Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Important
This article provides information on using the Azure Machine Learning SDK v1. SDK v1 is deprecated as of March 31, 2025. Support for it will end on June 30, 2026. You can install and use SDK v1 until that date. Your existing workflows using SDK v1 will continue to operate after the end-of-support date. However, they could be exposed to security risks or breaking changes in the event of architectural changes in the product.
We recommend that you transition to the SDK v2 before June 30, 2026. For more information on SDK v2, see What is Azure Machine Learning CLI and Python SDK v2? and the SDK v2 reference.
You can use the built-in examples in Azure Machine Learning designer to quickly get started building your own machine learning pipelines. The Azure Machine Learning designer GitHub repository contains detailed documentation to help you understand some common machine learning scenarios.
Prerequisites
- An Azure subscription. If you don't have an Azure subscription, create a Trial.
- An Azure Machine Learning workspace.
Important
If you don't see graphical elements mentioned in this article, such as buttons in studio or designer, you might not have the right level of permissions for the workspace. Contact your Azure subscription administrator to verify that you have been granted the correct level of access. For more information, see Manage users and roles.
Use sample pipelines
The designer saves a copy of the sample pipelines to your studio workspace. You can edit the pipeline to adapt it to your needs and save it as your own. Use them as a starting point to jumpstart your projects.
Here's how to use a designer sample:
Sign in to the Azure Machine Learning studio, and select the workspace you want to use.
Select Designer from the sidebar menu.
Select Create a new pipeline using classic prebuilt components to create a new pipeline.
Select Show more samples for a complete list of samples.
To run a pipeline, you first need to set a default compute target to run the pipeline on.
Select Pipeline interface to the right of the canvas to open the Settings pane. Select + next to Inputs, then choose Compute target from the dropdown list.
In the dialog that appears, select an existing compute target or create a new one. Select Save.
Select Configure & Submit at the top of the canvas to submit a pipeline job.
Depending on the sample pipeline and compute settings, jobs might take a while to complete. The default compute settings have a minimum node size of 0, which means that the designer must allocate resources after being idle. Repeated pipeline jobs take less time since the compute resources are already allocated. Additionally, the designer uses cached results for each component to further improve efficiency.
After the pipeline finishes running, you can review the pipeline and view the output for each component to learn more. Use the following steps to view component outputs:
Right-click the component in the canvas whose output you'd like to see.
Select Preview data.
Use the samples as starting points for some of the most common machine learning scenarios.
Regression
Explore these built-in regression samples.
| Sample pipeline | Description |
|---|---|
| Regression - Automobile Price Prediction (Basic) | Predict car prices using linear regression. |
| Regression - Automobile Price Prediction (Advanced) | Predict car prices using decision forest and boosted decision tree regressors. Compare models to find the best algorithm. |
Classification
Explore these built-in classification samples. Open the samples to learn more and view the component comments in the designer.
| Sample pipeline | Description |
|---|---|
| Binary Classification with Feature Selection - Income Prediction | Predict income as high or low, using a two-class boosted decision tree. Use Pearson correlation to select features. |
| Binary Classification with custom Python script - Credit Risk Prediction | Classify credit applications as high or low risk. Use the Execute Python Script component to weight your data. |
| Binary Classification - Customer Relationship Prediction | Predict customer churn using two-class boosted decision trees. Use SMOTE to sample biased data. |
| Text Classification - Wikipedia SP 500 Dataset | Classify company types from Wikipedia articles with multiclass logistic regression. |
| Multiclass Classification - Letter Recognition | Create an ensemble of binary classifiers to classify written letters. |
Computer vision
Explore these built-in computer vision samples. Open the samples to learn more and view the component comments in the designer.
| Sample pipeline | Description |
|---|---|
| Image Classification using DenseNet | Use computer vision components to build image classification model based on PyTorch DenseNet. |
Recommender
Explore these built-in recommender samples. Open the samples to learn more and view the component comments in the designer.
| Sample pipeline | Description |
|---|---|
| Wide & Deep-based Recommendation - Restaurant Rating Prediction | Build a restaurant recommender engine from restaurant/user features and ratings. |
| Recommendation - Movie Rating Tweets | Build a movie recommender engine from movie/user features and ratings. |
Utility
Learn more about the samples that demonstrate machine learning utilities and features. Open the samples to learn more and view the component comments in the designer.
| Sample pipeline | Description |
|---|---|
| Binary Classification using Vowpal Wabbit Model - Adult Income Prediction | Vowpal Wabbit is a machine learning system that pushes the frontier of machine learning with techniques such as online, hashing, allreduce, reductions, learning2search, active, and interactive learning. This sample shows how to use Vowpal Wabbit model to build binary classification model. |
| Use Custom R Script - Flight Delay Prediction | Use customized R script to predict if a scheduled passenger flight will be delayed by more than 15 minutes. |
| Cross Validation for Binary Classification - Adult Income Prediction | Use cross validation to build a binary classifier for adult income. |
| Permutation Feature Importance | Use permutation feature importance to compute importance scores for the test dataset. |
| Tune Parameters for Binary Classification - Adult Income Prediction | Use Tune Model Hyperparameters to find optimal hyperparameters to build a binary classifier. |
Datasets
When you create a new pipeline in Azure Machine Learning designer, many sample datasets are included by default. These sample datasets are used by the sample pipelines in the designer homepage.
To the left of the pipeline canvas, in the Component tab, expand the Sample data node. You can use any of these datasets in your own pipeline by dragging it to the canvas.
| Dataset name | Dataset description |
|---|---|
| Adult Census Income Binary Classification dataset | A subset of the 1994 Census database, using working adults over the age of 16 with an adjusted income index of > 100. Usage: Classify people using demographics to predict whether a person earns over 50K a year. Related Research: Kohavi, R., Becker, B., (1996). Irvine, CA: University of California, School of Information and Computer Science |
| Automobile price data (Raw) | Information about automobiles by make and model, including the price, features such as the number of cylinders and MPG, as well as an insurance risk score. The risk score is initially associated with auto price. It is then adjusted for actual risk in a process known to actuaries as symboling. A value of +3 indicates that the auto is risky, and a value of -3 that it is probably safe. Usage: Predict the risk score by features, using regression or multivariate classification. Related Research: Schlimmer, J.C. (1987). Irvine, CA: University of California, School of Information and Computer Science. |
| CRM Appetency Labels Shared | Labels from the KDD Cup 2009 customer relationship prediction challenge (orange_small_train_appetency.labels). |
| CRM Churn Labels Shared | Labels from the KDD Cup 2009 customer relationship prediction challenge (orange_small_train_churn.labels). |
| CRM Upselling Labels Shared | Labels from the KDD Cup 2009 customer relationship prediction challenge (orange_large_train_upselling.labels). |
| Restaurant Feature Data | A set of metadata about restaurants and their features, such as food type, dining style, and location. Usage: Use this dataset, in combination with the other two restaurant datasets, to train and test a recommender system. Related Research: Bache, K. and Lichman, M. (2013). Irvine, CA: University of California, School of Information and Computer Science. |
| Restaurant Ratings | Contains ratings given by users to restaurants on a scale from 0 to 2. Usage: Use this dataset, in combination with the other two restaurant datasets, to train and test a recommender system. Related Research: Bache, K. and Lichman, M. (2013). Irvine, CA: University of California, School of Information and Computer Science. |
| Restaurant Customer Data | A set of metadata about customers, including demographics and preferences. Usage: Use this dataset, in combination with the other two restaurant datasets, to train and test a recommender system. Related Research: Bache, K. and Lichman, M. (2013). Irvine, CA: University of California, School of Information and Computer Science. |
| Weather Dataset | Hourly land-based weather observations from NOAA (merged data from 201304 to 201310). The weather data covers observations made from airport weather stations, covering the time period April-October 2013. Before uploading to the designer, the dataset was processed as follows: - Weather station IDs were mapped to corresponding airport IDs - Weather stations not associated with the 70 busiest airports were filtered out - The Date column was split into separate Year, Month, and Day columns - The following columns were selected: AirportID, Year, Month, Day, Time, TimeZone, SkyCondition, Visibility, WeatherType, DryBulbFarenheit, DryBulbCelsius, WetBulbFarenheit, WetBulbCelsius, DewPointFarenheit, DewPointCelsius, RelativeHumidity, WindSpeed, WindDirection, ValueForWindCharacter, StationPressure, PressureTendency, PressureChange, SeaLevelPressure, RecordType, HourlyPrecip, Altimeter |
| Wikipedia SP 500 Dataset | Data is derived from Wikipedia based on articles of each S&P 500 company, stored as XML data. Before uploading to the designer, the dataset was processed as follows: - Extract text content for each specific company - Remove wiki formatting - Remove nonalphanumeric characters - Convert all text to lowercase - Known company categories were added Note that for some companies an article couldn't be found, so the number of records is less than 500. |
Clean up resources
Important
You can use the resources that you created as prerequisites for other Azure Machine Learning tutorials and how-to articles.
Delete everything
If you don't plan to use anything that you created, delete the entire resource group so you don't incur any charges.
In the Azure portal, select Resource groups under Azure services.
Select the resource group that you created.
Select Delete resource group.
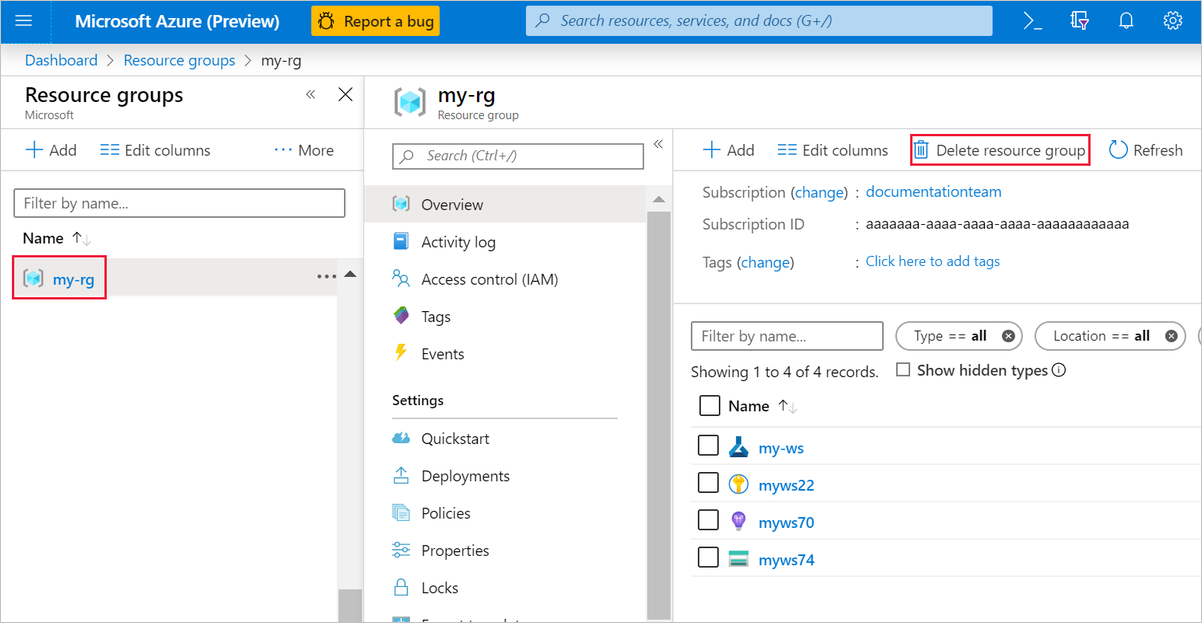
Deleting the resource group also deletes all resources that you created in the designer.
Delete individual assets
In the designer where you created your experiment, delete individual assets by selecting them and then selecting the Delete button.
The compute target that you created here automatically autoscales to zero nodes when it's not being used. This action is taken to minimize charges. If you want to delete the compute target, take these steps:
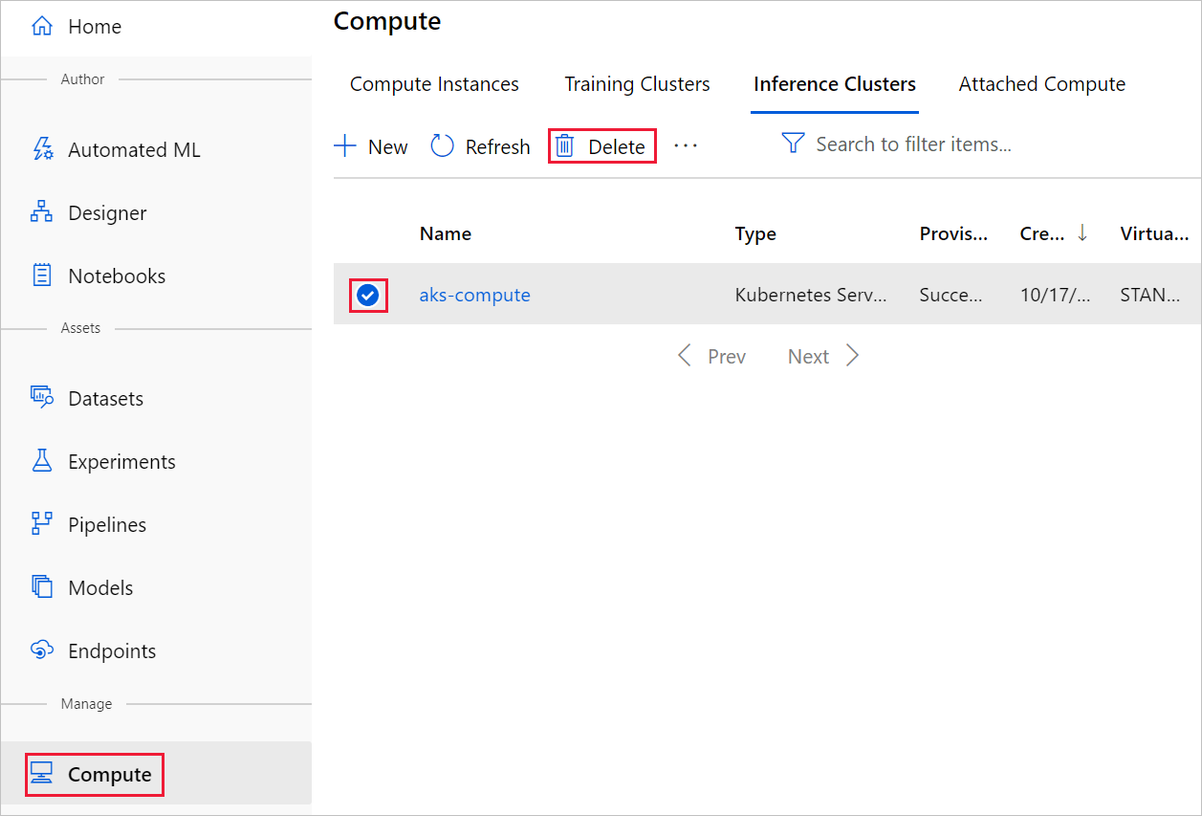
To delete a dataset, go to the storage account by using the Azure portal or Azure Storage Explorer and manually delete those assets.
Related content
Learn the fundamentals of predictive analytics and machine learning with Tutorial: Designer - train a no-code regression model