Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Applies to: Azure Logic Apps (Consumption + Standard)
Important
For Power Automate, see Limits and configuration in Power Automate.
This reference guide describes the limits and configuration information for Azure Logic Apps and related resources. Based on your scenario, solution requirements, the capabilities that you want, and the environment where you want to run your workflows, you choose whether to create a Consumption logic app workflow that runs in multitenant Azure Logic Apps or a Standard logic app workflow that runs in single-tenant Azure Logic Apps or an App Service Environment (v3 - Windows plans only).
Note
Many limits are the same across the available environments where Azure Logic Apps runs, but differences are noted where they exist.
The following table briefly summarizes differences between a Consumption logic app and a Standard logic app.
| Hosting option | Benefits | Resource sharing and usage | Pricing and billing model | Limits management |
|---|---|---|---|---|
| Consumption Host environment: Multitenant Azure Logic Apps |
- Easiest to get started - Pay for what you use - Fully managed |
A single logic app resource can have only one workflow. All logic apps across Microsoft Entra tenants share the same processing (compute), storage, network, and so on. Note: Regarding data residency and redundancy: - In workflows or workflow sections that don't interact with agents, the data is replicated in the paired region. For high availability, geo-redundant storage (GRS) is enabled. |
Consumption (pay-per-execution) | Azure Logic Apps manages the default values for these limits, but you can change some of these values, if that option exists for a specific limit. |
| Standard (Workflow Service Plan) Host environment: Single-tenant Azure Logic Apps |
- More built-in connectors hosted on the single-tenant runtime for higher throughput and lower costs at scale - More control and fine-tuning capability around runtime and performance settings - Integrated support for virtual networks and private endpoints. - Create your own built-in connectors. |
A single logic app resource can have multiple stateful and stateless workflows. Workflows in a single logic app and tenant share the same processing (compute), storage, network, and so on. Data stays in the same region where you deploy your logic app. |
Standard, based on a hosting plan with a selected pricing tier. If you run stateful workflows, which use external storage, the Azure Logic Apps runtime makes storage transactions that follow Azure Storage pricing. |
You can change the default values for many limits, based on your scenario's needs. Important: Some limits have hard upper maximums. In Visual Studio Code, the changes you make to the default limit values in your logic app project configuration files won't appear in the designer experience. For more information, see Edit app and environment settings for logic apps in single-tenant Azure Logic Apps. |
| Standard (App Service Environment v3) Host environment: App Service Environment v3 (ASEv3) - Windows plans only |
Same capabilities as single-tenant plus the following benefits: - Fully isolate your logic apps. - Create and run more logic apps than in single-tenant Azure Logic Apps. - Pay only for the ASE App Service plan, no matter the number of logic apps that you create and run. - Can enable autoscaling or manually scale with more virtual machine instances or a different App Service plan. - Inherit the network setup from the selected ASEv3. For example, when you deploy to an internal ASE, workflows can access the resources in a virtual network associated with the ASE and have internal access points. Note: If accessed from outside an internal ASE, run histories for workflows in that ASE can't access action inputs and outputs. |
A single logic app can have multiple stateful and stateless workflows. Workflows in a single logic app and tenant share the same processing (compute), storage, network, and so on. Data stays in the same region where you deploy your logic apps. |
App Service plan | You can change the default values for many limits, based on your scenario's needs. Important: Some limits have hard upper maximums. In Visual Studio Code, the changes you make to the default limit values in your logic app project configuration files won't appear in the designer experience. For more information, see Edit app and environment settings for logic apps in single-tenant Azure Logic Apps. |
| Standard (Hybrid) Host environment: Your own on-premises infrastructure |
- Scenarios where you need to control, and manage your own infrastructure. - Capabilities that let you build and host integration solutions for partially connected environments that require local processing, storage, and network access. - Supports infrastructure that can include on-premises systems, private clouds, and public clouds. - Workflows are powered by the Azure Logic Apps runtime, which is hosted on premises as part of an Azure Container Apps extension. For more information, see the following articles: - Set up your own infrastructure for Standard logic apps using hybrid deployment - Create Standard logic app workflows for hybrid deployment on your own infrastructure |
A single logic app can have multiple stateful and stateless workflows. Workflows in a single logic app and tenant share the same processing (compute), storage, network, and so on. Data stays in the same region where you deploy your logic apps. |
Hybrid pricing | You can change the default values for many limits, based on your scenario's needs. Important: Some limits have hard upper maximums. In Visual Studio Code, the changes you make to the default limit values in your logic app project configuration files won't appear in the designer experience. For more information, see Edit app and environment settings for logic apps in single-tenant Azure Logic Apps. |
Workflow limits
The following table lists the values that apply to a single workflow definition unless noted otherwise:
| Name | Limit | Notes |
|---|---|---|
| Workflows per region per Azure subscription | - Consumption: 1,000 workflows where each logic app always has only 1 workflow - Standard: Unlimited, based on the selected hosting plan, app activity, size of machine instances, and resource usage, where each logic app can have multiple workflows |
For optimal performance guidelines around Standard logic app workflows, see Best practices and recommendations. |
| Workflow - Maximum name length | - Consumption: 80 characters - Standard: 32 characters |
|
| Triggers per workflow | - Consumption (designer): 1 trigger - Consumption (JSON): 10 triggers - Standard: 1 trigger |
- Consumption: Multiple triggers are possible only when you work on the JSON workflow definition, whether in code view or an Azure Resource Manager (ARM) template, not the designer. - Standard: Only one trigger is possible, whether in the designer, code view, or an Azure Resource Manager (ARM) template. |
| Actions per workflow | 500 actions | To extend this limit, you can use nested workflows as necessary. |
| Actions nesting depth | 8 actions | To extend this limit, you can use nested workflows as necessary. |
| Single trigger or action - Maximum name length | 80 characters | |
| Single trigger or action - Maximum input or output size | 104,857,600 bytes (105 MB) |
To change the default value in the single-tenant service, review Edit host and app settings for logic apps in single-tenant Azure Logic Apps. |
| Single action - Maximum combined inputs and outputs size | 209,715,200 bytes (210 MB) |
To change the default value in the single-tenant service, review Edit host and app settings for logic apps in single-tenant Azure Logic Apps. |
| Expression character limit | 8,192 characters | |
description - Maximum length |
256 characters | |
parameters - Maximum number of parameters per workflow |
- Consumption: 50 parameters - Standard: 500 parameters |
|
outputs - Maximum number of outputs |
10 outputs | |
trackedProperties - Maximum number of characters |
8,000 characters | Each action supports a JSON object named trackedProperties that you can use to specify certain action inputs or outputs to emit from your workflow and include in diagnostic telemetry. For more information, see Monitor and collect diagnostic data for workflows. |
Run duration and history retention limits
The following table lists the values for a single workflow run:
| Name | Multitenant | Single-tenant | Notes |
|---|---|---|---|
| Run history retention in storage | 90 days | 90 days (Default) |
The amount of time to keep a workflow's run history in storage after a run starts. Note: If the workflow's run duration exceeds the retention limit, this run is removed from the run history in storage. If a run isn't immediately removed after reaching the retention limit, the run is removed within 7 days. Whether a run completes or times out, retention is always calculated by using the run's start time and the retention limit at the time when the run started, not the current limit. You can find the retention limit in the workflow setting, Run history retention in days. For more information, review Change duration and run history retention in storage. |
| Run duration | 90 days | - Stateful workflow: 90 days (Default) - Stateless workflow: 5 min (Default) |
The amount of time that a workflow can continue running before forcing a time-out. The run duration is calculated by using a run's start time and the limit that's specified in the workflow setting, Run history retention in days at that start time. Important: Make sure the run duration value is always less than or equal to the run history retention in storage value. Otherwise, run histories might be deleted before the associated jobs are complete. For more information, review Change run duration and history retention in storage. |
| Recurrence interval | - Min: 1 sec - Max: 500 days |
- Min: 1 sec - Max: 500 days |
Change run duration and history retention in storage
If a run's duration exceeds the current run history retention limit, the run is removed from the run history in storage. To avoid losing run history, make sure that the retention limit is always more than the run's longest possible duration.
For Consumption logic app workflows, the same setting controls the maximum number of days that a workflow can run and for keeping run history in storage.
In multitenant Azure Logic Apps, the 90-day default limit is the same as the maximum limit. You can only decrease this value.
Run history retention is always calculated by using the run's start time and the retention limit at the time when the run started, not the current retention limit.
Portal
In the Azure portal search box, open your logic app workflow in the designer.
On the logic app menu, select Workflow settings.
Under Runtime options, from the Run history retention in days list, select Custom.
Drag the slider to change the number of days that you want.
When you're done, on the Workflow settings toolbar, select Save.
ARM template
If you use an Azure Resource Manager template, this setting appears as a property in your workflow's resource definition.
{
"name": "{logic-app-name}",
"type": "Microsoft.Logic/workflows",
"location": "{Azure-region}",
"apiVersion": "2019-05-01",
"properties": {
"definition": {},
"parameters": {},
"runtimeConfiguration": {
"lifetime": {
"unit": "day",
"count": {number-of-days}
}
}
}
}
Looping, concurrency, and debatching limits
The following table lists the values for a single workflow run:
Loop actions
For each loop
The following table lists the values for a For each loop:
| Name | Multitenant | Single-tenant | Notes |
|---|---|---|---|
| Array items | 100,000 items | - Stateful workflow: 100,000 items (Default) - Stateless workflow: 100 items (Default) |
The number of array items that a For each loop can process. To filter larger arrays, you can use the query action. To change the default limit in the single-tenant service, review Edit host and app settings for logic apps in single-tenant Azure Logic Apps. |
| Concurrent iterations | Concurrency off: 20 Concurrency on: - Default: 20 - Min: 1 - Max: 50 |
Concurrency off: 20 (Default) Concurrency on: - Default: 20 - Min: 1 - Max: 50 |
The number of For each loop iterations that can run at the same time, or in parallel. To change this value in multitenant Azure Logic Apps, see Change For each concurrency limit or Run For each loops sequentially. To change the default limit in the single-tenant service, review Edit host and app settings for logic apps in single-tenant Azure Logic Apps. |
Until loop
The following table lists the values for an Until loop:
| Name | Multitenant | Single-tenant | Notes |
|---|---|---|---|
| Iterations | - Default: 60 - Min: 1 - Max: 5,000 |
Stateful workflow: - Default: 60 - Min: 1 - Max: 5,000 Stateless workflow: - Default: 60 - Min: 1 - Max: 100 |
The number of cycles that an Until loop can have during a workflow run. To change this value in multitenant Azure Logic Apps, in the Until loop shape, select Change limits, and specify the value for the Count property. To change the default value in the single-tenant service, review Edit host and app settings for logic apps in single-tenant Azure Logic Apps. |
| Time-out | Default: PT1H (1 hour) | Stateful workflow: PT1H (1 hour) Stateless workflow: PT5M (5 min) |
The amount of time that the Until loop can run before exiting and is specified in ISO 8601 format. The time-out value is evaluated for each loop cycle. If any action in the loop takes longer than the time-out limit, the current cycle doesn't stop. However, the next cycle doesn't start because the limit condition isn't met. To change this value in multitenant Azure Logic Apps, in the Until loop shape, select Change limits, and specify the value for the Timeout property. To change the default value in the single-tenant service, review Edit host and app settings for logic apps in single-tenant Azure Logic Apps. |
Concurrency and debatching
| Name | Multitenant | Single-tenant | Notes |
|---|---|---|---|
| Trigger - concurrent runs | Concurrency off: Unlimited Concurrency on (irreversible): - Default: 25 - Min: 1 - Max: 100 |
Concurrency off: Unlimited Concurrency on (irreversible): - Default: 100 - Min: 1 - Max: 100 |
The number of concurrent runs that a trigger can start at the same time, or in parallel. Note: When concurrency is turned on, the debatching or Split on limit is reduced to 100 items for debatching arrays. To change this value in multitenant Azure Logic Apps, see Change trigger concurrency limit or Trigger instances sequentially. To change the default value in the single-tenant service, review Edit host and app settings for logic apps in single-tenant Azure Logic Apps. |
| Maximum waiting runs | Concurrency on: - Min: 10 runs plus the number of concurrent runs (Default) - Max: 100 runs |
Concurrency on: - Min: 10 runs plus the number of concurrent runs (Default) - Max: 200 runs |
The number of workflow instances that can wait to run when your current workflow instance is already running the maximum concurrent instances. This setting takes effect only if concurrency is turned on. To change this value in multitenant Azure Logic Apps, see Change waiting runs limit. To change the default value in the single-tenant service, review Edit host and app settings for logic apps in single-tenant Azure Logic Apps. |
| Debatch or Split on items | Concurrency off: 100,000 items Concurrency on: 100 items |
Concurrency off: 100,000 items Concurrency on: 100 items |
For triggers that return arrays, you can specify an expression that uses the splitOn property, which splits or debatches array items into multiple workflow instances for processing, rather than use a For each loop. This expression references the array to use for creating and running a workflow instance for each array item. Note: When concurrency is turned on, the debatching or Split on limit is reduced to 100 items. |
Throughput limits
The following table lists the values for a single workflow definition:
| Name | Multitenant | Single-tenant | Notes |
|---|---|---|---|
| Action - Executions per 5-minute rolling interval | Default: 100,000 executions - High throughput mode: 300,000 executions |
None | In multitenant Azure Logic Apps, you can raise the default value to the maximum value for your workflow. For more information, see Run in high throughput mode, which is in preview. Or, you can distribute the workload across more than one workflow as necessary. |
| Action - Concurrent outbound calls | ~2,500 calls | None | You can reduce the number of concurrent requests or reduce the duration as necessary. |
| Managed connector throttling | Throttling limit varies based on connector | Throttling limit varies based on connector | For multitenant, review each managed connector's technical reference page. For more information about handling connector throttling, review Handle throttling problems ("429 - Too many requests" errors). |
| Runtime endpoint - Concurrent inbound calls | ~1,000 calls | None | You can reduce the number of concurrent requests or reduce the duration as necessary. |
| Runtime endpoint- Concurrent inbound calls for API Management REST API | 56 calls per 5 minutes | Applies only to API Management REST API calls to the Request trigger in a Standard logic app workflow. Use the callback URL to send the request to the Request trigger in a Standard logic app workflow, rather than use API Management calls, which have a hard throttling limit of 56 calls per 5-minute interval. |
|
| Runtime endpoint - Read calls per 5 min | 60,000 read calls | None | This limit applies to calls that get the raw inputs and outputs from a workflow's run history. You can distribute the workload across more than one workflow as necessary. |
| Runtime endpoint - Invoke calls per 5 min | 45,000 invoke calls | None | You can distribute workload across more than one workflow as necessary. |
| Content throughput per 5 min | 6 GB | None | For example, suppose the backend has 100 workers. Each worker has a limit of 60 MB, which is the result from dividing 6 GB by 100 workers. You can distribute workload across more than one workflow as necessary. |
Scale for high throughput
Multitenant Azure Logic Apps has a default limit on the number of actions that run every 5 minutes. To raise the default value to the maximum value, you can enable high throughput mode, which is in preview. Or, distribute the workload across multiple logic apps and workflows, rather than rely on a single logic app and workflow.
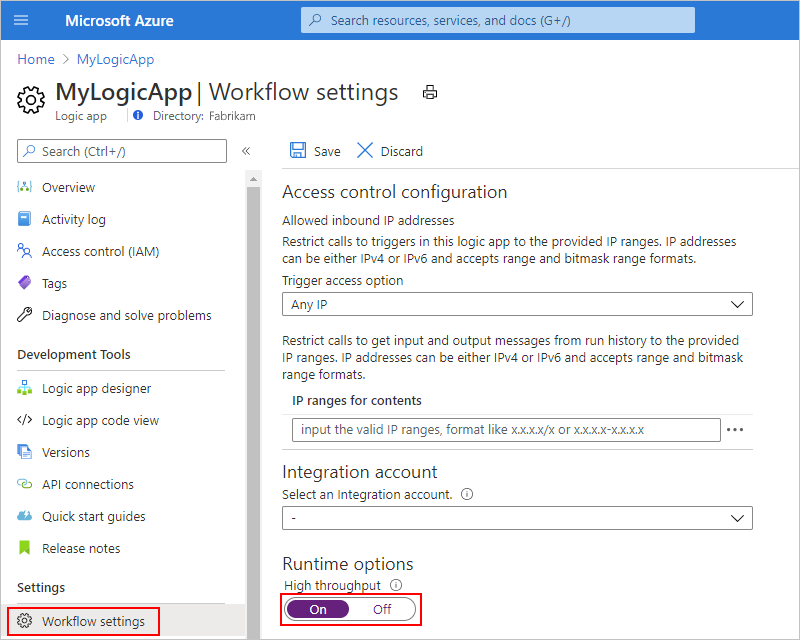
Enable high throughput in the portal
In the Azure portal, on your logic app's menu, under Settings, select Workflow settings.
Under Runtime options > High throughput, change the setting to On.
Enable high throughput in a Resource Manager template
To enable this setting in an ARM template for deploying your logic app, in the properties object for your logic app's resource definition, add the runtimeConfiguration object with the operationOptions property set to OptimizedForHighThroughput:
{
<template-properties>
"resources": [
// Start logic app resource definition
{
"properties": {
<logic-app-resource-definition-properties>,
<logic-app-workflow-definition>,
<more-logic-app-resource-definition-properties>,
"runtimeConfiguration": {
"operationOptions": "OptimizedForHighThroughput"
}
},
"name": "[parameters('LogicAppName')]",
"type": "Microsoft.Logic/workflows",
"location": "[parameters('LogicAppLocation')]",
"tags": {},
"apiVersion": "2016-06-01",
"dependsOn": [
]
}
// End logic app resource definition
],
"outputs": {}
}
For more information about your logic app resource definition, review Overview: Automate deployment for Azure Logic Apps by using Azure Resource Manager templates.
Data gateway limits
Azure Logic Apps supports write operations, including inserts and updates, through the on-premises data gateway. However, these operations have limits on their payload size.
Retry policy limits
The following table lists the retry policy limits for a trigger or action, based on whether you have a Consumption or Standard logic app workflow.
| Name | Consumption limit | Standard limit | Notes |
|---|---|---|---|
| Retry attempts | - Default: 4 attempts - Max: 90 attempts |
- Default: 4 attempts | To change the default limit in Consumption logic app workflows, use the retry policy parameter. To change the default limit in Standard logic app workflows, review Edit host and app settings for logic apps in single-tenant Azure Logic Apps. |
| Retry interval | None | Default: 7 sec | To change the default limit in Consumption logic app workflows, use the retry policy parameter. To change the default limit in Standard logic app workflows, review Edit host and app settings for logic apps in single-tenant Azure Logic Apps. |
Variables action limits
The following table lists the values for a single workflow definition:
| Name | Multitenant | Single-tenant | Notes |
|---|---|---|---|
| Variables per workflow | 250 variables | 250 variables (Default) |
|
| Variable - Maximum content size | 104,857,600 characters | Stateful workflow: 104,857,600 characters (Default) Stateless workflow: 1,024 characters (Default) |
To change the default value in the single-tenant service, review Edit host and app settings for logic apps in single-tenant Azure Logic Apps. |
| Variable (Array type) - Maximum number of array items | 100,000 items | 100,000 items (Default) |
To change the default value in the single-tenant service, review Edit host and app settings for logic apps in single-tenant Azure Logic Apps. |
HTTP request limits
The following tables list the values for a single inbound or outbound call:
Time-out duration
By default, the HTTP action and API connection actions follow the standard asynchronous operation pattern, while the Response action follows the synchronous operation pattern. Some managed connector operations make asynchronous calls or listen for webhook requests, so the timeout for these operations might be longer than the following limits. For more information, see each connector's technical reference page and the Workflow triggers and actions page.
For Standard logic app resources in single-tenant Azure Logic Apps, stateless workflows can only run synchronously. Stateless workflows only save each action's inputs, outputs, and states in memory, not external storage. As a result, stateless workflows perform faster with quicker response times, provide higher throughput, reduce running costs from not using external storage, and shorter runs usually finish in 5 minutes or less. However, if outages happen, interrupted runs aren't automatically restored. The caller must manually resubmit interrupted runs. For the best performance, make sure that a stateless workflow handles data or content that doesn't exceed 64 KB in total file size. Larger sizes, such as multiple large attachments, might significantly slow workflow performance or even cause the workflow to crash from out-of-memory exceptions. If you require a workflow to handle larger file sizes, create a stateful workflow instead.
| Name | Multitenant | Single-tenant | Notes |
|---|---|---|---|
| Outbound request | 120 sec (2 min) |
235 sec (3.9 min) (Default) |
Examples of outbound requests include calls made by the HTTP trigger or action. Tip: For longer running operations, use an asynchronous polling pattern or an "Until" loop. To work around time-out limits when you call another workflow that has a callable endpoint, you can use the built-in Azure Logic Apps action instead, which you can find in the designer's operation picker under Built-in. To change the default limit in the single-tenant service, review Edit host and app settings for logic apps in single-tenant Azure Logic Apps. |
| Inbound request | 120 sec (2 min) |
235 sec (3.9 min) (Default) |
Examples of inbound requests include calls received by the Request trigger, HTTP Webhook trigger, and HTTP Webhook action. Note: For the original caller to get the response, all steps in the response must finish within the limit unless you call another nested workflow. For more information, see Call, trigger, or nest logic apps. To change the default limit in the single-tenant service, review Edit host and app settings for logic apps in single-tenant Azure Logic Apps. |
Request trigger and webhook trigger size limits
| Name | Multitenant | Single-tenant | Notes |
|---|---|---|---|
| Request trigger (inbound) and webhook-based triggers - Content size limit per 5-minute rolling interval per workflow | 3,145,728 KB | None | This limit applies only to the content size for inbound requests received by the Request trigger or any webhook trigger. For example, suppose the backend has 100 workers. Each worker has a limit of 31,457,280 bytes, which is the result from dividing 3,145,728,000 bytes by 100 workers. To avoid experiencing premature throttling for the Request trigger, use a new HTTP client for each request, which helps evenly distribute the calls across all nodes. For a webhook trigger, you might have to use multiple workflows, which split the load and avoids throttling. |
Messages
| Name | Chunking enabled | Multitenant | Single-tenant | Notes |
|---|---|---|---|---|
| Content download - Maximum number of requests | Yes | 1,000 requests | 1,000 requests (Default) |
|
| Message size | No | 100 MB | 100 MB | To work around this limit, see Handle large messages with chunking. However, some connectors and APIs don't support chunking or even the default limit. - Connectors such as AS2, X12, and EDIFACT have their own B2B message limits. To change the default value in the single-tenant service, review Edit host and app settings for logic apps in single-tenant Azure Logic Apps. |
| Message size per action | Yes | 1 GB | 1,073,741,824 bytes (1 GB) (Default) |
This limit applies to actions that either natively support chunking or let you enable chunking in their runtime configuration. For more information about chunking, see Handle large messages with chunking. To change the default value in the single-tenant service, review Edit host and app settings for logic apps in single-tenant Azure Logic Apps. |
| Content chunk size per action | Yes | Varies per connector | 52,428,800 bytes (52 MB) (Default) |
This limit applies to actions that either natively support chunking or let you enable chunking in their runtime configuration. To change the default value in the single-tenant service, review Edit host and app settings for logic apps in single-tenant Azure Logic Apps. |
Character limits
| Name | Limit | Notes |
|---|---|---|
| Expression evaluation limit | 131,072 characters | The @concat(), @base64(), @string() expressions can't be longer than this limit. |
| Request URL character limit | 16,384 characters |
Authentication limits
The following table lists the values for a workflow that starts with a Request trigger and enables Microsoft Entra ID Open Authentication (Microsoft Entra ID OAuth) for authorizing inbound calls to the Request trigger:
| Name | Limit | Notes |
|---|---|---|
| Microsoft Entra authorization policies | 5 policies | |
| Claims per authorization policy | 10 claims | |
| Claim value - Maximum number of characters | 150 characters |
Switch action limits
The following table lists the values for a single workflow definition:
| Name | Limit | Notes |
|---|---|---|
| Maximum number of cases per action | 25 |
Inline Code action limits
The following table lists the values for a single workflow definition:
| Name | Multitenant | Single-tenant | Notes |
|---|---|---|---|
| Maximum number of code characters | 1,024 characters | 100,000 characters | To use the higher limit, create a Standard logic app resource, which runs in single-tenant Azure Logic Apps, either by using the Azure portal or by using Visual Studio Code and the Azure Logic Apps (Standard) extension. |
| Maximum duration for running code | 5 sec | 15 sec | To use the higher limit, create a Standard logic app resource, which runs in single-tenant Azure Logic Apps, either by using the Azure portal or by using Visual Studio Code and the Azure Logic Apps (Standard) extension. |
Custom connector limits
In multitenant Azure Logic Apps only, you can create and use custom managed connectors, which are wrappers around an existing REST API or SOAP API. In single-tenant Azure Logic Apps, you can create and use only custom built-in connectors.
The following table lists the values for custom connectors:
| Name | Multitenant | Single-tenant | Notes |
|---|---|---|---|
| Custom connectors | 1,000 per Azure subscription | Unlimited | |
| APIs per service | SOAP-based: 50 | Not applicable | |
| Parameters per API | SOAP-based: 50 | Not applicable | |
| Requests per minute for a custom connector | 500 requests per minute per connection | Based on your implementation | |
| Connection time-out | 2 min | Idle connection: 4 min Active connection: 10 min |
For more information, review the following documentation:
- Custom managed connectors overview
- Enable built-in connector authoring - Visual Studio Code with Azure Logic Apps (Standard) extension
Managed identity limits
| Name | Limit |
|---|---|
| Managed identities per logic app resource | - Consumption: Either the system-assigned identity or only one user-assigned identity - Standard: The system-assigned identity and any number of user-assigned identities Note: By default, a Logic App (Standard) resource has the system-assigned managed identity automatically enabled to authenticate connections at runtime. This identity differs from the authentication credentials or connection string that you use when you create a connection. If you disable this identity, connections won't work at runtime. To view this setting, on your logic app's menu, under Settings, select Identity. |
| Number of logic apps that have a managed identity in an Azure subscription per region | - Consumption: 5,000 logic apps - Standard: Per Azure App Service limits, if any |
Integration account limits
Each Azure subscription has these integration account limits:
- 1,000 total integration accounts across both Developer and Premium SKUs.
Artifact limits per integration account
The following tables list the values for the number of artifacts limited to each integration account tier. For pricing rates, see Logic Apps pricing. To learn how pricing and billing work for integration accounts, see the Logic Apps pricing model.
Note
Use the Free tier only for exploratory scenarios, not production scenarios. This tier restricts throughput and usage, and has no service-level agreement (SLA).
| Artifact | Free | Basic | Standard |
|---|---|---|---|
| EDI trading agreements | 10 | 1 | 1,000 |
| EDI trading partners | 25 | 2 | 1,000 |
| Maps | 25 | 500 | 1,000 |
| Schemas | 25 | 500 | 1,000 |
| Assemblies | 10 | 25 | 1,000 |
| Certificates | 25 | 2 | 1,000 |
| Batch configurations | 5 | 1 | 50 |
| RosettaNet partner interface process (PIP) | 10 | 1 | 500 |
Artifact capacity limits
| Artifact | Limit | Notes |
|---|---|---|
| Assembly | 8 MB | To upload files larger than 2 MB, use an Azure storage account and blob container. |
| Map (XSLT file) | 8 MB | To upload files larger than 2 MB, use the Azure Logic Apps REST API - Maps. Note: The amount of data or records that a map can successfully process is based on the message size and action timeout limits in Azure Logic Apps. For example, if you use an HTTP action, based on HTTP message size and timeout limits, a map can process data up to the HTTP message size limit if the operation completes within the HTTP timeout limit. |
| Schema | 8 MB | To upload files larger than 2 MB, use an Azure storage account and blob container. |
Throughput limits
| Runtime endpoint | Basic | Standard | Notes |
|---|---|---|---|
| Read calls per 5 min | 30,000 | 60,000 | This limit applies to calls that get the raw inputs and outputs from a logic app's run history. You can distribute the workload across more than one account as necessary. |
| Invoke calls per 5 min | 30,000 | 45,000 | You can distribute the workload across more than one account as necessary. |
| Tracking calls per 5 min | 30,000 | 45,000 | You can distribute the workload across more than one account as necessary. |
| Blocking concurrent calls | ~1,000 | ~1,000 | Same for all SKUs. You can reduce the number of concurrent requests or reduce the duration as necessary. |
B2B protocol (AS2, X12, EDIFACT) message size
The following table lists the message size limits that apply to B2B protocols:
| Name | Multitenant | Single-tenant | Notes |
|---|---|---|---|
| AS2 | v2 - 100 MB v1 - 25 MB |
Unavailable | Applies to decode and encode |
| X12 | 50 MB | Unavailable | Applies to decode and encode |
| EDIFACT | 50 MB | Unavailable | Applies to decode and encode |
Firewall configuration: IP addresses and service tags
If your environment has strict network requirements and uses a firewall that limits traffic to specific IP addresses, your environment or firewall needs to permit inbound traffic sent to multitenant Azure Logic Apps from outside and outbound traffic sent from Azure Logic Apps to the outside. To set up this access, you can create Azure Firewall rules that allow access for the inbound and outbound IP addresses required by Azure Logic Apps in the Azure region for your logic app resource. All logic apps in the same region use the same IP addresses.
Note
If you use Power Automate, some actions such as HTTP and HTTP + OpenAPI communicate directly through the Azure Logic Apps platform using some of the IP addresses listed here. For more information about the IP addresses used by Power Automate, see Limits and configuration for Power Automate.
For example, suppose your logic apps are deployed in the China East 2 region. To support calls that your logic apps send or receive through built-in triggers and actions, such as the HTTP trigger or action, your firewall needs to allow access for all the Azure Logic Apps service inbound IP addresses and outbound IP addresses that exist in the China East 2 region.
- Adjust communication settings for the on-premises data gateway
- Configure proxy settings for the on-premises data gateway
Firewall IP configuration considerations
Before you set up your firewall with IP addresses, review these considerations:
For Azure China 21Vianet, fixed or reserved IP addresses are unavailable for custom connectors and for managed connectors, such as Azure Storage, SQL Server, Office 365 Outlook, and so on.
Note
Currently, you can't set up firewall security rules for managed connectors and custom connectors in Azure China 21Vianet.
To simplify any security rules that you create, use service tags, rather than specific IP addresses. These tags represent a group of IP address prefixes from a specific Azure service and work across the regions where the Azure Logic Apps service is available:
Service tag Description LogicAppsManagement Inbound IP address prefixes for the Azure Logic Apps service. LogicApps Outbound IP address prefixes for the multitenant Azure Logic Apps service. If your logic apps have problems accessing Azure storage accounts that use firewalls and firewall rules, you have various other options to enable access.
For example, logic apps can't directly access storage accounts that use firewall rules and exist in the same region. To access your Table Storage or Queue Storage, you can use the HTTP trigger and actions instead. For other options, see Access storage accounts behind firewalls.
Inbound IP addresses
This section lists the inbound IP addresses for the Azure Logic Apps service in Azure China 21Vianet.
Note
Some managed connector operations make inbound webhook callbacks to Azure Logic Apps. If you use access control on the logic app resource, make sure that the calls from the IP addresses for these services or systems have permissions to access your logic app.
The following connector operations make inbound webhook callbacks to Azure Logic Apps:
Adobe Creative Cloud, Adobe Sign, Adobe Sign Demo, Adobe Sign Preview, Adobe Sign Stage, Azure Event Grid, Calendly, DocuSign, DocuSign Demo, LiveChat, Microsoft Dataverse (Common Data Service), Microsoft Forms, Microsoft Dynamics 365 Business Central, Microsoft Dynamics 365 for Fin & Ops, Microsoft Office 365* Outlook, Microsoft Outlook.com, Microsoft Sentinel, Parserr, SAP*, Shifts for Microsoft Teams, Teamwork Projects, Typeform, and so on:
Office 365: The return caller is actually the Office 365 connector. You can specify the managed connector outbound IP address for each region, or use the AzureConnectors service tag for these managed connectors.
SAP: The return caller depends on whether the deployment environment is multitenant Azure. In the multitenant, the on-premises data gateway makes the callback to the Azure Logic Apps service.
Multitenant - Inbound IP addresses
| Azure China Cloud region | IP |
|---|---|
| China East | 139.219.235.237, 42.159.193.38, 42.159.192.121, 163.228.119.60, 163.228.118.191 |
| China East 2 | 139.217.224.152, 40.73.245.4, 139.217.224.69, 139.217.226.111, 52.130.67.208, 40.73.71.31, 52.131.241.43, 52.131.243.142, 52.130.89.243, 163.228.155.189, 40.72.118.169, 40.72.114.104, 52.130.92.162, 40.72.116.147, 52.130.211.201, 52.130.215.38 |
| China East 3 | 163.228.66.178, 163.228.67.83, 52.131.158.64, 52.131.158.65, 52.131.158.66, 52.131.158.67, 52.131.158.68, 52.131.158.69, 52.131.158.70, 52.131.158.71 |
| China North | 139.219.109.245, 139.219.111.85, 40.125.171.245, 143.64.185.170, 143.64.188.211 |
| China North 2 | 40.73.33.166, 40.73.33.122, 40.73.37.11, 40.73.32.124, 52.130.155.36, 52.130.155.90, 40.73.36.163, 40.73.39.195, 159.27.155.6, 159.27.152.85, 139.217.98.133, 139.217.98.139, 139.217.98.249, 40.73.33.118, 159.27.153.167, 159.27.154.178 |
| China North 3 | 159.27.4.236, 159.27.25.161, 143.64.123.42, 143.64.191.52, 143.64.191.41, 143.64.122.199, 143.64.167.129, 143.64.187.163, 143.64.136.86, 143.64.123.32 |
Outbound IP addresses
This section lists the outbound IP addresses for the Azure Logic Apps service in Azure China 21Vianet.
Tip
To help reduce complexity when you create security rules, you can optionally use the service tag, LogicApps, rather than specify outbound Logic Apps IP address prefixes for each region. These tags work across the regions where the Azure Logic Apps service is available.
Note
For the latest service tag information, you can download and check Azure IP Ranges and Service Tags China Cloud.
Multi-tenant - Outbound IP addresses
| Azure China Cloud region | Logic Apps IP |
|---|---|
| China East | 139.219.185.172, 42.159.197.40, 42.159.196.202, 163.228.116.28, 163.228.115.209, 163.228.115.146, 163.228.115.129 |
| China East 2 | 40.73.245.106, 40.73.245.189, 40.73.245.160, 40.73.245.228, 40.73.246.9, 139.217.224.20, 139.217.225.145, 40.73.246.115, 139.217.237.127, 40.72.105.235, 40.73.117.207, 139.217.217.17, 52.131.241.28, 52.131.240.224, 52.131.243.97, 52.131.242.248, 52.130.88.144, 163.228.152.24, 40.72.115.83, 40.72.118.84, 52.130.90.203, 40.72.114.189, 52.130.206.249, 52.130.211.82, 52.130.205.5, 163.228.159.157, 52.130.202.8, 163.228.153.150, 40.72.111.145, 40.72.114.136, 52.130.206.199, 40.72.115.166 |
| China East 3 | 163.228.66.175, 163.228.67.29, 163.228.67.80, 163.228.66.154, 52.131.158.96, 52.131.158.97, 52.131.158.98, 52.131.158.99, 52.131.158.100, 52.131.158.101, 52.131.158.102, 52.131.158.103 |
| China North | 40.125.168.87, 40.125.208.107, 139.219.109.179, 143.64.239.49, 143.64.239.22, 143.64.184.129, 143.64.184.61 |
| China North 2 | 40.73.36.99, 40.73.37.76, 40.73.1.190, 40.73.5.24, 139.217.99.144, 139.217.102.119, 139.217.103.121, 139.217.114.65, 52.130.154.185, 52.130.154.14, 52.130.155.76, 52.130.155.75, 40.73.36.125, 40.73.35.208, 40.73.35.239, 40.73.35.32, 159.27.158.214, 159.27.152.97, 139.217.98.105, 139.217.98.110, 139.217.98.194, 40.73.33.181, 159.27.153.43, 159.27.158.6, 159.27.155.94, 159.27.154.80, 139.217.98.90, 139.217.98.10, 139.217.98.149, 40.73.33.73, 159.27.152.246, 159.27.157.216 |
| China North 3 | 159.27.4.202, 159.27.2.137, 159.27.24.136, 159.27.24.31, 143.64.123.37, 143.64.190.236, 143.64.191.5, 143.64.122.196, 143.64.167.106, 143.64.187.39, 143.64.136.136, 143.64.123.26, 143.64.123.16, 143.64.186.125, 143.64.190.151, 143.64.122.183, 143.64.166.106, 143.64.186.220, 143.64.136.129, 143.64.122.254 |