Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Important
This documentation has been retired and might not be updated. The products, services, or technologies mentioned in this content are no longer supported.
Note
MLlib automated MLflow tracking is deprecated on clusters that run Databricks Runtime 10.1 ML and above, and it is disabled by default on clusters running Databricks Runtime 10.2 ML and above. Instead, use MLflow PySpark ML autologging by calling mlflow.pyspark.ml.autolog(), which is enabled by default with Databricks Autologging.
To use the old MLlib automated MLflow tracking in Databricks Runtime 10.2 ML or above, enable it by setting the Spark configurations spark.databricks.mlflow.trackMLlib.enabled true and spark.databricks.mlflow.autologging.enabled false.
MLflow is an open source platform for managing the end-to-end machine learning lifecycle. MLflow supports tracking for machine learning model tuning in Python, R, and Scala. For Python notebooks only, Databricks Runtime release notes versions and compatibility and Databricks Runtime for Machine Learning support automated MLflow Tracking for Apache Spark MLlib model tuning.
With MLlib automated MLflow tracking, when you run tuning code that uses CrossValidator or TrainValidationSplit, hyperparameters and evaluation metrics are automatically logged in MLflow. Without automated MLflow tracking, you must make explicit API calls to log to MLflow.
Manage MLflow runs
CrossValidator or TrainValidationSplit log tuning results as nested MLflow runs:
- Main or parent run: The information for
CrossValidatororTrainValidationSplitis logged to the main run. If there is an active run already, information is logged to this active run and the active run is not stopped. If there is no active run, MLflow creates a new run, logs to it, and ends the run before returning. - Child runs: Each hyperparameter setting tested and the corresponding evaluation metric are logged to a child run under the main run.
When calling fit(), Azure Databricks recommends active MLflow run management; that is, wrap the call to fit() inside a "with mlflow.start_run():" statement.
This ensures that the information is logged under its own MLflow main run, and makes it easier to log additional tags, parameters, or metrics to that run.
Note
When fit() is called multiple times within the same active MLflow run, it logs those multiple runs to the same main run. To resolve name conflicts for MLflow parameters and tags, MLflow appends a UUID to names with conflicts.
The following Python notebook demonstrates automated MLflow tracking.
Automated MLflow tracking notebook
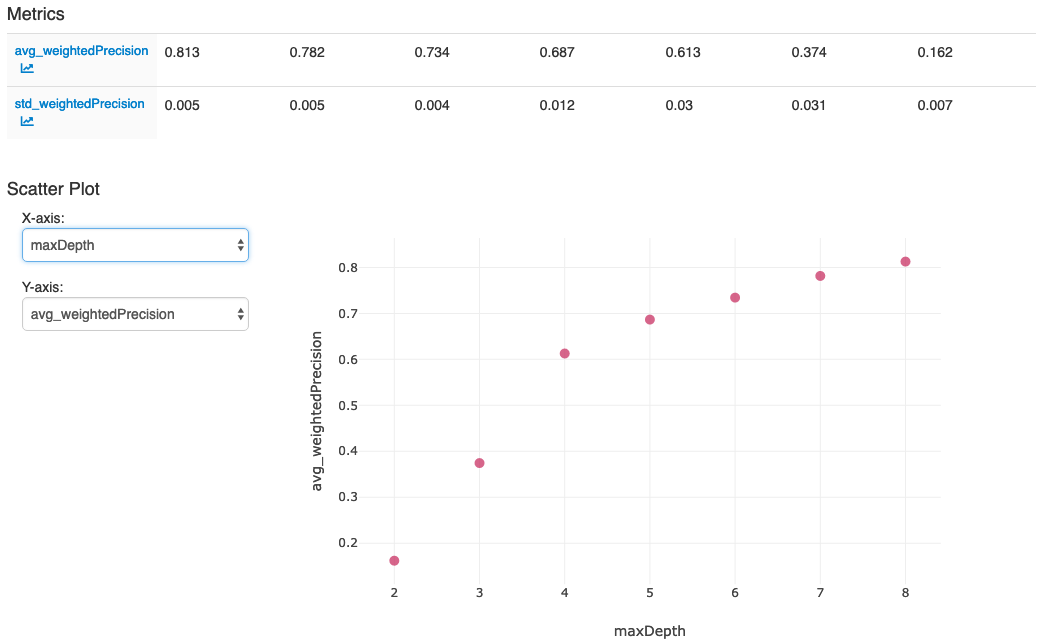
After you perform the actions in the last cell in the notebook, your MLflow UI should display: