Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
This article describes the replication concepts when you're migrating VMware virtual machines (VMs) by using the agentless migration method in Azure Migrate.
Replication process
The agentless replication option works by using VMware snapshots and VMware changed block tracking (CBT) technology to replicate data from VM disks. The following block diagram shows you the steps involved when you migrate your VMs by using Azure Migrate.
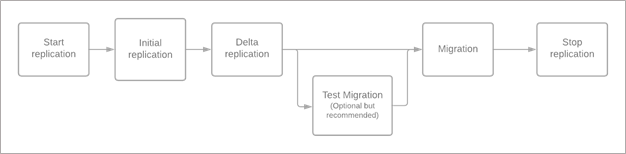
When you configure replication for a VM, it goes through an initial replication phase. During this phase, Azure Migrate takes a VM snapshot. The service then replicates a full copy of data from the snapshot disks to managed disks in your target subscription.
After initial replication for the VM is complete, the replication process transitions to an incremental replication (delta replication) phase. In this phase, data changes that occurred since the beginning of the last completed replication cycle are replicated and written to the replica managed disks. This part of the process keeps replication in sync with changes on the VM.
Azure Migrate uses VMware CBT technology to keep track of changes between replication cycles. At the start of a replication cycle, Azure Migrate takes a VM snapshot. The service uses CBT to get the changes between the current snapshot and the last successfully replicated snapshot. Only the data that changed since the previous completed replication cycle is replicated, to keep replication for the VM in sync. At the end of each replication cycle, the snapshot is released, and Azure Migrate performs snapshot consolidation for the VM.
When you perform the migration operation on a replicating VM, an on-demand delta replication cycle replicates the remaining changes since the last replication cycle. After the on-demand cycle finishes, Azure Migrate creates the VM in Azure by using the replica managed disks that correspond to the VM.
Before you trigger the migration, you must shut down the on-premises VM. Shutting down the VM prevents data loss during migration.
After the migration is successful and the VM restarts in Azure, ensure that you stop the replication of the VM. Stopping the replication deletes the intermediate disks (seed disks) that were created during data replication. You then avoid incurring extra charges associated with the storage transactions on these disks.
Replication cycles
Note
Be sure to check for any existing snapshots on the VM from earlier replication attempts, partner apps, or active backup tools (e.g., VEEAM), as this will block agentless replication setup in Azure Migrate. Snapshot-based backups conflict with Azure Migrate's agentless change tracking and replication process and should not be used concurrently.
A replication cycle is the periodic process of transferring data from an on-premises environment to Azure managed disks. A full replication cycle consists of the following steps:
Create a VMware snapshot for each disk associated with the VM.
Upload data to a log storage account in Azure.
Release the snapshot.
Consolidate VMware disks.
A cycle is complete after the disks are consolidated.
Components for replication
An Azure Migrate appliance has the following on-premises components that are responsible for replication:
- Data replication agent
- Gateway agent
The following table summarizes the Azure components that are created when you use the agentless method of VMware VM migration.
| Component | Region | Subscription | Description |
|---|---|---|---|
| Recovery services vault | Azure Migrate project's region | Azure Migrate project's subscription | Vault that's used to orchestrate data replication. |
| Service bus | Target region | Azure Migrate project's subscription | Component that's used for communication between the cloud service and the Azure Migrate appliance. |
| Log storage account | Target region | Azure Migrate project's subscription | Account that's used to store replication data. The service reads this data and applies it on the customer's managed disk. |
| Gateway storage account | Target region | Azure Migrate project's subscription | Account that's used to store machine states during replication |
| Key vault | Target region | Azure Migrate project's subscription | Vault that manages connection strings for the service bus and access keys for the log storage account. |
| Virtual machine | Target region | Target subscription | VM created in Azure when you migrate. |
| Managed disks | Target region | Target subscription | Managed disks attached to Azure VMs. |
| Network interface cards (NICs) | Target region | Target subscription | NICs attached to the VMs created in Azure. |
Required permissions
When you start replication for the first time, the logged-in user must have the following roles:
- Owner or Contributor and User Access Administrator on the Azure Migrate project's resource group and the target resource group
For the subsequent replications, the logged-in user must have the following roles:
- Owner or Contributor on the Azure Migrate project's resource group and the target resource group
In addition to the preceding roles, the logged-in user needs the following permission at a subscription level: Microsoft.Resources/subscriptions/resourceGroups/read.
Data integrity
There are two stages in every replication cycle, to help ensure data integrity between the on-premises disk (source disk) and the replica disk in Azure (target disk).
Validate replication
The first stage validates that every sector that changed in the source disk is replicated to the target disk. You perform the validation by using bitmaps.
The source disk is divided into sectors of 512 bytes. Every sector in the source disk is mapped to a bit in the bitmap. When data replication starts, Azure Migrate creates a bitmap for all the changed blocks (in delta cycle) in the source disk that needs to be replicated. Similarly, when the data is transferred to the target Azure disk, Azure Migrate creates a bitmap.
After the data transfer finishes successfully, the cloud service compares the two bitmaps to ensure that it didn't miss any changed block. If there's any mismatch between the bitmaps, the cycle is considered failed. Because every cycle is resynchronization, the mismatch is fixed in the next cycle.
Check replicated data
The second stage ensures that the data that's transferred to the Azure disks is the same as the data that was replicated from the source disks.
Every changed block that's uploaded is compressed and encrypted before it's written as a blob in the log storage account. Azure Migrate computes the checksum of this block before compression. This checksum is stored as metadata along with the compressed data.
Upon decompression, Azure Migrate calculates the checksum for the data and compares it with the checksum computed in the source environment. If there's a mismatch, the data isn't written to the Azure disks, and the cycle is considered failed. Because every cycle is resynchronization, the mismatch is fixed in the next cycle.
Security
The Azure Migrate appliance compresses data and encrypts it before uploading it. Data is transmitted over a secure communication channel that uses HTTPS and TLS 1.2 or later. Additionally, Azure Storage automatically encrypts your data when it's persisted to the cloud (encryption at rest).
Replication status
When a VM undergoes replication (data copy), there are several possible states:
- Initial replication queued: The VM is queued for replication or migration because other VMs might be consuming the on-premises resources during replication or migration. After the resources are free, this VM is processed.
- Initial replication in progress: The VM is scheduled for initial replication.
- Initial replication: The VM is undergoing initial replication. When the VM is undergoing initial replication, you can't proceed with test migration and production migration. You can only stop replication at this stage.
- Initial replication (x%): The initial replication is active and has progressed by the shown percentage.
- Delta sync: The VM might be undergoing a delta replication cycle that replicates the remaining data churn since the last replication cycle.
- Pause in progress: The VM is undergoing an active delta replication cycle and is paused.
- Paused: The replication cycles are paused. You can resume the replication cycles by performing the operation to resume replication.
- Resume queued: The VM is queued for resuming replication because other VMs are currently consuming the on-premises resources.
- Resume in progress (x%): The replication cycle is being resumed for the VM and has progressed by the shown percentage.
- Stop replication in progress: Replication cleanup is in progress. When you stop replication, the intermediate managed disks (seed disks) created during replication are deleted. You can learn more about stopping replication later in this article.
- Complete migration in progress: Migration cleanup is in progress. When you complete migration, the intermediate managed disks (seed disks) created during replication are deleted. You can learn more about completing replication later in this article.
- - : When the VM is successfully migrated or when you stop replication, the status changes to a dash. After you complete migration or stop replication and the operation finishes successfully, the VM is removed from the list of replicating machines. You can find the VM on the tab for virtual machines in the replication wizard.
Other states
Initial replication failed: The initial data couldn't be copied for the VM. Follow the remediation guidance to resolve.
Repair pending: There was a problem in the replication cycle. You can select the link to understand possible causes and actions to remediate (as applicable). If you opted for Automatically repair replication by selecting Yes when you triggered replication of VM, the tool tries to repair it for you. Otherwise, select the VM, and then select Repair Replication.
If you didn't opt for Automatically repair replication or if the repair step didn't work for you, stop replication for the VM. Reset the CBT on the VM, and then reconfigure the replication.
Repair replication queued: The VM is queued for replication repair because other VMs are consuming the on-premises resources. After the resources are free, the VM is processed for repair replication.
Resync (x%): The VM is undergoing a data resynchronization. This resynchronization can happen if there was a problem or a mismatch during data replication.
Stop replication/complete migration failed: Select the link to understand the possible causes for failure and actions to remediate (as applicable).
Note
Some VMs go into a queued state to ensure minimal impact on the source environment due to the consumption of storage input/output operations per second (IOPS). These VMs are processed based on the scheduling logic, as described later in this article.
Status of the test migration or production migration
- Test migration pending: The VM is in the delta replication phase. You can now perform test migration (or production migration).
- Test migration clean up pending: After test migration is complete, perform a test migration cleanup to avoid charges in Azure.
- Ready to migrate: The VM is ready for migration to Azure.
- Migration in progress queued: The VM is queued for migration because other VMs are consuming the on-premises resources during replication (or migration). After the resources are free, the VM is processed.
- Test migration/Migration in progress: The VM is undergoing a test migration or a production migration. You can select the link to check the ongoing migration job.
- Date, timestamp: The test migration or production migration happened at this date and time.
- -: Initial replication is in progress. You can perform a test migration or a production migration after the replication process transitions to a delta sync (incremental replication) phase.
Other states
- Completed with info: The test migration or production migration job finished with information. You can select the link to check the last migration job for possible causes and actions to remediate (as applicable).
- Failed: The test migration or production migration job failed. You can select the link to check the last migration job for possible causes and actions to remediate.
Scheduling logic
Initial replication is scheduled when you configure replication for a VM. Incremental replications (delta replications) follow it.
Delta replication cycles are scheduled as follows:
First delta replication cycle is scheduled immediately after the initial replication cycle finishes.
Next delta replication cycles are scheduled according to the following logic:
min[max[1 hour, (<Previous delta replication cycle time>/2)], 12 hours].That is, the next delta replication is scheduled no sooner than 1 hour and no later than 12 hours. For example, if a VM takes 4 hours for a delta replication cycle, the next delta replication cycle is scheduled in 2 hours, and not in the next hour.
Note
The scheduling logic is different after the initial replication finishes. The first delta cycle is scheduled immediately after the initial replication finishes. Subsequent cycles follow the scheduling logic.
When you trigger migration, an on-demand (pre-failover) delta replication cycle occurs for the VM before migration.
Prioritization
Here's the prioritization of VMs for various stages of replication:
- Ongoing VM replications are prioritized over scheduled replications (new replications).
- The on-demand (pre-failover) delta replication cycle has the highest priority, followed by the initial replication cycle. The delta replication cycle has the lowest priority.
Whenever you trigger a migration operation, the on-demand replication cycle for the VM is scheduled. Other ongoing replications have to wait if they're competing for resources.
Constraints
The following constraints help ensure that you don't exceed the IOPS limits on the storage area networks:
- Each Azure Migrate appliance supports the replication of 52 disks in parallel.
- Each ESXi host supports 8 disks. Every ESXi host has a 32-MB NFC buffer. So, you can schedule 8 disks on the host. (Each disk takes up 4 MB of buffer for incident response and disaster recovery.)
- Each datastore can have a maximum of 15 disk snapshots. The only exception is when more than 15 disks are attached to a VM.
Scale-out replication
Azure Migrate supports concurrent replication of 500 VMs. When you plan to replicate more than 300 VMs, you must deploy a scale-out appliance. The scale-out appliance is similar to an Azure Migrate primary appliance but consists only of a gateway agent to facilitate data transfer to Azure.
The following diagram shows the recommended way to use the scale-out appliance.

You can deploy the scale-out appliance anytime after you configure the primary appliance, but it isn't required until 300 VMs are replicating concurrently. When 300 VMs are replicating concurrently, you must deploy the scale-out appliance to proceed.
Stopping replication or completing a migration
When you stop replication, the intermediate managed disks (seed disks) created during replication are deleted. You can stop replication only during an active replication. You can select Complete migration to stop the replication after the VM is migrated.
You can replicate the VM for which the replication is stopped by enabling replication again. If the VM was migrated, you can resume replication and migration again.
As a best practice, you should always complete the migration after the VM migrates successfully to Azure. This practice ensures that you don't incur extra charges for storage transactions on the intermediate managed disks (seed disks).
In some cases, stopping replication takes time. The reason is that whenever you stop replication, the ongoing replication cycle is completed (only when the VM is in delta sync) before deletion of the artifacts.
Impact of churn
You can minimize the amount of data transfer in each replication cycle by allowing the data to fold as much as possible before you schedule the next cycle. Because agentless replication folds in data, the churn pattern is more important than the churn rate. When a file is written again and again, the rate doesn't have much impact. However, a pattern in which every other sector is written causes high churn in the next cycle.
If the current delta replication cycle experiences delays due to high data churn, the initiation of the subsequent cycle might be delayed. A higher volume of data to replicate for a specific disk extends the duration required to create a recovery point. As a result, the final migration cycle takes longer. This situation leads to an extended shutdown window for the source VM.
If the snapshot size increases (due to churn pattern) to an extent that crosses the available capacity of the datastore, there's a risk of the datastore running out of space. This situation can adversely affect production workloads and might render the source VM unresponsive.
To mitigate this risk, we recommend that you increase the datastore size proactively. If multiple VMs that you're replicating concurrently have disks in a datastore that has low available capacity, we advise that you perform migrations one VM at a time to avoid resource contention.
Management of replication
Throttling
You can increase or decrease the replication bandwidth by using NetQosPolicy. The AppNamePrefix value to use in NetQosPolicy is GatewayWindowsService.exe.
To throttle replication traffic from the Azure Migrate appliance, you can create a policy like the following example on the appliance. This policy applies to all the replicating VMs from the Azure Migrate appliance simultaneously.
New-NetQosPolicy -Name "ThrottleReplication" -AppPathNameMatchCondition "GatewayWindowsService.exe" -ThrottleRateActionBitsPerSecond 1MB
You can also increase and decrease replication bandwidth based on a schedule by using the sample script.
Blackout window
Azure Migrate provides a configuration-based mechanism that you can use to specify the time interval during which you don't want any replications to proceed. This interval is called the blackout window. The need for a blackout window can arise in multiple scenarios, such as when the source environment is resource constrained or when you want replication to happen only outside business hours.
Note
The existing replication cycles at the start of the blackout window finish before the replication pauses.
For any migration that you initiate during the blackout window, the final replication doesn't run. The migration fails.
You can specify a blackout window for the appliance by creating or updating the GatewayDataWorker.json file in C:\ProgramData\Microsoft Azure\Config. A typical file has this form:
{
"BlackoutWindows": "List of blackout windows"
}
The list of blackout windows is a pipe-delimited (|) string of the format <DayOfWeek>;<StartTime>;<Duration>. You can specify the duration in days, hours, and minutes. For example, you can specify the blackout windows as:
{
"BlackoutWindows": "Monday;7:00;7h | Tuesday;8:00;1d7h | Wednesday;16:00;1d | Thursday;18:00;5h | Friday;13:00;8m"
}
The first value in the preceding example indicates a blackout window that starts every Monday at 7:00 AM local time (time on the appliance) and lasts 7 hours.
After you create or update GatewayDataWorker.json with these contents, you need to restart the gateway service on the appliance for these changes to take effect.
In the scale-out scenario, the primary appliance and the scale-out appliance honor the blackout windows independently. As a best practice, we recommend keeping the windows consistent across appliances.