the driver node, because driver_instance_pool_id inherits the policy.
{
"instance_pool_id": { "type": "forbidden" }
}
Allowlist policy
An allowlist policy specifies a list of values the user can choose between when configuring an attribute.
interface AllowlistPolicy {
type: "allowlist";
values: (string | number | boolean)[];
defaultValue?: string | number | boolean;
isOptional?: boolean;
}
This allowlist example allows the user to select between two Databricks Runtime versions:
{
"spark_version": { "type": "allowlist", "values": ["13.3.x-scala2.12", "12.2.x-scala2.12"] }
}
Force users to select a value from the allowlist
If you don't set a default value for the allowlist policy, the UI defaults to the first value in the allowlist. To force the user to manually select a value, set the default value to something not valid. For example: defaultValue?: "SELECT A VALUE";.
Blocklist policy
The blocklist policy lists disallowed values. Since the values must be exact matches, this policy might not work as expected when the attribute is lenient in how the value is represented (for example, allowing leading and trailing spaces).
interface BlocklistPolicy {
type: "blocklist";
values: (string | number | boolean)[];
defaultValue?: string | number | boolean;
isOptional?: boolean;
}
This example blocks the user from selecting 7.3.x-scala2.12 as the Databricks Runtime.
{
"spark_version": { "type": "blocklist", "values": ["7.3.x-scala2.12"] }
}
Regex policy
A regex policy limits the available values to ones that match the regex. For safety, make sure your regex is anchored to the beginning and end of the string value.
interface RegexPolicy {
type: "regex";
pattern: string;
defaultValue?: string | number | boolean;
isOptional?: boolean;
}
This example limits the Databricks Runtime versions a user can select from:
{
"spark_version": { "type": "regex", "pattern": "13\\.[3456].*" }
}
Range policy
A range policy limits the value to a specified range using the minValue and maxValue fields. The value must be a decimal number.
The numeric limits must be representable as a double floating point value. To indicate lack of a specific limit, you can omit either minValue or maxValue.
interface RangePolicy {
type: "range";
minValue?: number;
maxValue?: number;
defaultValue?: string | number | boolean;
isOptional?: boolean;
}
This example limits the maximum amount of workers to 10:
{
"num_workers": { "type": "range", "maxValue": 10 }
}
Unlimited policy
The unlimited policy is used to make attributes required or to set the default value in the UI.
interface UnlimitedPolicy {
type: "unlimited";
defaultValue?: string | number | boolean;
isOptional?: boolean;
}
This example adds the COST_BUCKET tag to the compute:
{
"custom_tags.COST_BUCKET": { "type": "unlimited" }
}
To set a default value for a Spark configuration variable, but also allow omitting (removing) it:
{
"spark_conf.spark.my.conf": { "type": "unlimited", "isOptional": true, "defaultValue": "my_value" }
}
Additional limiting policy fields
For limiting policy types you can specify two additional fields:
defaultValue- The value that automatically populates in the create compute UI.isOptional- A limiting policy on an attribute automatically makes it required. To make the attribute optional, set theisOptionalfield totrue.
Note
Default values don't automatically get applied to compute created with the Clusters API. To apply default values using the API, add the parameter apply_policy_default_values to the compute definition and set it to true.
This example policy specifies the default value id1 for the pool for worker nodes, but makes it optional. When creating the compute, you can select a different pool or choose not to use one. If driver_instance_pool_id isn't defined in the policy or when creating the compute, the same pool is used for worker nodes and the driver node.
{
"instance_pool_id": { "type": "unlimited", "isOptional": true, "defaultValue": "id1" }
}
Writing policies for array attributes
You can specify policies for array attributes in two ways:
- Generic limitations for all array elements. These limitations use the
*wildcard symbol in the policy path. - Specific limitations for an array element at a specific index. These limitation use a number in the path.
Note
The flexible node types attributes (worker_node_type_flexibility.alternate_node_type_ids and driver_node_type_flexibility.alternate_node_type_ids) are array-type fields in the Clusters API, but they do not follow the wildcard/indexed path pattern documented here. These attributes require a single policy rule that specifies the full list as a comma-separated string. See Flexible node types for details.
For example, for the array attribute init_scripts, the generic paths start with init_scripts.* and
the specific paths with init_scripts.<n>, where <n> is an integer index in the array (starting with 0).
You can combine generic and specific limitations, in which case the generic limitation applies to
each array element that does not have a specific limitation. In each case only one policy limitation will apply.
The following sections show examples of common examples that use array attributes.
Require inclusion-specific entries
You cannot require specific values without specifying the order. For example:
{
"init_scripts.0.volumes.destination": {
"type": "fixed",
"value": "<required-script-1>"
},
"init_scripts.1.volumes.destination": {
"type": "fixed",
"value": "<required-script-2>"
}
}
Require a fixed value of the entire list
{
"init_scripts.0.volumes.destination": {
"type": "fixed",
"value": "<required-script-1>"
},
"init_scripts.*.volumes.destination": {
"type": "forbidden"
}
}
Disallow the use altogether
{
"init_scripts.*.volumes.destination": {
"type": "forbidden"
}
}
Allow entries that follow specific restriction
{
"init_scripts.*.volumes.destination": {
"type": "regex",
"pattern": ".*<required-content>.*"
}
}
Fix a specific set of init scripts
In case of init_scripts paths, the array can contain one of multiple structures for which all possible variants may need to be handled depending on the use case. For example, to require a specific set of init scripts, and disallow any variant of the other version, you can use the following pattern:
{
"init_scripts.0.volumes.destination": {
"type": "fixed",
"value": "<volume-paths>"
},
"init_scripts.1.volumes.destination": {
"type": "fixed",
"value": "<volume-paths>"
},
"init_scripts.*.workspace.destination": {
"type": "forbidden"
},
"init_scripts.*.abfss.destination": {
"type": "forbidden"
},
"init_scripts.*.file.destination": {
"type": "forbidden"
}
}
Policy examples
This section includes policy examples you can use as references for creating your own policies. You can also use the Azure Databricks-provided policy families as templates for common policy use cases.
- General compute policy
- Define limits on Lakeflow Spark Declarative Pipelines compute
- Simple medium-sized policy
- Job-only policy
- External metastore policy
- Prevent compute from being used with jobs
- Remove autoscaling policy
- Custom tag enforcement
General compute policy
A general purpose compute policy meant to guide users and restrict some functionality, while requiring tags, restricting the maximum number of instances, and enforcing timeout.
{
"instance_pool_id": {
"type": "forbidden",
"hidden": true
},
"spark_version": {
"type": "regex",
"pattern": "12\\.[0-9]+\\.x-scala.*"
},
"node_type_id": {
"type": "allowlist",
"values": ["Standard_L4s", "Standard_L8s", "Standard_L16s"],
"defaultValue": "Standard_L16s_v2"
},
"driver_node_type_id": {
"type": "fixed",
"value": "Standard_L16s_v2",
"hidden": true
},
"autoscale.min_workers": {
"type": "fixed",
"value": 1,
"hidden": true
},
"autoscale.max_workers": {
"type": "range",
"maxValue": 25,
"defaultValue": 5
},
"autotermination_minutes": {
"type": "fixed",
"value": 30,
"hidden": true
},
"custom_tags.team": {
"type": "fixed",
"value": "product"
}
}
Define limits on Lakeflow Spark Declarative Pipelines compute
Note
When using policies to configure Lakeflow Spark Declarative Pipelines compute, Databricks recommends applying a single policy to both the default and maintenance compute.
To configure a policy for a pipeline compute, create a policy with the cluster_type field set to dlt. The following example creates a minimal policy for a Lakeflow Spark Declarative Pipelines compute:
{
"cluster_type": {
"type": "fixed",
"value": "dlt"
},
"num_workers": {
"type": "unlimited",
"defaultValue": 3,
"isOptional": true
},
"node_type_id": {
"type": "unlimited",
"isOptional": true
},
"spark_version": {
"type": "unlimited",
"hidden": true
}
}
Simple medium-sized policy
Allows users to create a medium-sized compute with minimal configuration. The only required field at creation time is compute name; the rest is fixed and hidden.
{
"instance_pool_id": {
"type": "forbidden",
"hidden": true
},
"spark_conf.spark.databricks.cluster.profile": {
"type": "forbidden",
"hidden": true
},
"autoscale.min_workers": {
"type": "fixed",
"value": 1,
"hidden": true
},
"autoscale.max_workers": {
"type": "fixed",
"value": 10,
"hidden": true
},
"autotermination_minutes": {
"type": "fixed",
"value": 60,
"hidden": true
},
"node_type_id": {
"type": "fixed",
"value": "Standard_L8s_v2",
"hidden": true
},
"driver_node_type_id": {
"type": "fixed",
"value": "Standard_L8s_v2",
"hidden": true
},
"spark_version": {
"type": "fixed",
"value": "auto:latest-ml",
"hidden": true
},
"custom_tags.team": {
"type": "fixed",
"value": "product"
}
}
Job-only policy
Allows users to create job compute to run jobs. Users cannot create all-purpose compute using this policy.
{
"cluster_type": {
"type": "fixed",
"value": "job"
},
"dbus_per_hour": {
"type": "range",
"maxValue": 100
},
"instance_pool_id": {
"type": "forbidden",
"hidden": true
},
"num_workers": {
"type": "range",
"minValue": 1
},
"node_type_id": {
"type": "regex",
"pattern": "Standard_[DLS]*[1-6]{1,2}_v[2,3]"
},
"driver_node_type_id": {
"type": "regex",
"pattern": "Standard_[DLS]*[1-6]{1,2}_v[2,3]"
},
"spark_version": {
"type": "unlimited",
"defaultValue": "auto:latest-lts"
},
"custom_tags.team": {
"type": "fixed",
"value": "product"
}
}
External metastore policy
Allows users to create compute with an admin-defined metastore already attached. This is useful to allow users to create their own compute without requiring additional configuration.
{
"spark_conf.spark.hadoop.javax.jdo.option.ConnectionURL": {
"type": "fixed",
"value": "jdbc:sqlserver://<jdbc-url>"
},
"spark_conf.spark.hadoop.javax.jdo.option.ConnectionDriverName": {
"type": "fixed",
"value": "com.microsoft.sqlserver.jdbc.SQLServerDriver"
},
"spark_conf.spark.databricks.delta.preview.enabled": {
"type": "fixed",
"value": "true"
},
"spark_conf.spark.hadoop.javax.jdo.option.ConnectionUserName": {
"type": "fixed",
"value": "<metastore-user>"
},
"spark_conf.spark.hadoop.javax.jdo.option.ConnectionPassword": {
"type": "fixed",
"value": "<metastore-password>"
}
}
Prevent compute from being used with jobs
This policy prevents users from using the compute to run jobs. Users will only be able to use the compute with notebooks.
{
"workload_type.clients.notebooks": {
"type": "fixed",
"value": true
},
"workload_type.clients.jobs": {
"type": "fixed",
"value": false
}
}
Remove autoscaling policy
This policy disables autoscaling and allows the user to set the number of workers within a given range.
{
"num_workers": {
"type": "range",
"maxValue": 25,
"minValue": 1,
"defaultValue": 5
}
}
Custom tag enforcement
To add a compute tag rule to a policy, use the custom_tags.<tag-name> attribute.
For example, any user using this policy needs to fill in a COST_CENTER tag with 9999, 9921, or 9531 for the compute to launch:
{ "custom_tags.COST_CENTER": { "type": "allowlist", "values": ["9999", "9921", "9531"] } }