Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Note
The manual tuning recommendations in this article do not apply to Unity Catalog managed tables, which use automatic file size tuning. For new tables, use Unity Catalog managed tables with default settings.
In Databricks Runtime 13.3 and above, Databricks recommends using clustering for table layout. See Use liquid clustering for tables.
In Databricks Runtime 10.4 LTS and above, auto compaction and optimized writes are always enabled for MERGE, UPDATE, and DELETE operations. You cannot disable this functionality.
There are options for manually or automatically configuring the target file size for writes and for OPTIMIZE operations. Azure Databricks automatically tunes many of these settings, and enables features that automatically improve table performance by seeking to right-size files.
For Unity Catalog managed tables, Databricks tunes most of these configurations automatically if you're using a SQL warehouse or Databricks Runtime 11.3 LTS or above.
If you're upgrading a workload from Databricks Runtime 10.4 LTS or below, see Upgrade to background auto compaction.
When to run OPTIMIZE
Auto compaction and optimized writes each reduce small file problems, but are not a full replacement for OPTIMIZE. Especially for tables larger than 1 TB, Databricks recommends running OPTIMIZE on a schedule to further consolidate files. Databricks recommends liquid clustering for enhanced data skipping. When liquid clustering is enabled, OPTIMIZE automatically reorganizes data by the clustering keys. See Use liquid clustering for tables.
What is auto optimize on Azure Databricks?
The term auto optimize is sometimes used to describe functionality controlled by the settings autoOptimize.autoCompact and autoOptimize.optimizeWrite. This term has been retired in favor of describing each setting individually. See Auto compaction and Optimized writes.
Auto compaction
Auto compaction combines small files within table partitions to reduce small file problems. It runs synchronously on the cluster that performs the write, after the write succeeds, and only compacts files that haven't been compacted previously.
Auto compaction and predictive optimization are independent features that can be used separately or together. Auto compaction runs on the cluster performing the write, while predictive optimization runs maintenance operations asynchronously using serverless compute.
Use the following settings to configure auto compaction:
| Setting | Delta | Iceberg | Description |
|---|---|---|---|
| Enable auto compaction (table property) | autoOptimize.autoCompact |
autoOptimize.autoCompact |
Enables auto compaction at the table level. |
| Enable auto compaction (Spark session) | spark.databricks.delta.autoCompact.enabled |
spark.databricks.iceberg.autoCompact.enabled |
Enables auto compaction at the session level. |
| Maximum output file size | spark.databricks.delta.autoCompact.maxFileSize |
spark.databricks.iceberg.autoCompact.maxFileSize |
Controls the target output file size. |
| Minimum files to trigger compaction | spark.databricks.delta.autoCompact.minNumFiles |
spark.databricks.iceberg.autoCompact.minNumFiles |
Sets the minimum number of small files required in a partition or table to trigger auto compaction. |
These settings accept the following options:
| Options | Behavior |
|---|---|
auto (recommended) |
Tunes target file size while respecting other autotuning functionality. Requires Databricks Runtime 10.4 LTS or above. |
legacy |
Alias for true. Requires Databricks Runtime 10.4 LTS or above. |
true |
Use 128 MB as the target file size. No dynamic sizing. |
false |
Turns off auto compaction. Can be set at the session level to override auto compaction for all tables modified in the workload. |
Note
Azure Databricks recommends using autotuning to control output file size based on table size. See Autotune file size based on table size.
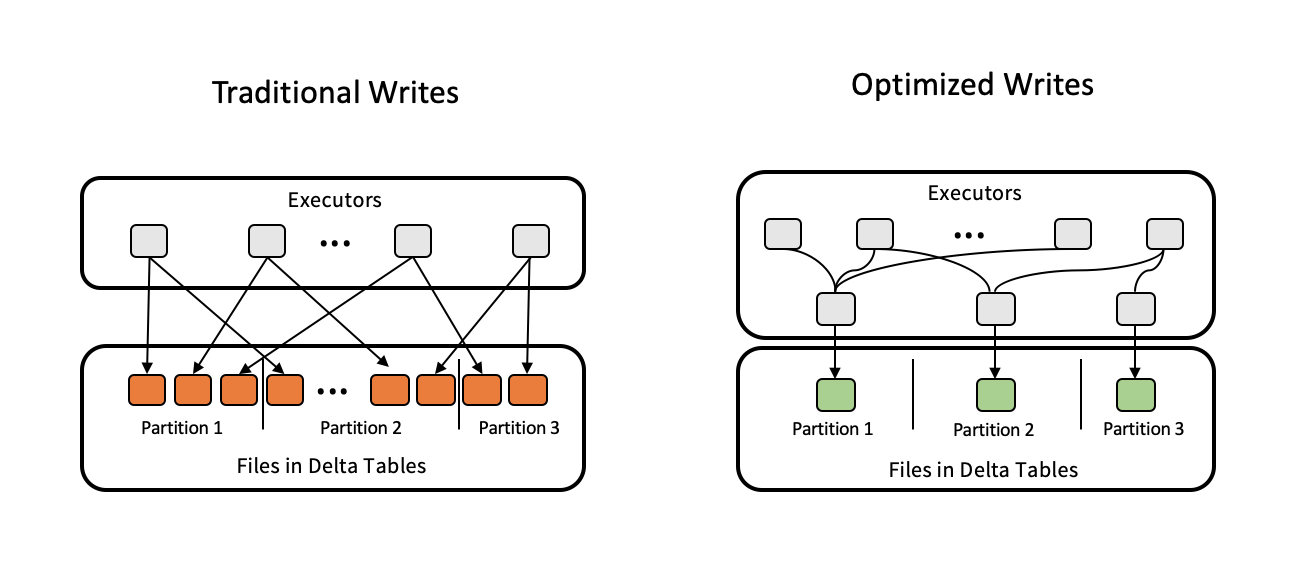
Optimized writes
Optimized writes improve file size as data is written and benefit subsequent reads on the table.
Optimized writes are most effective for partitioned tables, as they reduce the number of small files written to each partition. Writing fewer large files is more efficient than writing many small files, but you might still see an increase in write latency because data is shuffled before being written.
The following image demonstrates how optimized writes works:
Note
You might have code that runs coalesce(n) or repartition(n) just before you write out your data to control the number of files written. Optimized writes eliminates the need to use this pattern.
Optimized writes are enabled by default for the following operations in Databricks Runtime 9.1 LTS and above:
MERGEUPDATEwith subqueriesDELETEwith subqueries
Optimized writes are also enabled for CTAS statements and INSERT operations when using SQL warehouses. In Databricks Runtime 13.3 LTS and above, all tables registered in Unity Catalog have optimized writes enabled for CTAS statements and INSERT operations for partitioned tables.
Optimized writes can be enabled at the table or session level using the following settings:
- Table property:
autoOptimize.optimizeWrite - SparkSession setting:
spark.databricks.delta.optimizeWrite.enabled(Delta) orspark.databricks.iceberg.optimizeWrite.enabled(Iceberg)
These settings accept the following options:
| Options | Behavior |
|---|---|
true |
Use 128 MB as the target file size. |
false |
Turns off optimized writes. Can be set at the session level to override auto compaction for all tables modified in the workload. |
Set a target file size
If you want to tune the size of files in your table, set the table property targetFileSize to the desired size. When set, all data layout optimization operations make a best-effort attempt to generate files of the specified size, including optimize,liquid clustering, auto compaction, and optimized writes.
Note
When using Unity Catalog managed tables and SQL warehouses or Databricks Runtime 11.3 LTS and above, only OPTIMIZE commands respect the targetFileSize setting.
| Property | Description |
|---|---|
delta.targetFileSize (Delta)iceberg.targetFileSize (Iceberg) |
Type: Size in bytes or higher units. Description: The target file size. For example, 104857600 (bytes) or 100mb.Default value: None |
For existing tables, you can set and unset properties using the SQL command ALTER TABLE SET TBL PROPERTIES. You can also set these properties automatically when creating new tables using Spark session configurations. See Table properties reference for details.
Autotune file size based on table size
To minimize the need for manual tuning, Azure Databricks automatically tunes the file size of tables based on the size of the table. Azure Databricks uses smaller file sizes for smaller tables and larger file sizes for larger tables so that the number of files in the table does not grow too large. Azure Databricks does not autotune tables that you have tuned with a specific target size.
The target file size is based on the current size of the table. For tables smaller than 2.56 TB, the autotuned target file size is 256 MB. For tables with a size between 2.56 TB and 10 TB, the target size will grow linearly from 256 MB to 1 GB. For tables larger than 10 TB, the target file size is 1 GB.
Note
When the target file size for a table grows, existing files are not re-optimized into larger files by the OPTIMIZE command. A large table can therefore always have some files that are smaller than the target size. If it is required to optimize those smaller files into larger files as well, you can configure a fixed target file size for the table using the targetFileSize table property.
When a table is written incrementally, the target file sizes and file counts will be close to the following numbers, based on table size. The file counts in this table are only an example. The actual results will be different depending on many factors.
| Table size | Target file size | Approximate number of files in table |
|---|---|---|
| 10 GB | 256 MB | 40 |
| 1 TB | 256 MB | 4096 |
| 2.56 TB | 256 MB | 10240 |
| 3 TB | 307 MB | 12108 |
| 5 TB | 512 MB | 17339 |
| 7 TB | 716 MB | 20784 |
| 10 TB | 1 GB | 24437 |
| 20 TB | 1 GB | 34437 |
| 50 TB | 1 GB | 64437 |
| 100 TB | 1 GB | 114437 |
Limit rows written in a data file
Occasionally, tables with narrow data might encounter an error where the number of rows in a given data file exceeds the support limits of the Parquet format. To avoid this error, you can use the SQL session configuration spark.sql.files.maxRecordsPerFile to specify the maximum number of records to write to a single file for a table. Specifying a value of zero or a negative value represents no limit.
In Databricks Runtime 11.3 LTS and above, you can also use the DataFrameWriter option maxRecordsPerFile when using the DataFrame APIs to write to a table. When maxRecordsPerFile is specified, the value of the SQL session configuration spark.sql.files.maxRecordsPerFile is ignored.
Note
Databricks does not recommend using this option unless it is necessary to avoid the aforementioned error. This setting might still be necessary for some Unity Catalog managed tables with very narrow data.
Upgrade to background auto compaction
Background auto compaction is available for Unity Catalog managed tables in Databricks Runtime 11.3 LTS and above. When migrating a legacy workload or table, do the following:
- Remove the Spark config
spark.databricks.delta.autoCompact.enabled(Delta) orspark.databricks.iceberg.autoCompact.enabled(Iceberg) from cluster or notebook configuration settings. - For each table, run
ALTER TABLE <table_name> UNSET TBLPROPERTIES (delta.autoOptimize.autoCompact)(Delta) orALTER TABLE <table_name> UNSET TBLPROPERTIES (iceberg.autoOptimize.autoCompact)(Iceberg) to remove any legacy auto compaction settings.
After removing these legacy configurations, you should see background auto compaction triggered automatically for all Unity Catalog managed tables.