Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
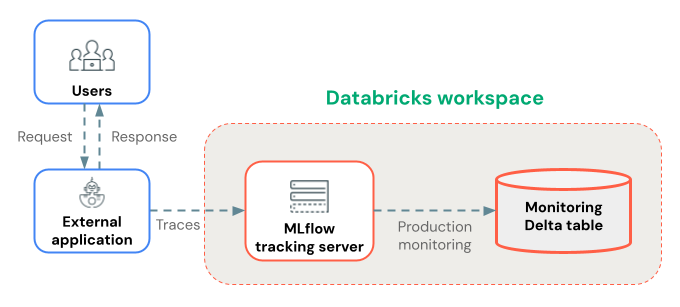
MLflow Tracing provides comprehensive observability for production GenAI agents deployed outside of Databricks by capturing execution details and sending them to your Databricks workspace, where you can view them in the MLflow UI.
This page covers deploying agents outside of Databricks with tracing enabled. If your agent is deployed using Databricks Model Serving, see Deploy with Custom Agents (recommended).
Prerequisites
Install the required packages. The following table describes your options:
| Package | Recommended use case | Benefits |
|---|---|---|
mlflow-tracing Python SDK or TypeScript SDK |
Production deployments | Minimal dependencies for lean, fast deployments Performance optimized for high-volume tracing Focused on client-side tracing for production monitoring |
mlflow[databricks] |
Development and experimentation | Full MLflow experimentation feature set (UI, LLM-as-a-judge, dev tools, and more) Includes all development tools and utilities |
## Install mlflow-tracing for production deployment tracing
%pip install --upgrade "mlflow-tracing==3.1.0"
## Install mlflow for experimentation and development
%pip install --upgrade "mlflow[databricks]==3.1.0"
Basic tracing setup
Configure your application deployment to connect to your Databricks workspace so Databricks can collect traces.
Configure the following environment variables:
# Required: Set the Databricks workspace host and authentication token
export DATABRICKS_HOST="https://your-workspace.cloud.databricks.com"
export DATABRICKS_TOKEN="your-databricks-token"
# Required: Set MLflow Tracking URI to "databricks" to log to Databricks
export MLFLOW_TRACKING_URI=databricks
# Required: Configure the experiment name for organizing traces (must be a workspace path)
export MLFLOW_EXPERIMENT_NAME="/Shared/production-genai-app"
Deployment examples
After the environment variables are set, pass them to your application. Click the tabs to see how to pass the connection details to different frameworks.
Docker
For Docker deployments, pass the environment variables through the container configuration:
# Dockerfile
FROM python:3.11-slim
# Install dependencies
COPY requirements.txt .
RUN pip install -r requirements.txt
# Copy application code
COPY . /app
WORKDIR /app
# Set default environment variables (can be overridden at runtime)
ENV DATABRICKS_HOST=""
ENV DATABRICKS_TOKEN=""
ENV MLFLOW_TRACKING_URI=databricks
ENV MLFLOW_EXPERIMENT_NAME="/Shared/production-genai-app"
CMD ["python", "app.py"]
Run the container with environment variables:
docker run -d \
-e DATABRICKS_HOST="https://your-workspace.cloud.databricks.com" \
-e DATABRICKS_TOKEN="your-databricks-token" \
-e MLFLOW_TRACKING_URI=databricks \
-e MLFLOW_EXPERIMENT_NAME="/Shared/production-genai-app" \
-e APP_VERSION="1.0.0" \
your-app:latest
Kubernetes
For Kubernetes deployments, pass the environment variables using ConfigMaps and Secrets:
# configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: databricks-config
data:
DATABRICKS_HOST: 'https://your-workspace.cloud.databricks.com'
MLFLOW_TRACKING_URI: databricks
MLFLOW_EXPERIMENT_NAME: '/Shared/production-genai-app'
---
# secret.yaml
apiVersion: v1
kind: Secret
metadata:
name: databricks-secrets
type: Opaque
stringData:
DATABRICKS_TOKEN: 'your-databricks-token'
---
# deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: genai-app
spec:
template:
spec:
containers:
- name: app
image: your-app:latest
envFrom:
- configMapRef:
name: databricks-config
- secretRef:
name: databricks-secrets
env:
- name: APP_VERSION
value: '1.0.0'
Verify trace collection
After deploying your app, verify that traces are collected properly:
import mlflow
from mlflow.client import MlflowClient
import os
# Ensure MLflow is configured for Databricks
mlflow.set_tracking_uri("databricks")
# Check connection to MLflow server
client = MlflowClient()
try:
# List recent experiments to verify connectivity
experiments = client.search_experiments()
print(f"Connected to MLflow. Found {len(experiments)} experiments.")
# Check if traces are being logged
traces = mlflow.search_traces(
experiment_names=[os.getenv("MLFLOW_EXPERIMENT_NAME", "/Shared/production-genai-app")],
max_results=5
)
print(f"Found {len(traces)} recent traces.")
except Exception as e:
print(f"Error connecting to MLflow: {e}")
print(f"Check your authentication and connectivity")
Store traces long-term with Production Monitoring
After traces are logged to your MLflow experiment, you can store them long-term in Delta tables using Production Monitoring (in beta).
Benefits of Production Monitoring for trace storage:
- Durable storage: Store traces in Delta tables for long-term retention beyond the MLflow experiment artifact lifecycle.
- No trace size limits: Unlike alternative storage methods, Production Monitoring handles traces of any size.
- Automated quality assessment: Run MLflow scorers on production traces to continuously monitor application quality.
- Fast sync: Traces sync to Delta tables approximately every 15 minutes.
Additional resources
- View traces in the Databricks MLflow UI - View traces in the MLflow UI.
- Production monitoring - Store traces in Delta tables for long-term retention and automatically evaluate with scorers.
- Add context to traces - Attach user or session IDs, custom tags, or user feedback for better debugging and insights.