Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
This article explains how to create and manage search objects using C# and the Azure.Search.Documents client library in the Azure SDK for .NET.
You can use this library for data plane operations, including:
- Create and manage search indexes, data sources, indexers, skillsets, and synonym maps
- Load and manage search documents in an index
- Execute queries, all without having to deal with the details of HTTP and JSON
- Invoke and manage AI enrichment (skillsets) and outputs
The library is distributed as a single NuGet package that includes all APIs used for programmatic access to a search service.
The client library defines classes like SearchIndex, SearchField, and SearchDocument, as well as operations like SearchIndexClient.CreateIndex and SearchClient.Search on the SearchIndexClient and SearchClient classes. These classes are organized into the following namespaces:
Azure.Search.DocumentsAzure.Search.Documents.IndexesAzure.Search.Documents.Indexes.ModelsAzure.Search.Documents.Models
The Azure.Search.Documents client library doesn't provide service management operations, such as creating and scaling search services and managing API keys. If you need to manage your search resources from a .NET application, use the Azure.ResourceManager.Search library in the Azure SDK for .NET.
SDK requirements
Visual Studio 2019 or later.
Download the NuGet package using Tools > NuGet Package Manager > Manage NuGet Packages for Solution in Visual Studio. Search for the package name
Azure.Search.Documents.
The Azure SDK for .NET conforms to .NET Standard 2.0.
Example application
This article teaches by example, relying on the DotNetHowTo code example on GitHub to illustrate fundamental concepts in Azure AI Search, and how to create, load, and query a search index.
For the rest of this article, assume a new index named hotels, populated with a few documents, with several queries that match on results.
The following example shows the main program, with the overall flow:
// This sample shows how to delete, create, upload documents and query an index
static void Main(string[] args)
{
IConfigurationBuilder builder = new ConfigurationBuilder().AddJsonFile("appsettings.json");
IConfigurationRoot configuration = builder.Build();
SearchIndexClient indexClient = CreateSearchIndexClient(configuration);
string indexName = configuration["SearchIndexName"];
Console.WriteLine("{0}", "Deleting index...\n");
DeleteIndexIfExists(indexName, indexClient);
Console.WriteLine("{0}", "Creating index...\n");
CreateIndex(indexName, indexClient);
SearchClient searchClient = indexClient.GetSearchClient(indexName);
Console.WriteLine("{0}", "Uploading documents...\n");
UploadDocuments(searchClient);
SearchClient indexClientForQueries = CreateSearchClientForQueries(indexName, configuration);
Console.WriteLine("{0}", "Run queries...\n");
RunQueries(indexClientForQueries);
Console.WriteLine("{0}", "Complete. Press any key to end application...\n");
Console.ReadKey();
}
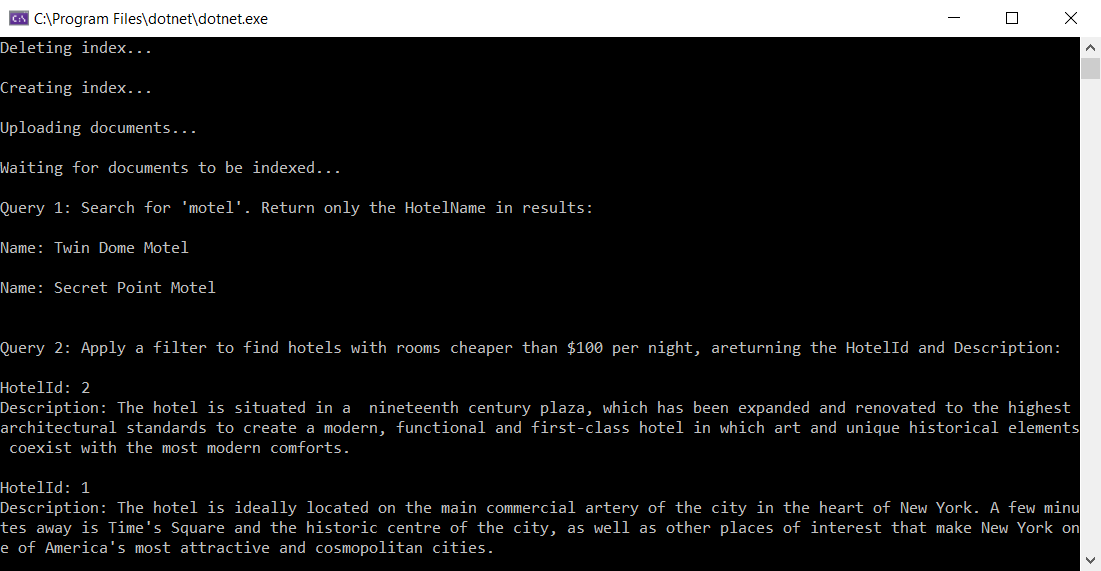
Next is a partial screenshot of the output, assuming you run this application with a valid service name and API keys:
Client types
The client library uses three client types for various operations: SearchIndexClient to create, update, or delete indexes, SearchClient to load or query an index, and SearchIndexerClient to work with indexers and skillsets. This article focuses on the first two.
At a minimum, all of the clients require the service name or endpoint, and an API key. It's common to provide this information in a configuration file, similar to what you find in the appsettings.json file of the DotNetHowTo sample application. To read from the configuration file, add using Microsoft.Extensions.Configuration; to your program.
The following statement creates the index client used to create, update, or delete indexes. It takes a service endpoint and admin API key.
private static SearchIndexClient CreateSearchIndexClient(IConfigurationRoot configuration)
{
string searchServiceEndPoint = configuration["YourSearchServiceEndPoint"];
string adminApiKey = configuration["YourSearchServiceAdminApiKey"];
SearchIndexClient indexClient = new SearchIndexClient(new Uri(searchServiceEndPoint), new AzureKeyCredential(adminApiKey));
return indexClient;
}
The next statement creates the search client used to load documents or run queries. SearchClient requires an index. You need an admin API key to load documents, but you can use a query API key to run queries.
string indexName = configuration["SearchIndexName"];
private static SearchClient CreateSearchClientForQueries(string indexName, IConfigurationRoot configuration)
{
string searchServiceEndPoint = configuration["YourSearchServiceEndPoint"];
string queryApiKey = configuration["YourSearchServiceQueryApiKey"];
SearchClient searchClient = new SearchClient(new Uri(searchServiceEndPoint), indexName, new AzureKeyCredential(queryApiKey));
return searchClient;
}
Note
If you provide an invalid key for the import operation (for example, a query key where an admin key was required), the SearchClient throws a CloudException with the error message Forbidden the first time you call an operation method on it. If this happens to you, double-check the API key.
Delete the index
In the early stages of development, you might want to include a DeleteIndex statement to delete a work-in-progress index so that you can recreate it with an updated definition. Sample code for Azure AI Search often includes a deletion step so that you can rerun the sample.
The following line calls DeleteIndexIfExists:
Console.WriteLine("{0}", "Deleting index...\n");
DeleteIndexIfExists(indexName, indexClient);
This method uses the given SearchIndexClient to check if the index exists, and if so, deletes it:
private static void DeleteIndexIfExists(string indexName, SearchIndexClient indexClient)
{
try
{
if (indexClient.GetIndex(indexName) != null)
{
indexClient.DeleteIndex(indexName);
}
}
catch (RequestFailedException e) when (e.Status == 404)
{
// Throw an exception if the index name isn't found
Console.WriteLine("The index doesn't exist. No deletion occurred.");
Note
The example code in this article uses the synchronous methods for simplicity, but you should use the asynchronous methods in your own applications to keep them scalable and responsive. For example, in the previous method, you could use DeleteIndexAsync instead of DeleteIndex.
Create an index
You can use SearchIndexClient to create an index.
The following method creates a new SearchIndex object with a list of SearchField objects that define the schema of the new index. Each field has a name, data type, and several attributes that define its search behavior.
Fields can be defined from a model class using FieldBuilder. The FieldBuilder class uses reflection to create a list of SearchField objects for the index by examining the public properties and attributes of the given Hotel model class. We'll take a closer look at the Hotel class later on.
private static void CreateIndex(string indexName, SearchIndexClient indexClient)
{
FieldBuilder fieldBuilder = new FieldBuilder();
var searchFields = fieldBuilder.Build(typeof(Hotel));
var definition = new SearchIndex(indexName, searchFields);
indexClient.CreateOrUpdateIndex(definition);
}
Besides fields, you could also add scoring profiles, suggesters, or CORS options to the index (these parameters are omitted from the sample for brevity). You can find more information about the SearchIndex object and its constituent parts in the SearchIndex properties list, as well as in the REST API reference.
Note
You can always create the list of Field objects directly instead of using FieldBuilder if needed. For example, you might not want to use a model class or you might need to use an existing model class that you don't want to modify by adding attributes.
Call CreateIndex in Main()
Main creates a new hotels index by calling the preceding method:
Console.WriteLine("{0}", "Creating index...\n");
CreateIndex(indexName, indexClient);
Use a model class for data representation
The DotNetHowTo sample uses model classes for the Hotel, Address, and Room data structures. Hotel references Address, a single level complex type (a multi-part field), and Room (a collection of multi-part fields).
You can use these types to create and load the index, and to structure the response from a query:
// Use-case: <Hotel> in a field definition
FieldBuilder fieldBuilder = new FieldBuilder();
var searchFields = fieldBuilder.Build(typeof(Hotel));
// Use-case: <Hotel> in a response
private static void WriteDocuments(SearchResults<Hotel> searchResults)
{
foreach (SearchResult<Hotel> result in searchResults.GetResults())
{
Console.WriteLine(result.Document);
}
Console.WriteLine();
}
An alternative approach is to add fields to an index directly. The following example shows just a few fields.
SearchIndex index = new SearchIndex(indexName)
{
Fields =
{
new SimpleField("hotelId", SearchFieldDataType.String) { IsKey = true, IsFilterable = true, IsSortable = true },
new SearchableField("hotelName") { IsFilterable = true, IsSortable = true },
new SearchableField("hotelCategory") { IsFilterable = true, IsSortable = true },
new SimpleField("baseRate", SearchFieldDataType.Int32) { IsFilterable = true, IsSortable = true },
new SimpleField("lastRenovationDate", SearchFieldDataType.DateTimeOffset) { IsFilterable = true, IsSortable = true }
}
};
Field definitions
Your data model in .NET and its corresponding index schema should support the search experience you'd like to give to your end user. Each top level object in .NET, such as a search document in a search index, corresponds to a search result you would present in your user interface. For example, in a hotel search application, your end users might want to search by hotel name, features of the hotel, or the characteristics of a particular room.
Within each class, a field is defined with a data type and attributes that determine how it's used. The name of each public property in each class maps to a field with the same name in the index definition.
Take a look at the following snippet that pulls several field definitions from the Hotel class. Address and Rooms are C# types with their own class definitions (refer to the sample code if you want to view them). Both are complex types. For more information, see How to model complex types.
public partial class Hotel
{
[SimpleField(IsKey = true, IsFilterable = true)]
public string HotelId { get; set; }
[SearchableField(IsSortable = true)]
public string HotelName { get; set; }
[SearchableField(AnalyzerName = LexicalAnalyzerName.Values.EnLucene)]
public string Description { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public string Category { get; set; }
[JsonIgnore]
public bool? SmokingAllowed => (Rooms != null) ? Array.Exists(Rooms, element => element.SmokingAllowed == true) : (bool?)null;
[SearchableField]
public Address Address { get; set; }
public Room[] Rooms { get; set; }
Choose a field class
When defining fields, you can use the base SearchField class, or you can use derivative helper models that serve as templates, with pre-configured properties.
Exactly one field in your index must serve as the document key (IsKey = true). It must be a string, and it must uniquely identify each document. It's also required to have IsHidden = true, which means it can't be visible in search results.
| Field type | Description and usage |
|---|---|
SearchField |
Base class, with most properties set to null, except Name which is required, and AnalyzerName which defaults to standard Lucene. |
SimpleField |
Helper model. Can be any data type, is always non-searchable (it's ignored for full text search queries), and is retrievable (it's not hidden). Other attributes are off by default, but can be enabled. You might use a SimpleField for document IDs or fields used only in filters, facets, or scoring profiles. If so, be sure to apply any attributes that are necessary for the scenario, such as IsKey = true for a document ID. For more information, see SimpleFieldAttribute.cs in source code. |
SearchableField |
Helper model. Must be a string, and is always searchable and retrievable. Other attributes are off by default, but can be enabled. Because this field type is searchable, it supports synonyms and the full complement of analyzer properties. For more information, see the SearchableFieldAttribute.cs in source code. |
Whether you use the basic SearchField API or either one of the helper models, you must explicitly enable filter, facet, and sort attributes. For example, IsFilterable, IsSortable, and IsFacetable must be explicitly attributed, as shown in the previous sample.
Add field attributes
Notice how each field is decorated with attributes such as IsFilterable, IsSortable, IsKey, and AnalyzerName. These attributes map directly to the corresponding field attributes in an Azure AI Search index. The FieldBuilder class uses these properties to construct field definitions for the index.
Field type mapping
The .NET types of the properties map to their equivalent field types in the index definition. For example, the Category string property maps to the category field, which is of type Edm.String. There are similar type mappings between bool?, Edm.Boolean, DateTimeOffset?, and Edm.DateTimeOffset and so on.
Did you happen to notice the SmokingAllowed property?
[JsonIgnore]
public bool? SmokingAllowed => (Rooms != null) ? Array.Exists(Rooms, element => element.SmokingAllowed == true) : (bool?)null;
The JsonIgnore attribute on this property tells the FieldBuilder to not serialize it to the index as a field. This is a great way to create client-side calculated properties that you can use as helpers in your application. In this case, the SmokingAllowed property reflects whether any Room in the Rooms collection allows smoking. If all are false, it indicates that the entire hotel doesn't allow smoking.
Load an index
The next step in Main populates the newly created hotels index. This index population is done in the following method:
(Some code replaced with ... for illustration purposes. See the full sample solution for the full data population code.)
private static void UploadDocuments(SearchClient searchClient)
{
IndexDocumentsBatch<Hotel> batch = IndexDocumentsBatch.Create(
IndexDocumentsAction.Upload(
new Hotel()
{
HotelId = "1",
HotelName = "Stay-Kay City Hotel",
...
Address = new Address()
{
StreetAddress = "677 5th Ave",
...
},
Rooms = new Room[]
{
new Room()
{
Description = "Budget Room, 1 Queen Bed (Cityside)",
...
},
new Room()
{
Description = "Budget Room, 1 King Bed (Mountain View)",
...
},
new Room()
{
Description = "Deluxe Room, 2 Double Beds (City View)",
...
}
}
}),
IndexDocumentsAction.Upload(
new Hotel()
{
HotelId = "2",
HotelName = "Old Century Hotel",
...
{
StreetAddress = "140 University Town Center Dr",
...
},
Rooms = new Room[]
{
new Room()
{
Description = "Suite, 2 Double Beds (Mountain View)",
...
},
new Room()
{
Description = "Standard Room, 1 Queen Bed (City View)",
...
},
new Room()
{
Description = "Budget Room, 1 King Bed (Waterfront View)",
...
}
}
}),
IndexDocumentsAction.Upload(
new Hotel()
{
HotelId = "3",
HotelName = "Gastronomic Landscape Hotel",
...
Address = new Address()
{
StreetAddress = "3393 Peachtree Rd",
...
},
Rooms = new Room[]
{
new Room()
{
Description = "Standard Room, 2 Queen Beds (Amenities)",
...
},
new Room ()
{
Description = "Standard Room, 2 Double Beds (Waterfront View)",
...
},
new Room()
{
Description = "Deluxe Room, 2 Double Beds (Cityside)",
...
}
}
}
};
try
{
IndexDocumentsResult result = searchClient.IndexDocuments(batch);
}
catch (Exception)
{
// Sometimes when your Search service is under load, indexing will fail for some of the documents in
// the batch. Depending on your application, you can take compensating actions like delaying and
// retrying. For this simple demo, we just log the failed document keys and continue.
Console.WriteLine("Failed to index some of the documents: {0}");
}
Console.WriteLine("Waiting for documents to be indexed...\n");
Thread.Sleep(2000);
This method has four parts. The first creates an array of three Hotel objects each with three Room objects that serve as our input data to upload to the index. This data is hard-coded for simplicity. In an actual application, data likely comes from an external data source such as a SQL database.
The second part creates an IndexDocumentsBatch containing the documents. You specify the operation you want to apply to the batch at the time you create it, in this case by calling IndexDocumentsAction.Upload. The batch is then uploaded to the Azure AI Search index by the IndexDocuments method.
Note
In this example, you're just uploading documents. If you wanted to merge changes into existing documents or delete documents, you could create batches by calling IndexDocumentsAction.Merge, IndexDocumentsAction.MergeOrUpload, or IndexDocumentsAction.Delete instead. You can also mix different operations in a single batch by calling IndexBatch.New, which takes a collection of IndexDocumentsAction objects, each of which tells Azure AI Search to perform a particular operation on a document. You can create each IndexDocumentsAction with its own operation by calling the corresponding method such as IndexDocumentsAction.Merge, IndexAction.Upload, and so on.
The third part of this method is a catch block that handles an important error case for indexing. If your search service fails to index some of the documents in the batch, a RequestFailedException is thrown. An exception can happen if you're indexing documents while your service is under heavy load. We strongly recommend explicitly handling this case in your code. You can delay and then retry indexing the documents that failed, or you can log and continue like the sample does, or you can do something else depending on your application's data consistency requirements. An alternative is to use SearchIndexingBufferedSender for intelligent batching, automatic flushing, and retries for failed indexing actions. For more context, see the SearchIndexingBufferedSender example.
Finally, the UploadDocuments method delays for two seconds. Indexing happens asynchronously in your search service, so the sample application needs to wait a short time to ensure that the documents are available for searching. Delays like this are typically only necessary in demos, tests, and sample applications.
Call UploadDocuments in Main()
The following code snippet sets up an instance of SearchClient using the GetSearchClient method of indexClient. The indexClient uses an admin API key on its requests, which is required for loading or refreshing documents.
An alternate approach is to call SearchClient directly, passing in an admin API key on AzureKeyCredential.
SearchClient searchClient = indexClient.GetSearchClient(indexName);
Console.WriteLine("{0}", "Uploading documents...\n");
UploadDocuments(searchClient);
Run queries
First, set up a SearchClient that reads the service endpoint and query API key from appsettings.json:
private static SearchClient CreateSearchClientForQueries(string indexName, IConfigurationRoot configuration)
{
string searchServiceEndPoint = configuration["YourSearchServiceEndPoint"];
string queryApiKey = configuration["YourSearchServiceQueryApiKey"];
SearchClient searchClient = new SearchClient(new Uri(searchServiceEndPoint), indexName, new AzureKeyCredential(queryApiKey));
return searchClient;
}
Second, define a method that sends a query request.
Each time the method executes a query, it creates a new SearchOptions object. This object is used to specify additional options for the query such as sorting, filtering, paging, and faceting. In this method, we're setting the Filter, Select, and OrderBy property for different queries. For more information about the search query expression syntax, Simple query syntax.
The next step is query execution. Running the search is done using the SearchClient.Search method. For each query, pass the search text to use as a string (or "*" if there's no search text), plus the search options created earlier. We also specify Hotel as the type parameter for SearchClient.Search, which tells the SDK to deserialize documents in the search results into objects of type Hotel.
private static void RunQueries(SearchClient searchClient)
{
SearchOptions options;
SearchResults<Hotel> results;
Console.WriteLine("Query 1: Search for 'motel'. Return only the HotelName in results:\n");
options = new SearchOptions();
options.Select.Add("HotelName");
results = searchClient.Search<Hotel>("motel", options);
WriteDocuments(results);
Console.Write("Query 2: Apply a filter to find hotels with rooms cheaper than $100 per night, ");
Console.WriteLine("returning the HotelId and Description:\n");
options = new SearchOptions()
{
Filter = "Rooms/any(r: r/BaseRate lt 100)"
};
options.Select.Add("HotelId");
options.Select.Add("Description");
results = searchClient.Search<Hotel>("*", options);
WriteDocuments(results);
Console.Write("Query 3: Search the entire index, order by a specific field (lastRenovationDate) ");
Console.Write("in descending order, take the top two results, and show only hotelName and ");
Console.WriteLine("lastRenovationDate:\n");
options =
new SearchOptions()
{
Size = 2
};
options.OrderBy.Add("LastRenovationDate desc");
options.Select.Add("HotelName");
options.Select.Add("LastRenovationDate");
results = searchClient.Search<Hotel>("*", options);
WriteDocuments(results);
Console.WriteLine("Query 4: Search the HotelName field for the term 'hotel':\n");
options = new SearchOptions();
options.SearchFields.Add("HotelName");
//Adding details to select, because "Location" isn't supported yet when deserializing search result to "Hotel"
options.Select.Add("HotelId");
options.Select.Add("HotelName");
options.Select.Add("Description");
options.Select.Add("Category");
options.Select.Add("Tags");
options.Select.Add("ParkingIncluded");
options.Select.Add("LastRenovationDate");
options.Select.Add("Rating");
options.Select.Add("Address");
options.Select.Add("Rooms");
results = searchClient.Search<Hotel>("hotel", options);
WriteDocuments(results);
}
Third, define a method that writes the response, printing each document to the console:
private static void WriteDocuments(SearchResults<Hotel> searchResults)
{
foreach (SearchResult<Hotel> result in searchResults.GetResults())
{
Console.WriteLine(result.Document);
}
Console.WriteLine();
}
Call RunQueries in Main()
SearchClient indexClientForQueries = CreateSearchClientForQueries(indexName, configuration);
Console.WriteLine("{0}", "Running queries...\n");
RunQueries(indexClientForQueries);
Explore query constructs
Let's take a closer look at each of the queries in turn. Here's the code to execute the first query:
options = new SearchOptions();
options.Select.Add("HotelName");
results = searchClient.Search<Hotel>("motel", options);
WriteDocuments(results);
In this case, we're searching the entire index for the word motel in any searchable field and we only want to retrieve the hotel names, as specified by the Select option. Here are the results:
Name: Stay-Kay City Hotel
Name: Old Century Hotel
In the second query, use a filter to select rooms with a nightly rate of less than $100. Return only the hotel ID and description in the results:
options = new SearchOptions()
{
Filter = "Rooms/any(r: r/BaseRate lt 100)"
};
options.Select.Add("HotelId");
options.Select.Add("Description");
results = searchClient.Search<Hotel>("*", options);
This query uses an OData $filter expression, Rooms/any(r: r/BaseRate lt 100), to filter the documents in the index. It uses the any operator to apply the 'BaseRate lt 100' to every item in the Rooms collection. For more information, see OData filter syntax.
In the third query, find the top two hotels that have been most recently renovated, and show the hotel name and last renovation date. Here's the code:
options =
new SearchOptions()
{
Size = 2
};
options.OrderBy.Add("LastRenovationDate desc");
options.Select.Add("HotelName");
options.Select.Add("LastRenovationDate");
results = searchClient.Search<Hotel>("*", options);
WriteDocuments(results);
In the last query, find all hotels names that match the word hotel:
options.Select.Add("HotelId");
options.Select.Add("HotelName");
options.Select.Add("Description");
options.Select.Add("Category");
options.Select.Add("Tags");
options.Select.Add("ParkingIncluded");
options.Select.Add("LastRenovationDate");
options.Select.Add("Rating");
options.Select.Add("Address");
options.Select.Add("Rooms");
results = searchClient.Search<Hotel>("hotel", options);
WriteDocuments(results);
This section concludes this introduction to the .NET SDK, but don't stop here. The next section suggests other resources for learning more about programming with Azure AI Search.