Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Azure Stream Analytics does not provide automatic geo-failover, but you can achieve geo-redundancy by deploying identical Stream Analytics jobs in multiple Azure regions. Each job connects to a local input and local output sources. It is the responsibility of your application to both send input data into the two regional inputs and reconcile between the two regional outputs. The Stream Analytics jobs are two separate entities.
The following diagram depicts a sample geo-redundant Stream Analytics job deployment with Event Hub input and Azure Database output.
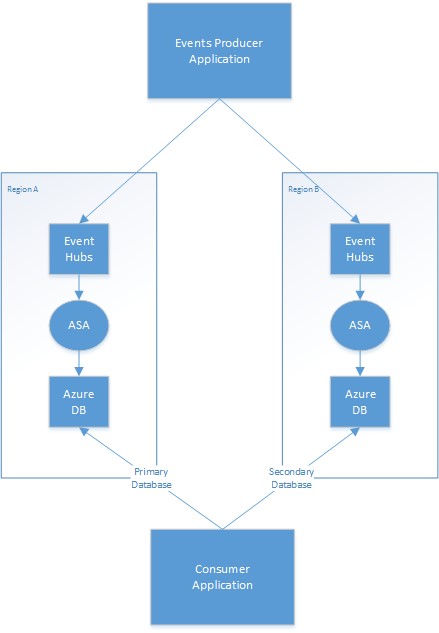
Primary/secondary strategy
Your application needs to manage which region's output database is considered the primary and which is considered the secondary. On a primary region failure, the application switches to the secondary database and starts reading updates from that database. The actual mechanism that allows minimizing duplicate reads depends on your application. You can simplify this process by writing additional information to the output. For example, you can add a timestamp or a sequence ID to each output to make skipping duplicate rows a trivial operation. Once the primary region is restored, it catches up with the secondary database using similar mechanics.
Although different input and output types allow for different geo-replication options, we recommend using the pattern outlined in this article to achieve geo-redundancy because it provides flexibility and control for the both event producers and event consumers.