Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Important
截至2026年5月18日,Azure AI 指标顾问已退休。
建议使用以下替代方法:
- Azure Monitor,作为官方Azure 3P 产品,通过多个接口提供异常检测和分析功能。
- 开源异常检测器,此开源项目提供与 Kensho、Azure 指标顾问和 Azure 异常检测器在后端中相同的异常检测功能。
请参阅本文,了解如何将数据载入指标顾问。
数据架构要求和配置
Azure AI 指标顾问是用于时序异常情况检测、诊断和分析的服务。 作为由 AI 提供支持的服务,它使用你的数据来训练所使用的模型。 服务接受具有以下各列的聚合数据表:
- 度量值(必需):度量值是一个基本术语或单位特定的术语,是指标的可量化值。 它指一个或多个包含数值的列。
-
时间戳(可选):可以有零列或一列,其类型为
DateTime或String。 如果未设置此列,则时间戳将设置为每个引入周期的开始时间。 设置时间戳的格式,如下所示:yyyy-MM-ddTHH:mm:ssZ。 - 维度(可选):维度是一个或多个分类值。 这些值的组合标识特定的单变量时序(例如国家/地区、语言、租户等)。 维度列可以是任意数据类型。 处理大量的列和值时要格外小心,应避免处理过多的维度。
如果使用数据源(如Azure Data Lake Storage或Azure Blob 存储),则可以聚合数据,使其与预期的指标架构保持一致。 这是因为这些数据源使用文件作为指标输入。
如果使用数据源(如Azure SQL或Azure 数据资源管理器),则可以使用聚合函数将数据聚合到预期的架构中。 这是因为这些数据源支持通过运行查询来从源获取指标数据。
如果不确定某些术语,请参阅术语表。
避免加载部分数据
数据不完整是由于存储在指标顾问中的数据与数据源中的数据不一致造成的。 在指标顾问完成数据拉取后,当数据源更新时,可能会发生这种情况。 指标顾问只从给定数据源拉取一次数据。
例如,如果某个指标已被载入到Metrics Advisor用于监视。 指标顾问成功获取时间戳 A 处的指标数据,并对其执行异常情况检测。 然而,如果在数据引入后,该特定时间戳A的指标数据已经被更新, 不会检索新的数据值。
你可以尝试回填历史数据(稍后介绍)以减少不一致情况,但如果已触发这些时间点的警报,则不会触发新的异常警报。 此过程可能会向系统添加更多工作负荷,并且不是自动的。
为了避免加载部分数据,建议采用两种方法:
在单个事务中生成数据:
确保在同一时间戳,所有维度组合的指标值都在单个事务中存储到数据源。 在上面的示例中,请等待所有数据源中的数据准备就绪,然后在单个事务中将其加载到指标顾问中。 指标顾问可以定期轮询数据馈送,直至成功检索到数据(或检索到部分数据)。
通过为“引入时间偏移”参数设置适当的值来延迟数据引入:
为数据馈送设置“引入时间偏移”参数以延迟引入,直到数据完全准备就绪。 这对于不支持事务(如Azure 表存储)的某些数据源非常有用。 有关详细信息,请参阅高级设置。
从添加数据馈送开始
登录到指标顾问门户并选择你的工作区后,请单击“开始”。 然后,在工作区的主页上,点击左侧菜单中的“添加数据源”。
添加连接设置
1. 基本设置
接下来,你将输入一组用于连接时序数据源的参数。
- 源类型:用于存储时序数据的数据源的类型。
-
粒度:时序数据中连续数据点之间的间隔。 指标顾问目前支持:“每年”、“每月”、“每周”、“每日”、“每小时”、“每分钟”和“自定义”。 自定义选项支持的最小间隔为 60 秒。
- 秒:当granularityName设置为Customize时的秒数。
-
数据引入自 (UTC) :数据引入的基线开始时间。
startOffsetInSeconds通常用于添加偏移量以帮助实现数据一致性。
2. 指定连接字符串 (连接字符串)
接下来,你需要指定数据源的连接信息。 有关其他字段和连接不同类型的数据源的详细信息,请参阅操作说明:连接不同的数据源。
3. 指定单个时间戳的查询
有关不同类型的数据源的详细信息,请参阅操作说明:连接不同的数据源。
加载数据
输入连接字符串和查询字符串后,选择加载数据。 在此操作中,指标顾问将检查连接和加载数据的权限,检查需要在查询中使用的必要参数(@IntervalStart 和 @IntervalEnd)),并检查来自数据源的列名。
如果此步骤中出现错误:
- 首先检查连接字符串是否有效。
- 接着检查是否有足够的权限,并确保数据引入工作节点的 IP 地址被授予访问权限。
- 然后检查您的查询中是否使用了必需的参数(@IntervalStart 和 @IntervalEnd))。
架构配置
加载数据架构后,选择适当的字段。
如果省略了某个时间点的时间戳,则指标顾问会改用引入数据点时的时间戳。 对于每个数据馈送,最多可将一列指定为时间戳。 如果你收到一条消息,指出不能将某个列指定为时间戳,请检查你的查询或数据源,并检查查询结果中是否有多个时间戳,而不仅仅是检查预览数据。 执行数据引入操作时,指标顾问每次只能使用给定源中的一个时序数据区块(例如一天、一小时 - 具体取决于粒度)。
| 选择 | 说明 | 备注 |
|---|---|---|
| 显示名称 | 取代原始列名称显示在工作区中的名称。 | Optional. |
| Timestamp | 数据点的时间戳。 如果省略,则指标顾问将在数据点引入时使用时间戳。 对于每个数据馈送,最多可将一列指定为时间戳。 | Optional. 最多只能指定一列。 如果收到“无法将列指定为时间戳”错误,请检查查询或数据源中是否存在重复的时间戳。 |
| 度量 | 数据馈送中的数值。 对于每个数据馈送,可以指定多个度量值,但至少应选择一列作为度量值。 | 应至少指定一列。 |
| 维度 | 分类值。 不同值的组合标识特定的一维时序,例如:国家/地区、语言、租户。 你可以选择零个或零个以上的列作为维度。 注意:选择非字符串列作为维度时要格外小心。 | Optional. |
| 忽略 | 忽略所选列。 | Optional. 对于支持使用查询获取数据的数据源,没有“忽略”选项。 |
如果希望忽略列,建议更新查询或数据源以排除这些列。 还可以通过以下方式来忽略列:使用“忽略列”,然后对特定列使用“忽略” 。 如果某列应当设置为维度,却被错误地设置为已忽略,Metrics Advisor可能最终只导入部分数据。 例如,假设来自查询的数据如下所示:
| 行 ID | Timestamp | 国家/地区 | 语言 | 收入 |
|---|---|---|---|---|
| 1 | 2019/11/10 | China | ZH-CN | 10000 |
| 2 | 2019/11/10 | China | EN-US | 1000 |
| 3 | 2019/11/10 | 美国 | ZH-CN | 12000 |
| 4 | 2019/11/11 | 美国 | EN-US | 23000 |
| ... | ... | ... | ... | ... |
如果“国家/地区”是一个维度并且“语言”设置为“忽略”,则第一行和第二行的时间戳将具有相同的维度 。 指标顾问将任意使用两行中的一个值。 在这种情况下,Metrics Advisor 不会聚合这些行。
配置架构后,选择“验证架构”。 在此操作中,指标顾问将执行以下检查:
- 查询数据的时间戳是否处于单个间隔。
- 在一个指标间隔内是否有相同维度组合返回的重复值。
自动汇总设置
Important
如果想要启用根本原因分析和其他诊断功能,则需要配置“自动汇总设置”。 启用后,自动汇总设置将无法更改。
指标顾问可以在引入过程中自动对每个维度执行聚合(例如 SUM、MAX、MIN),然后生成一个用于根本原因分析和其他诊断功能的层次结构。
请考虑下列情形:
“我不需要将汇总分析包含在我的数据中。”
你不需要使用 Metrics Advisor 汇总功能。
“我的数据已汇总,并且维度值由以下内容表示:NULL 或空(默认值)、仅 NULL、其他。”
此选项意味着 Metrics Advisor 无需汇总数据,因为行已经求和。 例如,如果选择“仅 NULL”,则会将以下示例中的第二个数据行视为所有国家/地区和语言 EN-US 的聚合;但是,“国家/地区”为空值的第四个数据行会被视为一个普通行,这可能表示数据不完整。
国家/地区 语言 收入 China ZH-CN 10000 (空值) EN-US 999999 美国 EN-US 12000 EN-US 5000 “我需要指标顾问通过计算 Sum/Max/Min/Avg/Count 来汇总数据,并用 {some string} 表示。”
某些数据源(如Azure Cosmos DB或Azure Blob 存储)不支持某些计算,例如group by 或 cube。 Metrics Advisor 提供了汇总选项,可以在数据导入过程中自动生成多维数据集。 此选项意味着你需要指标顾问使用你选择的算法来计算汇总,并使用指定的字符串在指标顾问中表示汇总。 这不会更改数据源中的任何数据。 例如,假设你有一组表示销售指标的时间序列,其维度为(国家/地区、区域)。 对于给定的时间戳,它可能如下所示:
国家 Region Sales Canada 艾伯塔省 100 Canada 不列颠哥伦比亚省 500 美国 蒙大拿州 100 启用“自动汇总”和求和后,Metrics Advisor将在数据引入过程中计算维度组合,并对指标进行求和。 结果可能是:
国家 Region Sales Canada 艾伯塔省 100 Null 艾伯塔省 100 Canada 不列颠哥伦比亚省 500 Null 不列颠哥伦比亚省 500 美国 蒙大拿州 100 Null 蒙大拿州 100 Null Null 700 Canada Null 600 美国 Null 100 (Country=Canada, Region=NULL, Sales=600)表示在加拿大(所有区域)的销售量总和为 600。下面是以 SQL 语言进行的转换。
SELECT dimension_1, dimension_2, ... dimension_n, sum (metrics_1) AS metrics_1, sum (metrics_2) AS metrics_2, ... sum (metrics_n) AS metrics_n FROM each_timestamp_data GROUP BY CUBE (dimension_1, dimension_2, ..., dimension_n);使用自动汇总功能之前,请考虑以下事项:
- 如果要使用“SUM”来聚合数据,请确保你的指标在每个维度中都是可相加的。 下面是“不可相加”指标的一些示例:
- 基于小数的指标。 这包括比率、百分比等。例如,你不应添加每个州的失业率来计算整个国家/地区的失业率。
- 维度中的重叠。 例如,你不应该将每项运动中的人数相加来计算喜欢运动的人数,因为其中有重叠,一个人可以喜欢多项运动。
- 为了确保整个系统的正常运行,限制了数据立方的大小。 目前的限制为 100000。 如果你的数据超过该限制,则对应于该时间戳的引入会失败。
- 如果要使用“SUM”来聚合数据,请确保你的指标在每个维度中都是可相加的。 下面是“不可相加”指标的一些示例:
高级设置
可以通过多个高级设置以自定义方式(例如指定引入偏移或并发)启用数据引入。 有关详细信息,请参阅数据馈送管理文章中的高级设置部分。
为数据流指定名称并检查摄取进度
为你的数据流自定义一个名称,该名称将会显示在你的工作区。 然后选择“提交”。 在数据馈送详细信息页中,可以使用引入进度栏查看状态信息。

若要检查引入失败的详细信息,请执行以下操作:
- 选择“显示详细信息”。
- 选择“状态”,然后选择“失败”或“错误”。
- 将鼠标悬停在导入失败上,查看出现的详细信息消息。
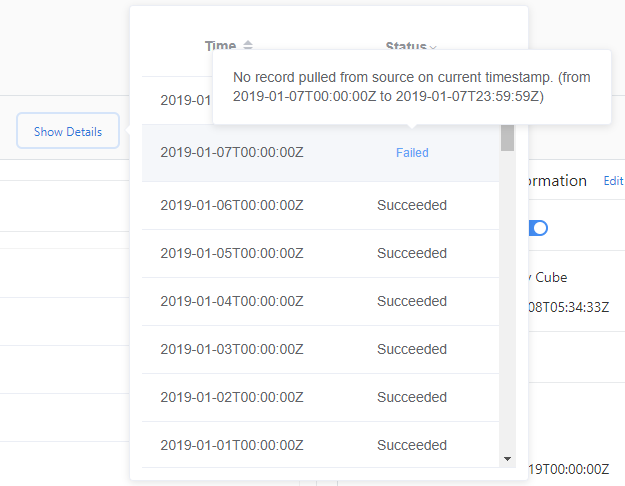
“失败”状态指示稍后将为此数据源重试数据摄入。 “错误”状态指示指标顾问不会针对此数据源进行重试。 若要重新加载数据,需要手动触发回填/重载。
还可以通过单击“刷新进度”来重新加载导入过程的进度。 在数据引入完成后,你可以随时单击指标,查看异常情况检测结果。