Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
The OPENROWSET(BULK...) function allows you to access files in Azure Storage. OPENROWSET function reads content of a remote data source (for example file) and returns the content as a set of rows. Within the serverless SQL pool resource, the OPENROWSET bulk rowset provider is accessed by calling the OPENROWSET function and specifying the BULK option.
The OPENROWSET function can be referenced in the FROM clause of a query as if it were a table name OPENROWSET. It supports bulk operations through a built-in BULK provider that enables data from a file to be read and returned as a rowset.
Note
The OPENROWSET function is not supported in dedicated SQL pool.
Data source
OPENROWSET function in Synapse SQL reads the content of the files from a data source. The data source is an Azure storage account and it can be explicitly referenced in the OPENROWSET function or can be dynamically inferred from URL of the files that you want to read.
The OPENROWSET function can optionally contain a DATA_SOURCE parameter to specify the data source that contains files.
OPENROWSETwithoutDATA_SOURCEcan be used to directly read the contents of the files from the URL location specified asBULKoption:SELECT * FROM OPENROWSET(BULK 'http://<storage account>.dfs.core.chinacloudapi.cn/container/folder/*.parquet', FORMAT = 'PARQUET') AS [file]
This is a quick and easy way to read the content of the files without preconfiguration. This option enables you to use the basic authentication option to access the storage (Microsoft Entra passthrough for Microsoft Entra logins and SAS token for SQL logins).
OPENROWSETwithDATA_SOURCEcan be used to access files on specified storage account:SELECT * FROM OPENROWSET(BULK '/folder/*.parquet', DATA_SOURCE='storage', --> Root URL is in LOCATION of DATA SOURCE FORMAT = 'PARQUET') AS [file]This option enables you to configure location of the storage account in the data source and specify the authentication method that should be used to access storage.
Important
OPENROWSETwithoutDATA_SOURCEprovides quick and easy way to access the storage files but offers limited authentication options. As an example, Microsoft Entra principals can access files only using their Microsoft Entra identity or publicly available files. If you need more powerful authentication options, useDATA_SOURCEoption and define credential that you want to use to access storage.
Security
A database user must have ADMINISTER BULK OPERATIONS permission to use the OPENROWSET function.
The storage administrator must also enable a user to access the files by providing valid SAS token or enabling Microsoft Entra principal to access storage files. Learn more about storage access control in this article.
OPENROWSET use the following rules to determine how to authenticate to storage:
- In
OPENROWSETwithoutDATA_SOURCEauthentication mechanism depends on caller type.- Any user can use
OPENROWSETwithoutDATA_SOURCEto read publicly available files on Azure storage. - Microsoft Entra logins can access protected files using their own Microsoft Entra identity if Azure storage allows the Microsoft Entra user to access underlying files (for example, if the caller has
Storage Readerpermission on Azure storage). - SQL logins can also use
OPENROWSETwithoutDATA_SOURCEto access publicly available files, files protected using SAS token, or Managed Identity of Synapse workspace. You would need to create server-scoped credential to allow access to storage files.
- Any user can use
- In
OPENROWSETwithDATA_SOURCEauthentication mechanism is defined in database scoped credential assigned to the referenced data source. This option enables you to access publicly available storage, or access storage using SAS token, Managed Identity of workspace, or Microsoft Entra identity of caller (if caller is Microsoft Entra principal). IfDATA_SOURCEreferences Azure storage that isn't public, you would need to create database-scoped credential and reference it inDATA SOURCEto allow access to storage files.
Caller must have REFERENCES permission on credential to use it to authenticate to storage.
Syntax
--OPENROWSET syntax for reading Parquet or Delta Lake files
OPENROWSET
( { BULK 'unstructured_data_path' , [DATA_SOURCE = <data source name>, ]
FORMAT= ['PARQUET' | 'DELTA'] }
)
[WITH ( {'column_name' 'column_type' }) ]
[AS] table_alias(column_alias,...n)
--OPENROWSET syntax for reading delimited text files
OPENROWSET
( { BULK 'unstructured_data_path' , [DATA_SOURCE = <data source name>, ]
FORMAT = 'CSV'
[ <bulk_options> ]
[ , <reject_options> ] }
)
WITH ( {'column_name' 'column_type' [ 'column_ordinal' | 'json_path'] })
[AS] table_alias(column_alias,...n)
<bulk_options> ::=
[ , FIELDTERMINATOR = 'char' ]
[ , ROWTERMINATOR = 'char' ]
[ , ESCAPECHAR = 'char' ]
[ , FIRSTROW = 'first_row' ]
[ , FIELDQUOTE = 'quote_characters' ]
[ , DATA_COMPRESSION = 'data_compression_method' ]
[ , PARSER_VERSION = 'parser_version' ]
[ , HEADER_ROW = { TRUE | FALSE } ]
[ , DATAFILETYPE = { 'char' | 'widechar' } ]
[ , CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' } ]
[ , ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}' ]
<reject_options> ::=
{
| MAXERRORS = reject_value,
| ERRORFILE_DATA_SOURCE = <data source name>,
| ERRORFILE_LOCATION = '/REJECT_Directory'
}
Arguments
You have three choices for input files that contain the target data for querying. Valid values are:
'CSV' - Includes any delimited text file with row/column separators. Any character can be used as a field separator, such as TSV: FIELDTERMINATOR = tab.
'PARQUET' - Binary file in Parquet format.
'DELTA' - A set of Parquet files organized in Delta Lake (preview) format.
Values with blank spaces aren't valid. For example, 'CSV ' isn't a valid value.
'unstructured_data_path'
The unstructured_data_path that establishes a path to the data could be an absolute or relative path:
- Absolute path in the format
\<prefix>://\<storage_account_path>/\<storage_path>enables a user to directly read the files. - Relative path in the format
<storage_path>that must be used with theDATA_SOURCEparameter and describes the file pattern within the <storage_account_path> location defined inEXTERNAL DATA SOURCE.
Below you'll find the relevant <storage account path> values that will link to your particular external data source.
| External Data Source | Prefix | Storage account path |
|---|---|---|
| Azure Blob Storage | http[s] | <storage_account>.blob.core.chinacloudapi.cn/path/file |
| Azure Blob Storage | wasb[s] | <container>@<storage_account>.blob.core.chinacloudapi.cn/path/file |
| Azure Data Lake Store Gen2 | http[s] | <storage_account>.dfs.core.chinacloudapi.cn/path/file |
| Azure Data Lake Store Gen2 | abfs[s] | <file_system>@<account_name>.dfs.core.chinacloudapi.cn/path/file |
'<storage_path>'
Specifies a path within your storage that points to the folder or file you want to read. If the path points to a container or folder, all files will be read from that particular container or folder. Files in subfolders won't be included.
You can use wildcards to target multiple files or folders. Usage of multiple nonconsecutive wildcards is allowed.
Below is an example that reads all csv files starting with population from all folders starting with /csv/population:
https://sqlondemandstorage.blob.core.windows.net/csv/population*/population*.csv
If you specify the unstructured_data_path to be a folder, a serverless SQL pool query will retrieve files from that folder.
You can instruct serverless SQL pool to traverse folders by specifying /* at the end of path as in example:
https://sqlondemandstorage.blob.core.windows.net/csv/population/**
Note
Unlike Hadoop and PolyBase, serverless SQL pool doesn't return subfolders unless you specify /** at the end of path. Just like Hadoop and PolyBase, it doesn't return files for which the file name begins with an underline (_) or a period (.).
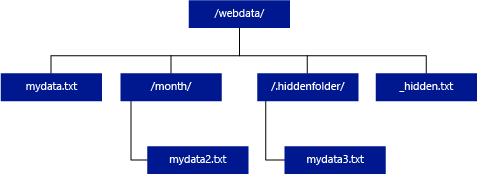
In the example below, if the unstructured_data_path=https://mystorageaccount.dfs.core.chinacloudapi.cn/webdata/, a serverless SQL pool query will return rows from mydata.txt. It won't return mydata2.txt and mydata3.txt because they're located in a subfolder.
[WITH ( {'column_name' 'column_type' [ 'column_ordinal'] }) ]
The WITH clause allows you to specify columns that you want to read from files.
For CSV data files, to read all the columns, provide column names and their data types. If you want a subset of columns, use ordinal numbers to pick the columns from the originating data files by ordinal. Columns will be bound by the ordinal designation. If HEADER_ROW = TRUE is used, then column binding is done by column name instead of ordinal position.
Tip
You can omit WITH clause for CSV files also. Data types will be automatically inferred from file content. You can use HEADER_ROW argument to specify existence of header row in which case column names will be read from header row. For details check automatic schema discovery.
For Parquet or Delta Lake files, provide column names that match the column names in the originating data files. Columns will be bound by name and is case-sensitive. If the WITH clause is omitted, all columns from Parquet files will be returned.
Important
Column names in Parquet and Delta Lake files are case sensitive. If you specify column name with casing different from column name casing in the files, the
NULLvalues will be returned for that column.
column_name = Name for the output column. If provided, this name overrides the column name in the source file and column name provided in JSON path if there's one. If json_path isn't provided, it will be automatically added as '$.column_name'. Check json_path argument for behavior.
column_type = Data type for the output column. The implicit data type conversion will take place here.
column_ordinal = Ordinal number of the column in the source file(s). This argument is ignored for Parquet files since binding is done by name. The following example would return a second column only from a CSV file:
WITH (
--[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2 2
--[year] smallint,
--[population] bigint
)
json_path = JSON path expression to column or nested property. Default path mode is lax.
Note
In strict mode query will fail with error if provided path does not exist. In lax mode query will succeed and JSON path expression will evaluate to NULL.
<bulk_options>
FIELDTERMINATOR ='field_terminator'
Specifies the field terminator to be used. The default field terminator is a comma (",").
ROWTERMINATOR ='row_terminator'`
Specifies the row terminator to be used. If row terminator isn't specified, one of default terminators will be used. Default terminators for PARSER_VERSION = '1.0' are \r\n, \n and \r. Default terminators for PARSER_VERSION = '2.0' are \r\n and \n.
Note
When you use PARSER_VERSION='1.0' and specify \n (newline) as the row terminator, it will be automatically prefixed with a \r (carriage return) character, which results in a row terminator of \r\n.
ESCAPE_CHAR = 'char'
Specifies the character in the file that is used to escape itself and all delimiter values in the file. If the escape character is followed by a value other than itself, or any of the delimiter values, the escape character is dropped when reading the value.
The ESCAPECHAR parameter will be applied regardless of whether the FIELDQUOTE is or isn't enabled. It won't be used to escape the quoting character. The quoting character must be escaped with another quoting character. Quoting character can appear within column value only if value is encapsulated with quoting characters.
FIRSTROW = 'first_row'
Specifies the number of the first row to load. The default is 1 and indicates the first row in the specified data file. The row numbers are determined by counting the row terminators. FIRSTROW is 1-based.
FIELDQUOTE = 'field_quote'
Specifies a character that will be used as the quote character in the CSV file. If not specified, the quote character (") will be used.
DATA_COMPRESSION = 'data_compression_method'
Specifies compression method. Supported in PARSER_VERSION='1.0' only. Following compression method is supported:
- GZIP
PARSER_VERSION = 'parser_version'
Specifies parser version to be used when reading files. Currently supported CSV parser versions are 1.0 and 2.0:
- PARSER_VERSION = '1.0'
- PARSER_VERSION = '2.0'
CSV parser version 1.0 is default and feature rich. Version 2.0 is built for performance and doesn't support all options and encodings.
CSV parser version 1.0 specifics:
- Following options aren't supported: HEADER_ROW.
- Default terminators are \r\n, \n and \r.
- If you specify \n (newline) as the row terminator, it will be automatically prefixed with a \r (carriage return) character, which results in a row terminator of \r\n.
CSV parser version 2.0 specifics:
- Not all data types are supported.
- Maximum character column length is 8000.
- Maximum row size limit is 8 MB.
- Following options aren't supported: DATA_COMPRESSION.
- Quoted empty string ("") is interpreted as empty string.
- DATEFORMAT SET option isn't honored.
- Supported format for DATE data type: YYYY-MM-DD
- Supported format for TIME data type: HH:MM:SS[.fractional seconds]
- Supported format for DATETIME2 data type: YYYY-MM-DD HH:MM:SS[.fractional seconds]
- Default terminators are \r\n and \n.
HEADER_ROW = { TRUE | FALSE }
Specifies whether a CSV file contains header row. Default is FALSE. Supported in PARSER_VERSION='2.0'. If TRUE, the column names will be read from the first row according to FIRSTROW argument. If TRUE and schema is specified using WITH, binding of column names will be done by column name, not ordinal positions.
DATAFILETYPE = { 'char' | 'widechar' }
Specifies encoding: char is used for UTF8, widechar is used for UTF16 files.
CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' }
Specifies the code page of the data in the data file. The default value is 65001 (UTF-8 encoding). See more details about this option here.
ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}'
This option will disable the file modification check during the query execution, and read the files that are updated while the query is running. This is useful option when you need to read append-only files that are appended while the query is running. In the appendable files, the existing content isn't updated, and only new rows are added. Therefore, the probability of wrong results is minimized compared to the updateable files. This option might enable you to read the frequently appended files without handling the errors. See more information in querying appendable CSV files section.
Reject Options
Note
Rejected rows feature is in Public Preview. Please note that rejected rows feature works for delimited text files and PARSER_VERSION 1.0.
You can specify reject parameters that determine how service will handle dirty records it retrieves from the external data source. A data record is considered 'dirty' if actual data types don't match the column definitions of the external table.
When you don't specify or change reject options, service uses default values. Service will use the reject options to determine the number of rows that can be rejected before the actual query fails. The query will return (partial) results until the reject threshold is exceeded. It then fails with the appropriate error message.
MAXERRORS = reject_value
Specifies the number of rows that can be rejected before the query fails. MAXERRORS must be an integer between 0 and 2,147,483,647.
ERRORFILE_DATA_SOURCE = data source
Specifies data source where rejected rows and the corresponding error file should be written.
ERRORFILE_LOCATION = Directory Location
Specifies the directory within the DATA_SOURCE, or ERROR_FILE_DATASOURCE if specified, that the rejected rows and the corresponding error file should be written. If the specified path doesn't exist, service will create one on your behalf. A child directory is created with the name "rejectedrows". The "" character ensures that the directory is escaped for other data processing unless explicitly named in the location parameter. Within this directory, there's a folder created based on the time of load submission in the format YearMonthDay_HourMinuteSecond_StatementID (Ex. 20180330-173205-559EE7D2-196D-400A-806D-3BF5D007F891). You can use statement id to correlate folder with query that generated it. In this folder, two files are written: error.json file and the data file.
error.json file contains json array with encountered errors related to rejected rows. Each element representing error contains following attributes:
| Attribute | Description |
|---|---|
| Error | Reason why row is rejected. |
| Row | Rejected row ordinal number in file. |
| Column | Rejected column ordinal number. |
| Value | Rejected column value. If the value is larger than 100 characters, only the first 100 characters will be displayed. |
| File | Path to file that row belongs to. |
Fast delimited text parsing
There are two delimited text parser versions you can use. CSV parser version 1.0 is default and feature rich while parser version 2.0 is built for performance. Performance improvement in parser 2.0 comes from advanced parsing techniques and multi-threading. Difference in speed will be bigger as the file size grows.
Automatic schema discovery
You can easily query both CSV and Parquet files without knowing or specifying schema by omitting WITH clause. Column names and data types will be inferred from files.
Parquet files contain column metadata, which will be read, type mappings can be found in type mappings for Parquet. Check reading Parquet files without specifying schema for samples.
For the CSV files, column names can be read from header row. You can specify whether header row exists using HEADER_ROW argument. If HEADER_ROW = FALSE, generic column names will be used: C1, C2, ... Cn where n is number of columns in file. Data types will be inferred from first 100 data rows. Check reading CSV files without specifying schema for samples.
Have in mind that if you're reading number of files at once, the schema will be inferred from the first file service gets from the storage. This can mean that some of the columns expected are omitted, all because the file used by the service to define the schema didn't contain these columns. In that case, use OPENROWSET WITH clause.
Important
There are cases when appropriate data type cannot be inferred due to lack of information and larger data type will be used instead. This brings performance overhead and is particularly important for character columns which will be inferred as varchar(8000). For optimal performance, check inferred data types and use appropriate data types.
Type mapping for Parquet
Parquet and Delta Lake files contain type descriptions for every column. The following table describes how Parquet types are mapped to SQL native types.
| Parquet type | Parquet logical type (annotation) | SQL data type |
|---|---|---|
| BOOLEAN | bit | |
| BINARY / BYTE_ARRAY | varbinary | |
| DOUBLE | float | |
| FLOAT | real | |
| INT32 | int | |
| INT64 | bigint | |
| INT96 | datetime2 | |
| FIXED_LEN_BYTE_ARRAY | binary | |
| BINARY | UTF8 | varchar *(UTF8 collation) |
| BINARY | STRING | varchar *(UTF8 collation) |
| BINARY | ENUM | varchar *(UTF8 collation) |
| FIXED_LEN_BYTE_ARRAY | UUID | uniqueidentifier |
| BINARY | DECIMAL | decimal |
| BINARY | JSON | varchar(8000) *(UTF8 collation) |
| BINARY | BSON | Not supported |
| FIXED_LEN_BYTE_ARRAY | DECIMAL | decimal |
| BYTE_ARRAY | INTERVAL | Not supported |
| INT32 | INT(8, true) | smallint |
| INT32 | INT(16, true) | smallint |
| INT32 | INT(32, true) | int |
| INT32 | INT(8, false) | tinyint |
| INT32 | INT(16, false) | int |
| INT32 | INT(32, false) | bigint |
| INT32 | DATE | date |
| INT32 | DECIMAL | decimal |
| INT32 | TIME (MILLIS) | time |
| INT64 | INT(64, true) | bigint |
| INT64 | INT(64, false) | decimal(20,0) |
| INT64 | DECIMAL | decimal |
| INT64 | TIME (MICROS) | time |
| INT64 | TIME (NANOS) | Not supported |
| INT64 | TIMESTAMP (normalized to utc) (MILLIS / MICROS) | datetime2 |
| INT64 | TIMESTAMP (not normalized to utc) (MILLIS / MICROS) | bigint - make sure that you explicitly adjust bigint value with the timezone offset before converting it to a datetime value. |
| INT64 | TIMESTAMP (NANOS) | Not supported |
| Complex type | LIST | varchar(8000), serialized into JSON |
| Complex type | MAP | varchar(8000), serialized into JSON |
Examples
Read CSV files without specifying schema
The following example reads CSV file that contains header row without specifying column names and data types:
SELECT
*
FROM OPENROWSET(
BULK 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0',
HEADER_ROW = TRUE) as [r]
The following example reads CSV file that doesn't contain header row without specifying column names and data types:
SELECT
*
FROM OPENROWSET(
BULK 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0') as [r]
Read Parquet files without specifying schema
The following example returns all columns of the first row from the census data set, in Parquet format, and without specifying column names and data types:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
) AS [r]
Read Delta Lake files without specifying schema
The following example returns all columns of the first row from the census data set, in Delta Lake format, and without specifying column names and data types:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='DELTA'
) AS [r]
Read specific columns from CSV file
The following example returns only two columns with ordinal numbers 1 and 4 from the population*.csv files. Since there's no header row in the files, it starts reading from the first line:
SELECT
*
FROM OPENROWSET(
BULK 'https://sqlondemandstorage.blob.core.windows.net/csv/population/population*.csv',
FORMAT = 'CSV',
FIRSTROW = 1
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2 1,
[population] bigint 4
) AS [r]
Read specific columns from Parquet file
The following example returns only two columns of the first row from the census data set, in Parquet format:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
)
WITH (
[stateName] VARCHAR (50),
[population] bigint
) AS [r]
Specify columns using JSON paths
The following example shows how you can use JSON path expressions in WITH clause and demonstrates difference between strict and lax path modes:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
)
WITH (
--lax path mode samples
[stateName] VARCHAR (50), -- this one works as column name casing is valid - it targets the same column as the next one
[stateName_explicit_path] VARCHAR (50) '$.stateName', -- this one works as column name casing is valid
[COUNTYNAME] VARCHAR (50), -- STATEname column will contain NULLs only because of wrong casing - it targets the same column as the next one
[countyName_explicit_path] VARCHAR (50) '$.COUNTYNAME', -- STATEname column will contain NULLS only because of wrong casing and default path mode being lax
--strict path mode samples
[population] bigint 'strict $.population' -- this one works as column name casing is valid
--,[population2] bigint 'strict $.POPULATION' -- this one fails because of wrong casing and strict path mode
)
AS [r]
Specify multiple files/folders in BULK path
The following example shows how you can use multiple file/folder paths in BULK parameter:
SELECT
TOP 10 *
FROM
OPENROWSET(
BULK (
'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=2000/*.parquet',
'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=2010/*.parquet'
),
FORMAT='PARQUET'
)
AS [r]
Next steps
For more samples, see the query data storage quickstart to learn how to use OPENROWSET to read CSV, PARQUET, DELTA LAKE, and JSON file formats. Check best practices for achieving optimal performance. You can also learn how to save the results of your query to Azure Storage using CETAS.