Migrating Time Series Insights Gen2 to Real-Time Intelligence in Microsoft Fabric
Note
The Time Series Insights service will be retired on 7 July 2024. Consider migrating existing environments to alternative solutions as soon as possible. For more information on the deprecation and migration, visit our documentation.
Overview
Eventhouse is the time series database in Real-Time Intelligence. It serves as the target for migrating data away from Time Series Insights.
High-level migration recommendations.
| Feature | Migration Recommended |
|---|---|
| Ingesting JSON from Hub with flattening and escaping | Get data from Azure Event Hubs |
| Open Cold store | Eventhouse OneLake Availability |
| Power BI Connector | Use Eventhouse Power BI Connector. Rewrite TSQ to KQL manually. |
| Spark Connector | Migrate data to Eventhouse. Use a notebook with Apache Spark to query an Eventhouse or Explore the data in your lakehouse with a notebook |
| Bulk Upload | Get data from Azure storage |
| Time Series Model | Can be exported as JSON file. Can be imported to Eventhouse. Kusto Graph Semantics allow model, traverse, and analyze Time Series Model hierarchy as a graph |
| Time Series Explorer | Real-Time Dashboard, Power BI report or write a custom dashboard using KustoTrender |
| Query language | Rewrite queries in KQL. |
Migrating Telemetry
To retrieve the copy of all data in the environment, use PT=Time folder in the storage account. For more information, please see Data Storage.
Migration Step 1 - Get Statistics about Telemetry Data
Data
- Env overview
- Record Environment ID from first part of Data Access FQDN (for example, d390b0b0-1445-4c0c-8365-68d6382c1c2a From .env.crystal-dev.windows-int.net)
- Env Overview -> Storage Configuration -> Storage Account
- Use Storage Explorer to get folder statistics
- Record size and the number of blobs of
PT=Timefolder.
- Record size and the number of blobs of
Migration Step 2 - Migrate Data To Eventhouse
Create an Eventhouse
To set up an Eventhouse for your migration process, follow the steps in creating an Eventhouse.
Data Ingestion
To retrieve data for the storage account corresponding to your Time Series Insights instance, follow the steps in getting data from Azure Storage.
Make sure that you:
Select the appropriate container and provide its URI, along with the necessary SAS token or account key.
Configure file filters folder path as
V=1/PT=Timeto filter the relevant blobs.Verify the inferred schema and remove any infrequently queried columns, while retaining at least the timestamp, TSID columns, and values. To ensure that all your data is copied to Eventhouse add another column and use the DropMappedFields mapping transformation.
Complete the ingestion process.
Querying the data
Now that you successfully ingested the data, you can begin exploring it using a KQL queryset. If you need to access the data from your custom client application, Eventhouse provides SDKs for major programming languages such as C# (link), Java (link), and Node.js (link).
Migrating Time Series Model to Azure Data Explorer
The model can be download in JSON format from TSI Environment using TSI Explorer UX or TSM Batch API. Then the model can be imported to Eventhouse.
Download TSM from TSI UX.
Delete first three lines using Visual Studio Code or another editor.
Using Visual Studio Code or another editor, search and replace as regex
\},\n \{with}{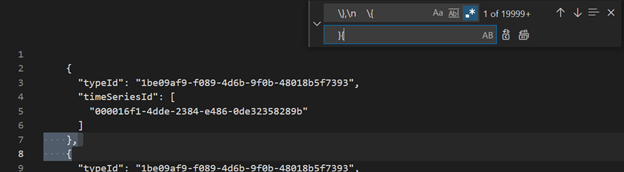
Ingest as JSON into ADX as a separate table using Get data from a single file.


Once you migrated your time series data to Eventhouse in Fabric Real-Time Intelligence, you can use the power of Kusto Graph Semantics to contextualize and analyze your data. Kusto Graph Semantics allows you to model, traverse, and analyze the hierarchy of your Time Series Model as a graph. By using Kusto Graph Semantics, you can gain insights into the relationships between different entities in your time series data, such as assets, sites, and data points. These insights help you to understand the dependencies and interactions between various components of your system.
Translate Time Series Queries (TSQ) to KQL
GetEvents
{
"getEvents": {
"timeSeriesId": [
"assest1",
"siteId1",
"dataId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:0.0000000Z",
"to": "2021-11-05T00:00:00.000000Z"
},
"inlineVariables": {},
}
}
events
| where timestamp >= datetime(2021-11-01T00:00:0.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.000000Z)
| where assetId_string == "assest1" and siteId_string == "siteId1" and dataid_string == "dataId1"
| take 10000
GetEvents with filter
{
"getEvents": {
"timeSeriesId": [
"deviceId1",
"siteId1",
"dataId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:0.0000000Z",
"to": "2021-11-05T00:00:00.000000Z"
},
"filter": {
"tsx": "$event.sensors.sensor.String = 'status' AND $event.sensors.unit.String = 'ONLINE"
}
}
}
events
| where timestamp >= datetime(2021-11-01T00:00:0.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.000000Z)
| where deviceId_string== "deviceId1" and siteId_string == "siteId1" and dataId_string == "dataId1"
| where ['sensors.sensor_string'] == "status" and ['sensors.unit_string'] == "ONLINE"
| take 10000
GetEvents with projected variable
{
"getEvents": {
"timeSeriesId": [
"deviceId1",
"siteId1",
"dataId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:0.0000000Z",
"to": "2021-11-05T00:00:00.000000Z"
},
"inlineVariables": {},
"projectedVariables": [],
"projectedProperties": [
{
"name": "sensors.value",
"type": "String"
},
{
"name": "sensors.value",
"type": "bool"
},
{
"name": "sensors.value",
"type": "Double"
}
]
}
}
events
| where timestamp >= datetime(2021-11-01T00:00:0.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.000000Z)
| where deviceId_string== "deviceId1" and siteId_string == "siteId1" and dataId_string == "dataId1"
| take 10000
| project timestamp, sensorStringValue= ['sensors.value_string'], sensorBoolValue= ['sensors.value_bool'], sensorDoublelValue= ['sensors.value_double']
AggregateSeries
{
"aggregateSeries": {
"timeSeriesId": [
"deviceId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:00.0000000Z",
"to": "2021-11-05T00:00:00.0000000Z"
},
"interval": "PT1M",
"inlineVariables": {
"sensor": {
"kind": "numeric",
"value": {
"tsx": "coalesce($event.sensors.value.Double, todouble($event.sensors.value.Long))"
},
"aggregation": {
"tsx": "avg($value)"
}
}
},
"projectedVariables": [
"sensor"
]
}
events
| where timestamp >= datetime(2021-11-01T00:00:00.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.0000000Z)
| where deviceId_string == "deviceId1"
| summarize avgSensorValue= avg(coalesce(['sensors.value_double'], todouble(['sensors.value_long']))) by bin(IntervalTs = timestamp, 1m)
| project IntervalTs, avgSensorValue
AggregateSeries with filter
{
"aggregateSeries": {
"timeSeriesId": [
"deviceId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:00.0000000Z",
"to": "2021-11-05T00:00:00.0000000Z"
},
"filter": {
"tsx": "$event.sensors.sensor.String = 'heater' AND $event.sensors.location.String = 'floor1room12'"
},
"interval": "PT1M",
"inlineVariables": {
"sensor": {
"kind": "numeric",
"value": {
"tsx": "coalesce($event.sensors.value.Double, todouble($event.sensors.value.Long))"
},
"aggregation": {
"tsx": "avg($value)"
}
}
},
"projectedVariables": [
"sensor"
]
}
}
events
| where timestamp >= datetime(2021-11-01T00:00:00.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.0000000Z)
| where deviceId_string == "deviceId1"
| where ['sensors.sensor_string'] == "heater" and ['sensors.location_string'] == "floor1room12"
| summarize avgSensorValue= avg(coalesce(['sensors.value_double'], todouble(['sensors.value_long']))) by bin(IntervalTs = timestamp, 1m)
| project IntervalTs, avgSensorValue
Power BI
There's no automated process for migrating Power BI reports that were based on Time Series Insights. All queries relying on data stored in Time Series Insights must be migrated to Eventhouse.
To create efficient time series reports in Power BI, we recommend referring to the following informative blog articles:
- Eventhouse time series capabilities in Power BI
- How to use M dynamic parameters without most limitations
- Timespan/duration values in KQL, Power Query, and Power BI
- KQL query settings in Power BI
- Filtering and visualizing Kusto data in local time
- Near real-time reports in PBI + Kusto
- Power BI modeling with ADX - cheat sheet
Refer to these resources for guidance on creating effective time series reports in Power BI.
Real-Time Dashboard
A Real-Time Dashboard in Fabric is a collection of tiles, optionally organized in pages, where each tile has an underlying query and a visual representation. You can natively export Kusto Query Language (KQL) queries to a dashboard as visuals and later modify their underlying queries and visual formatting as needed. In addition to ease of data exploration, this fully integrated dashboard experience provides improved query and visualization performance.
Start by creating a new dashboard in Fabric Real-Time Intelligence. This powerful feature allows you to explore data, customize visuals, apply conditional formatting, and utilize parameters. Furthermore, you can create alerts directly from your Real-Time Dashboards, enhancing your monitoring capabilities. For detailed instructions on how to create a dashboard, refer to the official documentation.