基本概念
指标顾问何时弃用?
从 2023 年 9 月 20 日开始,你将无法创建新的指标顾问资源。 指标顾问服务将于 2026 年 10 月 1 日停用。
什么是多维时序数据?
请参阅词汇表中的多维指标定义。
指标顾问启动异常情况检测需要多少数据?
至少需要一个数据点才能触发异常情况检测。 但这并不能实现最佳的准确性。 此服务将使用在创建数据馈送时指定为“填充间隙”规则的值来假定以前的数据点的时间窗口。
建议在要检测的时间戳之前包含一些数据。 根据数据的粒度,建议的数据量如下变化。
| 粒度 | 建议的检测数据量 |
|---|---|
| 少于 5 分钟 | 4 天的数据 |
| 5 分钟至 1 天 | 28 天的数据 |
| 1 天以上至 31 天 | 4 年的数据 |
| 大于 31 天 | 48 年的数据 |
指标处理哪些数据以及如何保留数据?
- 指标顾问处理从客户的数据源收集的时序数据,历史数据用于模型选择,并确定所需的数据边界。
- 客户的时序数据和推理结果将存储在服务中。 指标顾问不会在客户部署服务实例的区域之外存储或处理客户数据。
为什么指标顾问无法从历史数据中检测到异常?
指标顾问旨在检测实时传送视频流数据。 此服务将回顾并对其运行异常情况检测的历史数据的最大长度受到限制。 这意味着只有在某个最早时间戳之后的数据点才会具有异常情况检测结果。 最早的时间戳取决于数据的粒度。
根据数据的粒度,将具有异常情况检测结果的历史数据的长度如下所示。
| 粒度 | 用于异常情况检测的历史数据的最大长度 |
|---|---|
| 少于 5 分钟 | 加入时间 - 13 小时 |
| 5 分钟至不到 1 小时 | 加入时间 - 4 天 |
| 1 小时至不到 1 天 | 加入时间 - 14 天 |
| 1 天 | 加入时间 - 28 天 |
| 1 天以上,不到 31 天 | 加入时间 - 2 年 |
| 大于 31 天 | 加入时间 - 24 年 |
什么是指标顾问的数据保留和限制?
- 数据保留。 指标顾问最多保留 10000 个时间间隔什么是间隔?,从当前时间戳向前计数(无论是否有可用数据)。 超出此时间范围的数据将被删除。 数据保留映射的天数因指标粒度而异。
| 粒度(分钟) | 保留(天) |
|---|---|
| 1 | 6.94 |
| 5 | 34.72 |
| 15 | 104.1 |
| 60(1 小时) | 416.67 |
| 1440(1 天) | 10000.00 |
- 限制一个指标内的最大时序计数。
一个指标内可能有多个维度,每个维度可能有多个值。 一个指标的最大维度组合不应超过 100k。
- 当数据馈送详细信息页上达到 80% 限制时,会通知指标顾问资源管理员和数据馈送所有者。
- 如果指标已经超出限制,数据馈送将暂停,并等待客户采取后续操作。 建议使用筛选将数据馈送拆分为多个数据馈送。
- 一个指标顾问实例中存储的最大数据点的限制
指标顾问从第一个引入时间戳开始,对加入到实例的所有数据馈送的数据点总数进行计数。 将存储到一个指标顾问实例中的最大数据点数是 20 亿。
- 当数据馈送列表页和添加新的数据馈送页上达到 80% 的限制时,将通知指标顾问资源管理员和所有用户。
- 如果数据点总数超过限制,则所有数据馈送将被暂停,并且新的馈送加入也将被阻止。 建议删除未使用的数据馈送,或者在订阅中创建新的指标顾问资源。
为什么我无法登录到指标顾问? 错误消息显示“由于 90 天内处于非活动状态,资源已停用”
资源停用有两种情况:
- 已创建指标顾问资源,但在 90 天内未加入任何数据馈送。 资源因不活动会在 90 天后停用。
- 如果已创建一个或多个数据馈送,但没有任何新数据被引入到指标顾问,则服务将进入空闲模式,没有要处理的数据。 系统仍会尝试根据指标粒度定期从源中抓取数据。 但是,如果连续 90 天没有可用数据或没有要处理的单个时序,则该资源将被停用。 当资源停用时,与该资源关联的所有历史数据都将丢失。
如果想要重新开始使用,建议创建新资源并删除旧资源。
如何将峰值和低谷检测为异常?
如何将常规(周期性)模式的不一致检测为异常?
“智能检测”能够了解数据模式,包括周期性模式。 然后,它将那些不符合常规模式的数据点检测为异常。 有关详细信息,请参阅优化检测配置。
指标顾问是否支持 VNET 背后的数据源?
否,指标顾问目前不支持 VNET 背后的数据源。
如何将平线检测为异常?
如果数据通常极不稳定且波动很大,你希望在数据变得十分稳定甚至变成一条平线时收到警告,则可以将“更改阈值”配置为在更改极小时检测此类数据点。 有关详细信息,请参阅异常情况检测配置。
如何设置电子邮件设置并启用通过电子邮件发送警报的功能?
具有订阅管理员或资源组管理员权限的用户需要导航到在 Azure 门户中创建的指标顾问资源,并选择“访问控制(IAM)”选项卡。
选择“添加角色分配”
选取“认知服务指标顾问管理员”角色,然后选择帐户,如下图所示。
选择“保存”按钮,你将被添加为“指标顾问”资源的管理员。 上述所有操作都需要由订阅管理员或资源组管理员执行。
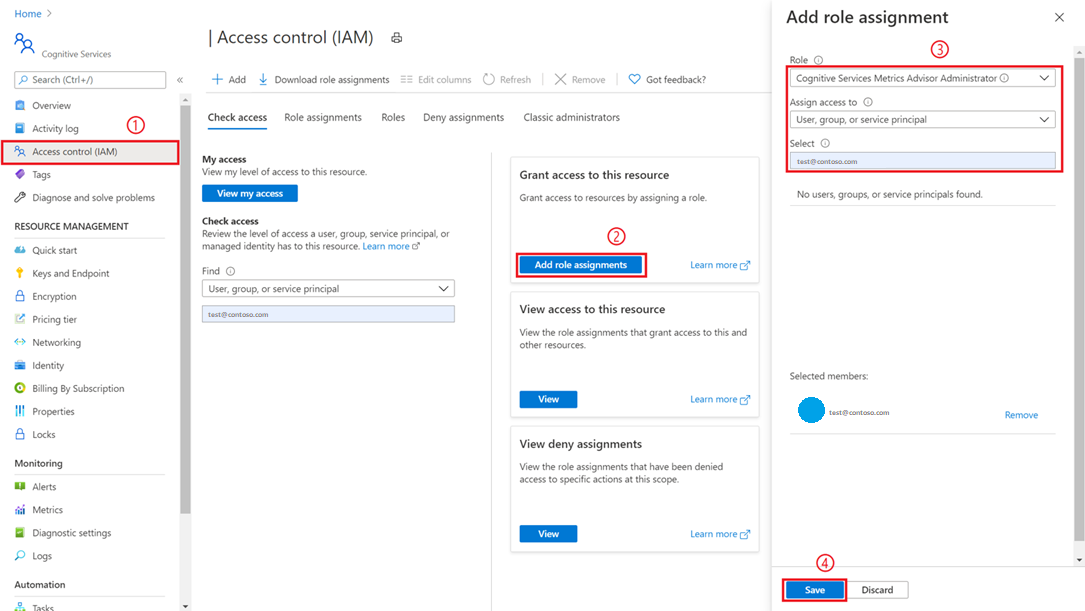
传播权限最多可能需要一分钟时间。 然后,选择指标顾问工作区,并选择“电子邮件设置”选项(在左侧导航面板中)。 填写必需项,尤其是与 SMTP 相关的信息。
选择“保存”,完成电子邮件配置。 你可以创建新的挂钩并订阅指标异常,以获得近乎实时的警报。

高级概念
指标顾问如何为多维指标构建诊断树?
指标可以按维度划分为多个时序。 例如,为团队拥有的所有服务监视指标 Response latency。 可使用 Service 类别丰富指标的维度,因此我们按 Service1 和 Service2 等划分 Response latency。 每个服务都可以部署在多个数据中心的不同计算机上,因此可以按 Machine 和 Data center 进一步划分指标。
| 服务 | 数据中心 | 计算机 |
|---|---|---|
| S1 | DC1 | M1 |
| S1 | DC1 | M2 |
| S1 | DC2 | M3 |
| S1 | DC2 | M4 |
| S2 | DC1 | M1 |
| S2 | DC1 | M2 |
| S2 | DC2 | M5 |
| S2 | DC2 | M6 |
| ... |
从 Response latency 总数开始,我们可以按 Service、Data center 和 Machine 向下钻取指标。 但是,对于服务所有者而言,使用路径 Service ->Data center ->Machine 可能更有意义;而对于基础结构工程师而言,使用路径 Data Center ->Machine ->Service 可能更有意义。 这完全取决于用户的个人业务需求。
在指标顾问中,用户可以指定其要从分层拓扑的一个节点向下钻取或汇总的任何路径。 更准确地说,分层拓扑是有向无环图而非树结构。 完整的分层拓扑由所有潜在的维度组合组成,如下所示:

从理论上讲,如果维度 Service 具有 Ls 个非重复值,维度 Data center 具有 Ldc 个非重复值,维度 Machine 具有 Lm 个非重复值,则分层拓扑中可能有 (Ls + 1) * (Ldc + 1) * (Lm + 1) 个维度组合。
但通常并非所有维度组合都是有效的,这可能会显着降低复杂性。 目前,如果用户自己聚合指标,则不限制维度的数量。 如果需要使用指标顾问提供的汇总功能,则维度的数量不应超过 6。 但是,我们将按指标维度扩展的时序数量限制为小于 10,000。
诊断页上的“诊断树”工具仅显示在其中检测到异常的节点,而不是整个拓扑。 这是为了帮助你专注于当前问题。 它也可能会不显示指标内的所有异常,而是会基于贡献显示最常见的异常。 这样,我们可以快速找出异常数据的影响、范围和传播路径。 这大大减少了需要重点关注的异常数量,并帮助用户了解并找到其关键问题。
例如,当 Service = S2 | Data Center = DC2 | Machine = M5 上发生异常时,异常的偏差会影响也已检测到异常的父节点 Service= S2,但异常不会影响 DC2 上的整个数据中心以及 M5 上的所有服务。 将按照以下屏幕截图中的方式构建事件树,最常见的异常是在 Service = S2 上捕获的,根本原因可以按两条通向 Service = S2 | Data Center = DC2 | Machine = M5 的路径进行分析。
