Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
These features and Azure Databricks platform improvements were released in February 2019.
Note
In most cases, the release date and content listed below only correspond to actual deployment of the Azure Public Cloud.
It provide the evolution history of Azure Databricks service on Azure Public Cloud for your reference, which may not be consistent with the actual deployment on Azure operated by 21Vianet.
Note
Releases are staged. Your Azure Databricks account may not be updated until up to a week after the initial release date.
Databricks Light generally available
February 26 - March 5, 2019: Version 2.92
Databricks Light (also known as Data Engineering Light) is now available. Databricks Light is the Databricks packaging of the open source Apache Spark runtime. It provides a runtime option for jobs that don't need the advanced performance, reliability, or autoscaling benefits provided by Databricks Runtime. You can select Databricks Light only when you create a cluster to run a JAR, Python, or spark-submit job; you cannot select this runtime for clusters on which you run interactive or notebook job workloads. See Databricks Light.
Managed MLflow on Azure Databricks Public Preview
February 26 - March 5, 2019: Version 2.92
MLflow is an open source platform for managing the end-to-end machine learning lifecycle. It tackles three primary functions:
- Tracking experiments to record and compare parameters and results.
- Managing and deploying models from a variety of ML libraries to a variety of model serving and inference platforms.
- Packaging ML code in a reusable, reproducible form to share with other data scientists or transfer to production.
Azure Databricks now provides a fully managed and hosted version of MLflow integrated with enterprise security features, high availability, and other Azure Databricks workspace features such as experiment management, run management, and notebook revision capture. MLflow on Azure Databricks offers an integrated experience for tracking and securing machine learning model training runs and running machine learning projects. By using managed MLflow on Azure Databricks, you get the advantages of both platforms, including:
- Workspaces: Collaboratively track and organize experiments and results within Azure Databricks Workspaces with a hosted MLflow Tracking Server and integrated experiment UI. When you use MLflow in notebooks, Azure Databricks automatically captures notebook revisions so you can reproduce the same code and runs later.
- Security: Take advantage of one common security model for the entire ML lifecycle via ACLs.
- Jobs: Run MLflow projects as Azure Databricks jobs remotely and directly from Azure Databricks notebooks.
Here's a demo of a tracking workflow in an Azure Databricks Workspace:
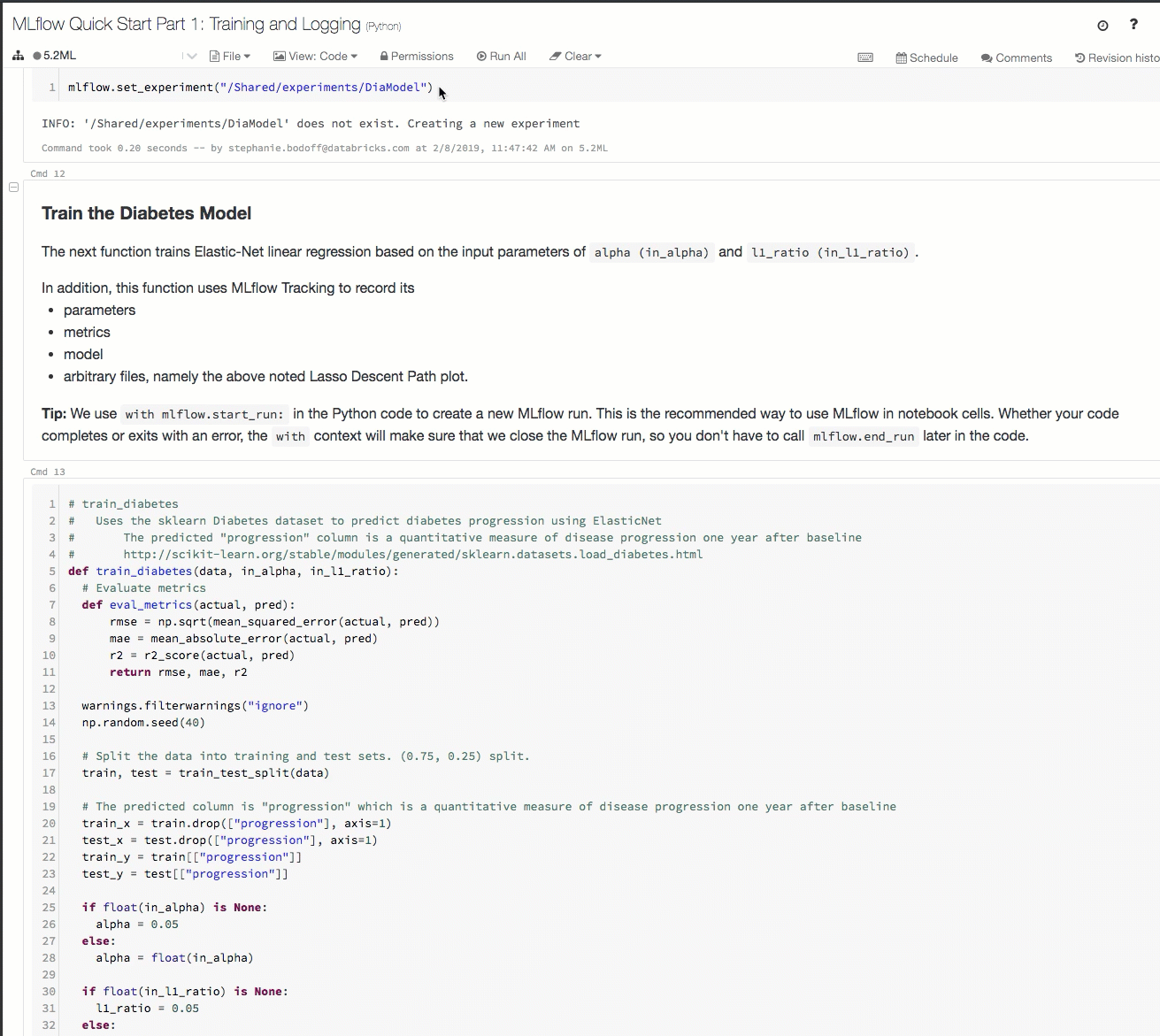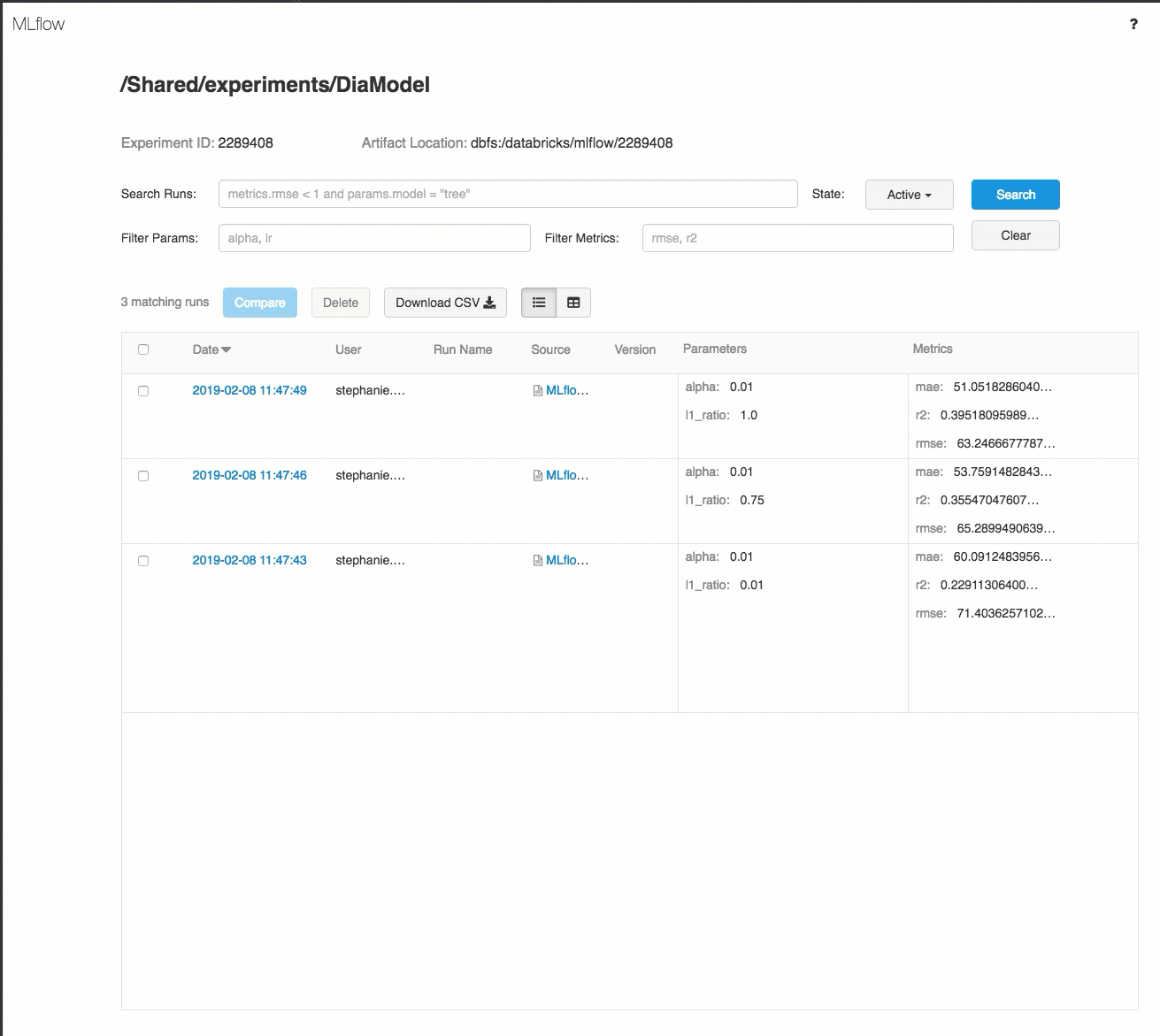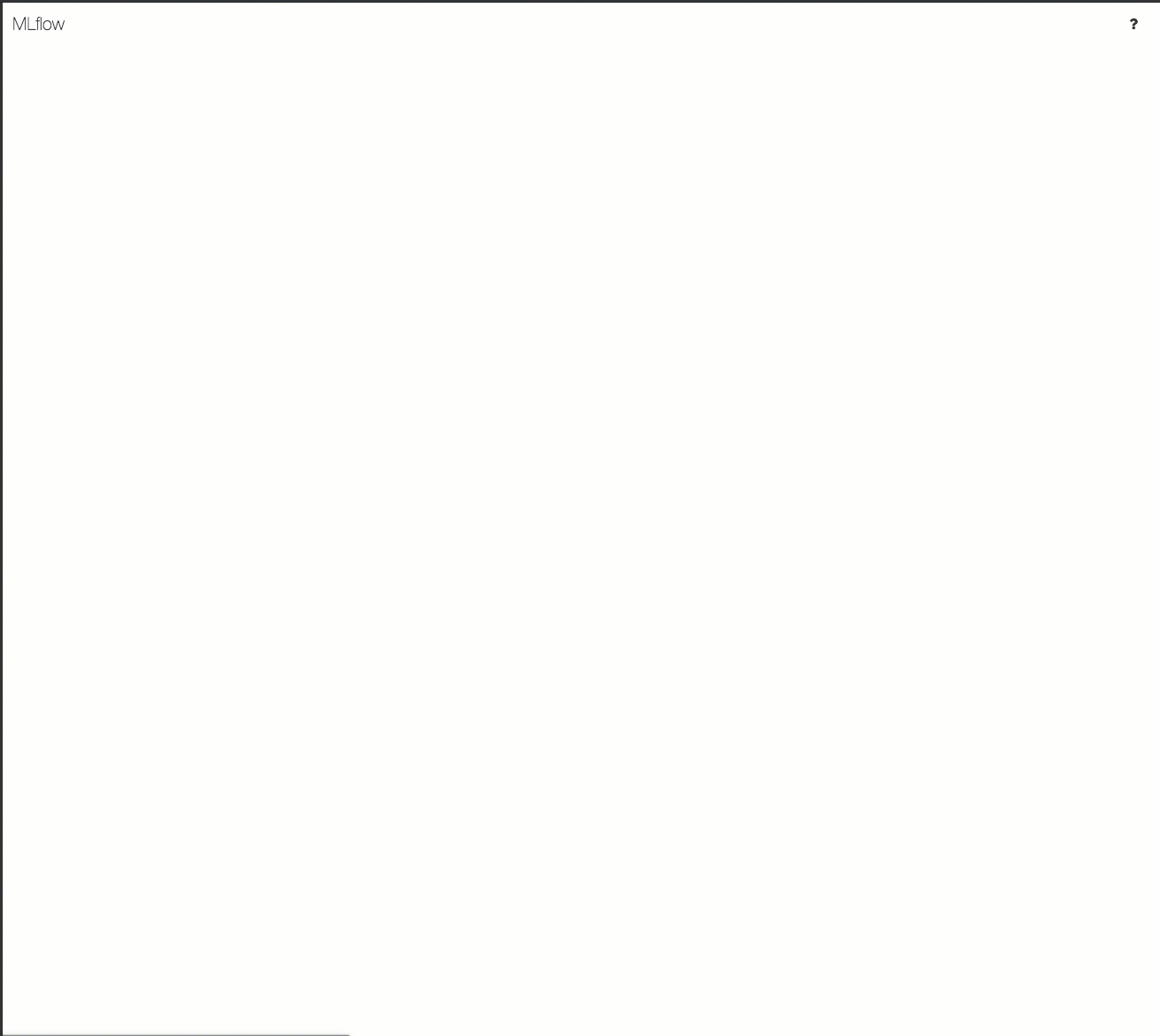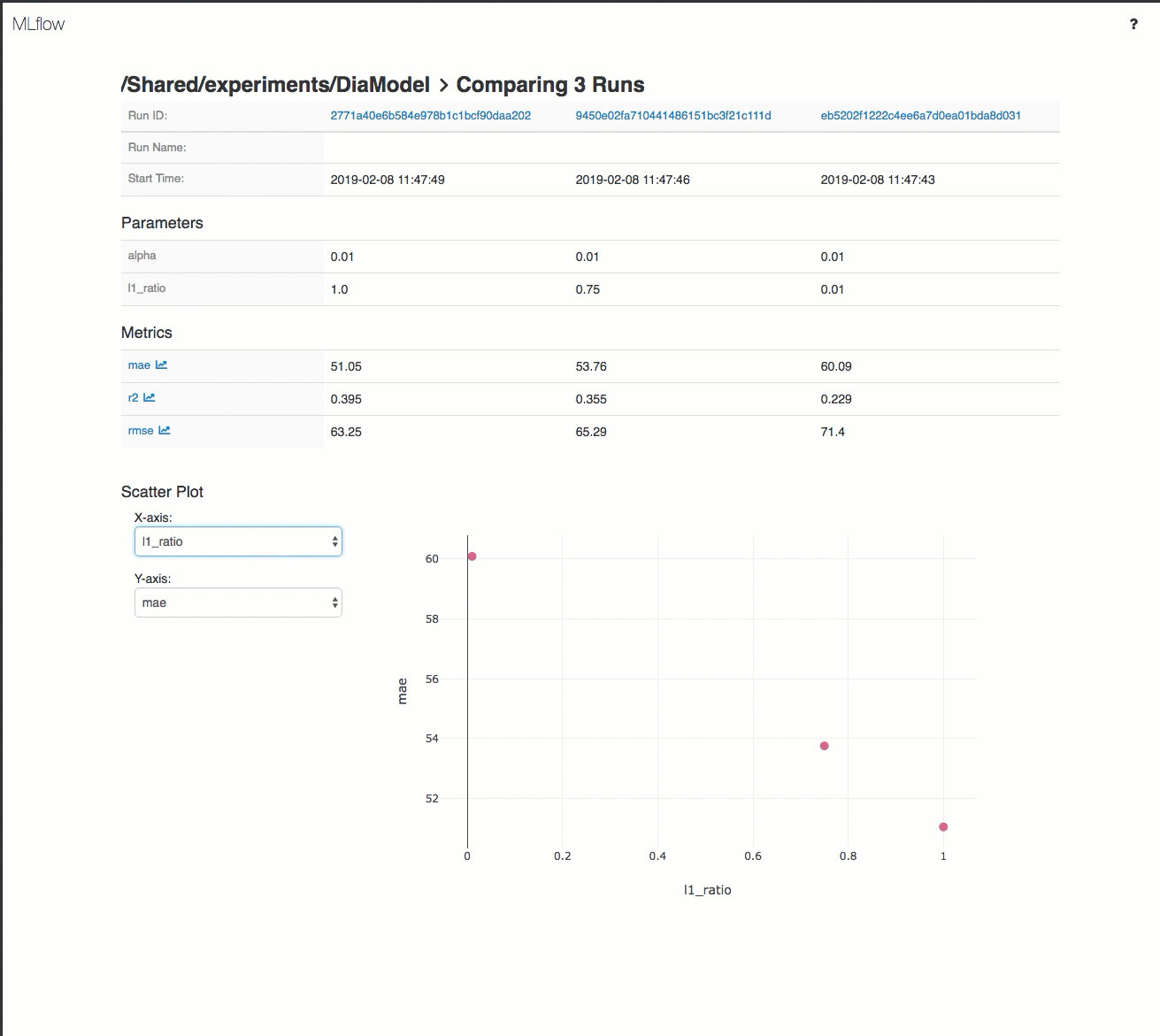
For details, see Track model development using MLflow.
Azure Data Lake Storage connector is generally available
February 15, 2019
Azure Data Lake Storage (ADLS), the next-generation data lake solution for big data analytics, is now GA, as is the ADLS connector for Azure Databricks. We are also pleased to announce that ADLS supports Databricks Delta when you are running clusters on Databricks Runtime 5.2 and above.
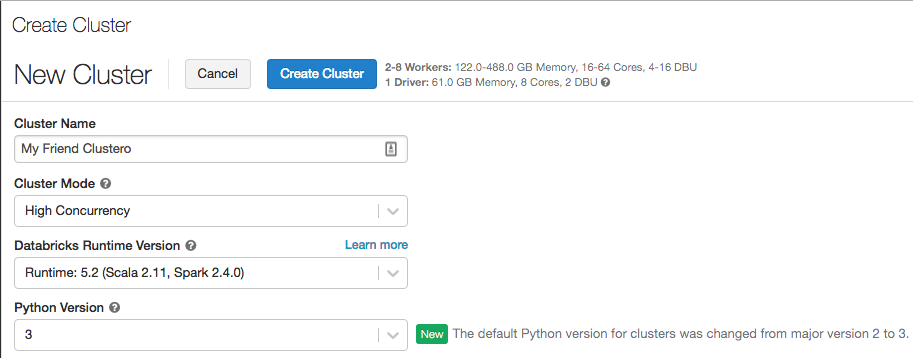
Python 3 now the default when you create clusters
February 12-19, 2019: Version 2.91
The default Python version for clusters created using the UI has switched from Python 2 to Python 3. The default for clusters created using the REST API is still Python 2.
Existing clusters will not change their Python versions. But if you've been in the habit of taking the Python 2 default when you create new clusters, you'll need to start paying attention to your Python version selection.
Delta Lake generally available
February 1, 2019
Now everyone can get the benefits of Databricks Delta's powerful transactional storage layer and super-fast reads: as of February 1, Delta Lake is GA and available on all supported versions of Databricks Runtime. For information about Delta, see the What is Delta Lake in Azure Databricks?.