Manage file assets in Databricks Git folders
Databricks Git folders serve as Git clients for Databricks-managed clones of Git-based source repositories, enabling you to perform a subset of Git operations on their contents from your workspace. As part of this Git integration, files stored in the remote repo are viewed as "assets" based on their type, with some limitations in place specific to their type. Notebook files, in particular, have different properties based on their type. Read this article to understand how to work with assets, particularly IPYNB notebooks, in Git folders.
Supported asset types
Only certain Azure Databricks asset types are supported by Git folders. In this case, "supported" means "can be serialized, version-controlled, and pushed to the backing Git repo."
Currently, the supported asset types are:
| Asset Type | Details |
|---|---|
| File | Files are serialized data, and can include anything from libraries to binaries to code to images. For more information, read What are workspace files? |
| Notebook | Notebooks are specifically the notebook file formats supported by Databricks. Notebooks are considered a separate Azure Databricks asset type from Files because they are not serialized. Git folders determine a Notebook by the file extension (such as .ipynb) or by file extensions combined with a special marker in file content (for example, a # Databricks notebook source comment at the beginning of .py source files). |
| Folder | A folder is an Azure Databricks-specific structure that represents serialized information about a logical grouping of files in Git. As expected, the user experiences this as a "folder" when viewing an Azure Databricks Git folder or accessing it with the Azure Databricks CLI. |
Azure Databricks asset types that are currently not supported in Git folders include the following:
- DBSQL queries
- Alerts
- Dashboards (including legacy dashboards)
When working with your assets in Git, observe the following limitations in file naming:
- A folder cannot contain a notebook with the same name as another notebook, file, or folder in the same Git repository, even if the file extension differs. (For source-format notebooks, the extension is
.pyfor python,.scalafor Scala,.sqlfor SQL, and.rfor R. For IPYNB-format notebooks, the extension is.ipynb.) For example, you can't use a source-format notebook namedtest1.pyand an IPYNB notebook namedtest1in the same Git folder because the source-format Python notebook file (test1.py) will be serialized astest1and a conflict will occur. - The character
/is not supported in file names. For example, you can't have a file namedi/o.pyin your Git folder.
If you attempt to perform Git operations on files that have names that have these patterns, you will get an "Error fetching Git status" message. If you receive this error unexpectedly, review the filenames of the assets in your Git repository. If you find files with names that have these conflicting patterns, rename them and try the operation again.
Note
You can move existing unsupported assets into a Git folder, but cannot commit changes to these assets back to the repo. You cannot create new unsupported assets in a Git folder.
Notebook formats
Databricks considers two kinds of high-level, Databricks-specific notebook formats: "source" and "ipynb". When a user commits a notebook in the "source" format, the Databricks platform commits a flat file with a language suffix, such as .py, .sql, .scala, or .r. A "source"-format notebook contains only source code and does not contain outputs such as table displays and visualizations that are the results of running the notebook.
The "ipynb" format, however, does have outputs associated with it, and those artifacts are automatically pushed to the Git repo backing the Git folder when pushing the .ipynb notebook that generated them. If you want to commit outputs along with the code, use the "ipynb" notebook format and setup configuration to allow a user to commit any generated outputs. As a result, "ipynb" also supports a better viewing experience in Databricks for notebooks pushed to remote Git repos through Git folders.
| Notebook source format | Details |
|---|---|
| source | Can be any code file with a standard file suffix that signals the code language, such as .py, .scala, .r and .sql. "source" notebooks are treated as text files and will not include any associated outputs when committed back to a Git repo. |
| ipynb | "ipynb" files end with .ipynb and can, if configured, push outputs (such as visualizations) from the Databricks Git folder to the backing Git repo. An .ipnynb notebook can contain code in any language supported by Databricks notebooks (despite the py part of .ipynb). |
If you want outputs pushed back to your repo after running a notebook, use a .ipynb (Jupyter) notebook. If you just want to run the notebook and manage it in Git, use a "source" format like .py.
For more details on supported notebook formats, read Export and import Databricks notebooks.
Note
What are "outputs"?
Outputs are the results of running a notebook on the Databricks platform, including table displays and visualizations.
How do I tell what format a notebook is using, other than the file extension?
At the top of a notebook managed by Databricks, there is usually a single-line comment that indicates the format. For example, for a .py "source" notebook, you will see a line that looks like this:
# Databricks notebook source
For .ipynb files, the file suffix is used to indicate that it is the "ipynb" notebook format.
IPYNB notebooks in Databricks Git folders
Support for Jupyter notebooks (.ipynb files) is available in Git folders. You can clone repositories with .ipynb notebooks, work with them in the Databricks product, and then commit and push them as .ipynb notebooks. Metadata such as the notebook dashboard is preserved. Admins can control whether outputs can be committed or not.
Allow committing .ipynb notebook output
By default, the admin setting for Git folders doesn't allow .ipynb notebook output to be committed. Workspace admins can change this setting:
Go to Workspace settings > Development.
Under Repos > Allow repos to export IPYNB output, select Allow: IPYNB outputs can be toggled on.

Important
When outputs are included, the visualization and dashboard configs are preserved with the .ipynb file format.
Control IPYNB notebook output artifact commits
When you commit an .ipynb file, Databricks creates a config file that lets you control how you commit outputs: .databricks/commit_outputs.
If you have a
.ipynbnotebook file but no config file in your repo, open the Git Status modal.In the notification dialog, click Create commit_outputs file.
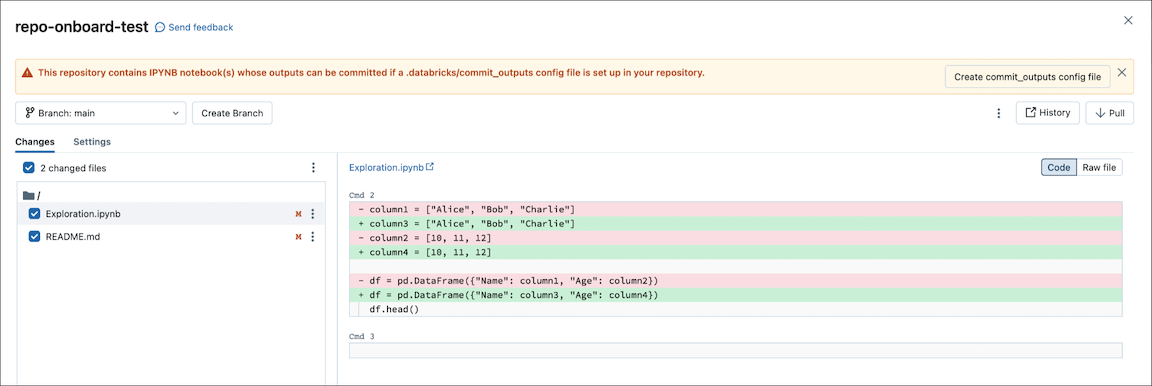
You can also generate config files from the File menu. The File menu has a control that lets you automatically update the config file to specify the inclusion or exclusion of outputs for a specific notebook.
In the File menu, select Commit notebooks outputs.
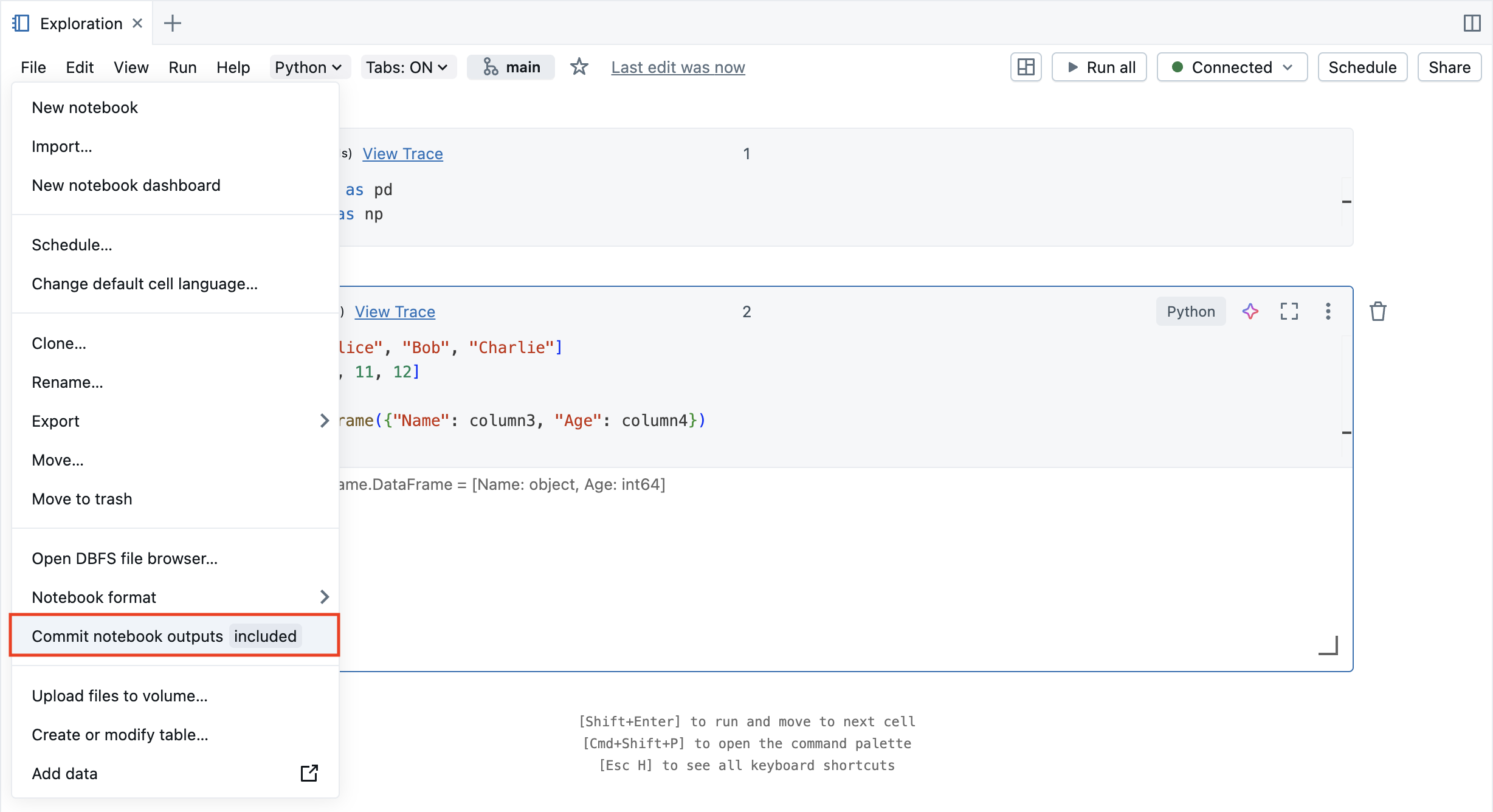
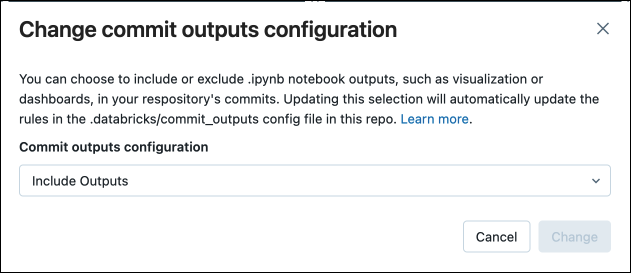
In the dialog box, confirm your choice to commit notebook outputs.
Convert a source notebook to IPYNB
You can convert an existing source notebook in a Git folder to an IPYNB notebook through the Azure Databricks UI.
Open a source notebook in your workspace.
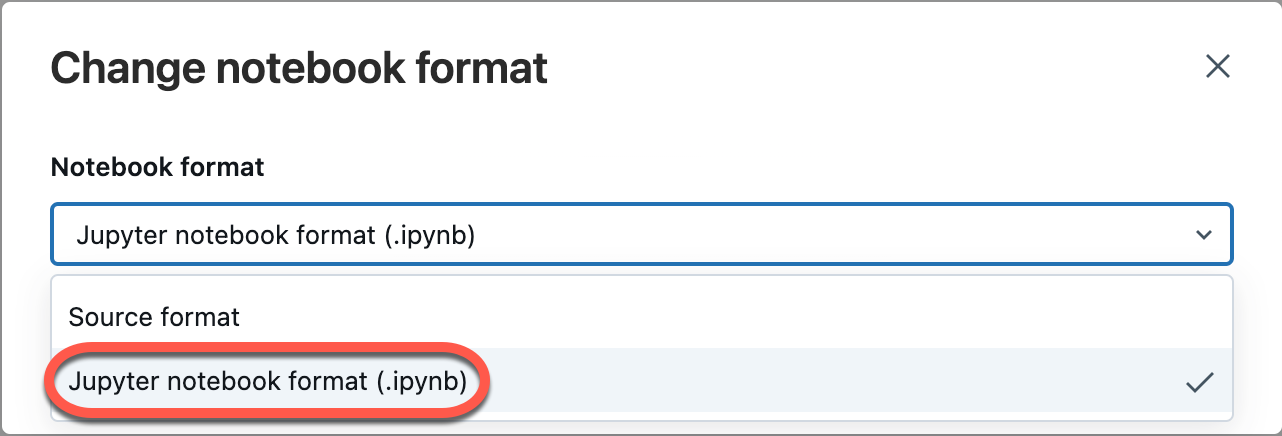
Select File from the workspace menu, and then select Change notebook format [source]. If the notebook is already in IPYNB format, [source] will be [ipynb] in the menu element.
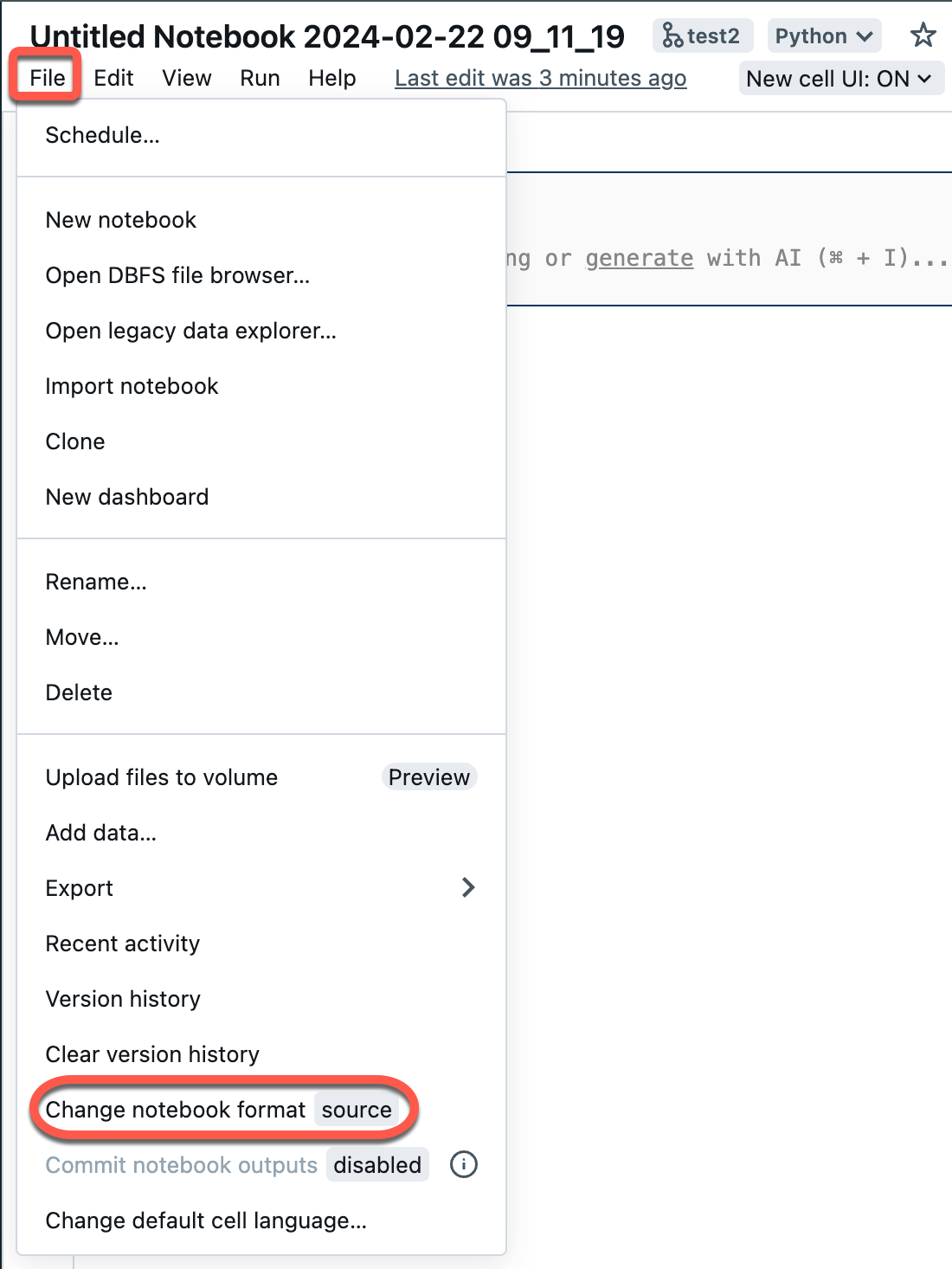
In the modal dialog, select "Jupyter notebook format (.ipynb)" and click Change.
You can also:
- Create new
.ipynbnotebooks. - View diffs as Code diff (code changes in cells) or Raw diff (code changes are presented as JSON syntax, which includes notebook outputs as metadata).
For more information on the kinds of notebooks supported in Azure Databricks, read Export and import Databricks notebooks.