Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Business continuity in Azure Database for PostgreSQL refers to the mechanisms, policies, and procedures that enable your business to continue operating in the face of disruption, particularly to its computing infrastructure. In most of the cases, Azure Database for PostgreSQL handles disruptive events that might happen in the cloud environment and keep your applications and business processes running. However, there are some events that can't be handled automatically such as:
- User accidentally deletes or updates a row in a table.
- Earthquake causes a power outage and temporarily disables an availability zone or a region.
- Database patching required to fix a bug or security issue.
Azure Database for PostgreSQL provides features that protect data and mitigates downtime for your mission-critical databases during planned and unplanned downtime events. Built on top of the Azure infrastructure that offers robust resiliency and availability, Azure Database for PostgreSQL has business continuity features that provide another fault protection, address recovery time requirements, and reduce data loss exposure. As you architect your applications, you should consider the downtime tolerance - the recovery time objective (RTO), and data loss exposure - the recovery point objective (RPO). For example, your business-critical database requires stricter uptime than a test database.
The table below illustrates the features that Azure Database for PostgreSQL offers.
| Feature | Description | Considerations |
|---|---|---|
| Automatic backups | An Azure Database for PostgreSQL flexible server instance automatically performs daily backups of your database files and continuously backs up transaction logs. Backups can be retained from 7 days up to 35 days. You're able to restore your database server to any point in time within your backup retention period. RTO is dependent on the size of the data to restore + the time to perform log recovery. It can be from few minutes up to 12 hours. For more details, see Concepts - Backup and Restore. | Backup data remains within the region. |
| Zone redundant high availability | An Azure Database for PostgreSQL flexible server instance can be deployed with zone redundant high availability (HA) configuration where primary and standby servers are deployed in two different availability zones within a region. This HA configuration protects your databases from zone-level failures and also helps with reducing application downtime during planned and unplanned downtime events. Data from the primary server is replicated to the standby replica in synchronous mode. In the event of any disruption to the primary server, the server is automatically failed over to the standby replica. RTO in most cases is expected to be less than 120s. RPO is expected to be zero (no data loss). For more information, see Concepts - High availability. | Supported in general purpose and memory optimized compute tiers. Available only in regions where multiple zones are available. |
| Same zone high availability | An Azure Database for PostgreSQL flexible server instance can be deployed with same zone high availability (HA) configuration where primary and standby servers are deployed in the same availability zone in a region. This HA configuration protects your databases from node-level failures and also helps with reducing application downtime during planned and unplanned downtime events. Data from the primary server is replicated to the standby replica in synchronous mode. In the event of any disruption to the primary server, the server is automatically failed over to the standby replica. RTO in most cases is expected to be less than 120s. RPO is expected to be zero (no data loss). For more information, see Concepts - High availability. | Supported in general purpose and memory optimized compute tiers. |
| Premium-managed disks | Database files are stored in a highly durable and reliable premium-managed storage. This provides data redundancy with three copies of replica stored within an availability zone with automatic data recovery capabilities. For more information, see Managed disks documentation. | Data stored within an availability zone. |
| Zone redundant backup | Azure Database for PostgreSQL flexible server instance backups are automatically and securely stored in a zone redundant storage within a region, if the region supports availability zones. During a zone-level failure where your server is provisioned, and if your server isn't configured with zone redundancy, you can still restore your database using the latest restore point in a different zone. For more information, see Concepts - Backup and Restore. | Only applicable in regions where multiple zones are available. |
| Geo redundant backup | Azure Database for PostgreSQL flexible server instance backups are copied to a remote region. that helps with disaster recovery situation in the event the primary server region is down. | This feature is currently enabled in selected regions. It takes a longer RTO and a higher RPO depending on the size of the data to restore and amount of recovery to perform. |
| Read Replica | Cross Region read replicas can be deployed to protect your databases from region-level failures. Read replicas are updated asynchronously using PostgreSQL's physical replication technology, and may lag the primary. For more information, see Concepts - Read Replicas. | Supported in general purpose and memory optimized compute tiers. |
The following table compares RTO and RPO in a typical workload scenario:
| Capability | Burstable | Production SKU (General Purpose/Memory Optimized) |
|---|---|---|
| Point in Time Restore from backup | Any restore point within the retention period RTO - Varies RPO < 5 Minutes |
Any restore point within the retention period RTO - Varies RPO < 5 Minutes |
| Geo-restore from geo-replicated backups | RTO - Varies RPO < 1 h |
RTO - Varies RPO < 1 h |
| Read replicas | Not Applicable | RTO - Minutes* RPO - Typically ranging from 30 secs to 5 Minutes* |
| High Availability | Not Applicable | RTO < 120 secs RPO = 0 |
Planned downtime events
Below are some planned maintenance scenarios. These events typically incur up to few minutes of downtime, and without data loss.
| Scenario | Process |
|---|---|
| Compute scaling (User-initiated) | During compute scaling operation, active checkpoints are allowed to complete, client connections are drained, any uncommitted transactions are canceled, storage is detached, and then it's shut down. A new Azure Database for PostgreSQL flexible server instance with the same database server name is provisioned with the scaled compute configuration. The storage is then attached to the new server and the database is started which performs recovery, if necessary, before accepting client connections. |
| Scaling up storage (User-initiated) | When a scaling up storage operation is initiated, active checkpoints are allowed to complete, client connections are drained, and any uncommitted transactions are canceled. After that the server is shut down. The storage is scaled to the desired size and then attached to the new server. A recovery is performed if needed before accepting client connections. Note that scaling down of the storage size isn't supported. |
| New software deployment (Azure-initiated) | New features rollout or bug fixes automatically happen as part of service's planned maintenance, and you can schedule when those activities to happen. For more information, check your portal. |
| Minor version upgrades (Azure-initiated) | Azure Database for PostgreSQL automatically patches database servers to the minor version determined by Azure. It happens as part of the service's planned maintenance. The database server is automatically restarted with the new minor version. For more information, see documentation. You can also check your portal. |
When the Azure Database for PostgreSQL flexible server instance is configured with high availability, the service performs the scaling and the maintenance operations on the standby server first. For more information, see Concepts - High availability.
Unplanned downtime mitigation
Unplanned downtimes can occur as a result of unforeseen disruptions such as underlying hardware fault, networking issues, and software bugs. If the database server configured with high availability goes down unexpectedly, then the standby replica is activated and the clients can resume their operations. If not configured with high availability (HA), then if the restart attempt fails, a new database server is automatically provisioned. While an unplanned downtime can't be avoided, Azure Database for PostgreSQL helps mitigate the downtime by automatically performing recovery operations without requiring human intervention.
Though we continuously strive to provide high availability, there are times when Azure Database for PostgreSQL does incur outage causing unavailability of the databases and thus impacting your application. When our service monitoring detects issues that cause widespread connectivity errors, failures or performance issues, the service automatically declares an outage to keep you informed.
Service Outage
In the event of Azure Database for PostgreSQL flexible server instance outage, you can see more details related to the outage in the following places:
- Azure portal banner: If your subscription is identified to be impacted, there will be an outage alert of a Service Issue in your Azure portal Notifications.
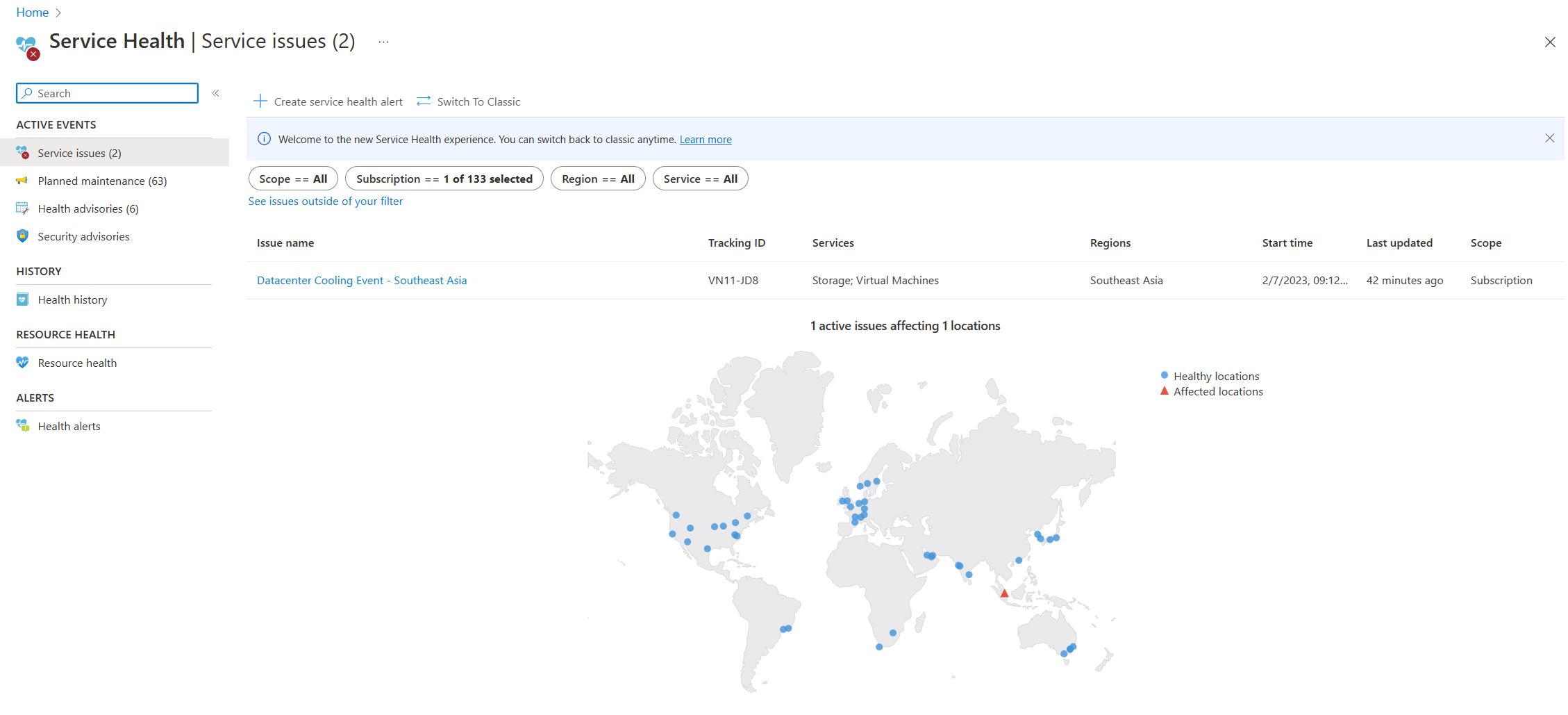
- Service Help: The Service Health page in the Azure portal contains information about Azure data center status globally. Search for "service health" in the search bar in the Azure portal, then view Service issues in the Active events category. You can also view the health of individual resources in the Resource health page of any resource under the Help menu. A sample screenshot of the Service Health page follows.
- Email notification: If you've set up alerts, an email notification will arrive when a service outage impacts your subscription and resource. The emails arrive from "azure-noreply@microsoft.com". The body of the email begins with "The activity log alert ... was triggered by a service issue for the Azure subscription...". For more information on service health alerts, see Receive activity log alerts on Azure service notifications using Azure portal.
Important
As the name implies, temporary tablespaces in PostgreSQL are used for temporary objects, as well as other internal database operations, such as sorting. Therefore we do not recommend creating user schema objects in temporary tablespace, as we don't guarantee durability of such objects after Server restarts, HA failovers, etc.
Unplanned downtime: failure scenarios and service recovery
Below are some unplanned failure scenarios and the recovery process.
| Scenario | Recovery process [Servers configured without zone-redundant HA] |
Recovery process [Servers configured with Zone-redundant HA] |
|---|---|---|
| Database server failure | If the database server is down, Azure will attempt to restart the database server. If that fails, the database server will be restarted on another physical node. The recovery time (RTO) is dependent on various factors including the activity at the time of fault, such as large transaction, and the volume of recovery to be performed during the database server startup process. Applications using the PostgreSQL databases need to be built in a way that they detect and retry dropped connections and failed transactions. |
If the database server failure is detected, the server is failed over to the standby server, thus reducing downtime. For more information, see HA concepts page. RTO is expected to be 60-120s, with zero data loss. |
| Storage failure | Applications don't see any impact for any storage-related issues such as a disk failure or a physical block corruption. As the data is stored in three copies, the copy of the data is served by the surviving storage. The corrupted data block is automatically repaired and a new copy of the data is automatically created. | For any rare and non-recoverable errors such as the entire storage is inaccessible, the Azure Database for PostgreSQL flexible server instance is failed over to the standby replica to reduce the downtime. For more information, see HA concepts page. |
| Logical/user errors | To recover from user errors, such as accidentally dropped tables or incorrectly updated data, you have to perform a point-in-time recovery (PITR). While performing the restore operation, you specify the custom restore point, which is the time right before the error occurred. If you want to restore only a subset of databases or specific tables rather than all databases in the database server, you can restore the database server in a new instance, export the table(s) via pg_dump, and then use pg_restore to restore those tables into your database. |
These user errors aren't protected with high availability as all changes are replicated to the standby replica synchronously. You have to perform point-in-time restore to recover from such errors. |
| Availability zone failure | To recover from a zone-level failure, you can perform point-in-time restore using the backup and choosing a custom restore point with the latest time to restore the latest data. A new Azure Database for PostgreSQL flexible server instance is deployed in another non-impacted zone. The time taken to restore depends on the previous backup and the volume of transaction logs to recover. | An Azure Database for PostgreSQL flexible server instance is automatically failed over to the standby server within 60-120s with zero data loss. For more information, see HA concepts page. |
| Region failure | If your server is configured with geo-redundant backup, you can perform geo-restore in the paired region. A new server will be provisioned and recovered to the last available data that was copied to this region. You can also use cross region read replicas. In the event of region failure you can perform disaster recovery operation by promoting your read replica to be a standalone read-writeable server. RPO is expected to be up to 5 minutes (data loss possible) except in the case of severe regional failure when the RPO can be close to the replication lag at the time of failure. |
Same process. |
Configure your database after recovery from regional failure
- If you are using geo-restore or geo-replica to recover from an outage, you must make sure that the connectivity to the new server is properly configured so that the normal application function can be resumed. You can follow the Post-restore tasks.
- If you've previously set up a diagnostic setting on the original server, make sure to do the same on the target server if necessary as explained in Configure and Access Logs in Azure Database for PostgreSQL.
- Setup telemetry alerts, you need to make sure your existing alert rule settings are updated to map to the new server. For more information about alert rules, see Use the Azure portal to set up alerts on metrics for Azure Database for PostgreSQL.
Important
Deleted servers can be restored. If you delete the server, you can follow our guidance Restore a deleted server to recover. Use Azure resource lock to help prevent accidental deletion of your server.