Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
借助自定义语音识别可以评估并改善应用程序与产品的语音识别准确度。 自定义语音模型可用于实时语音转文本、语音翻译和批量听录。
现成的语音识别可利用通用语言模型作为一个基本模型(使用 Azure 自有数据进行训练),并反映常用的口语。 此基础模型使用了代表各常见地域的方言和发音进行了预先训练。 发出语音识别请求时,默认使用每个支持的语言的最新基础模型。 基础模型在大多数语音识别场景中都效果良好。
通过提供文本数据来训练模型,自定义模型可用于扩充基本模型,以提高对特定于应用程序的特定领域词汇的识别。 它还可以通过为音频数据提供参考转录来改善应用的特定音频条件下的识别。
你可以在数据遵循某种模式时使用结构化文本来训练模型,指定自定义发音,并使用自定义反向文本规范化、自定义重写和自定义脏话过滤来定制显示文本格式。
它是如何工作的?
使用自定义语音识别,你可以上传自己的数据、测试和训练自定义模型、比较模型之间的准确度,以及将模型部署到自定义终结点。
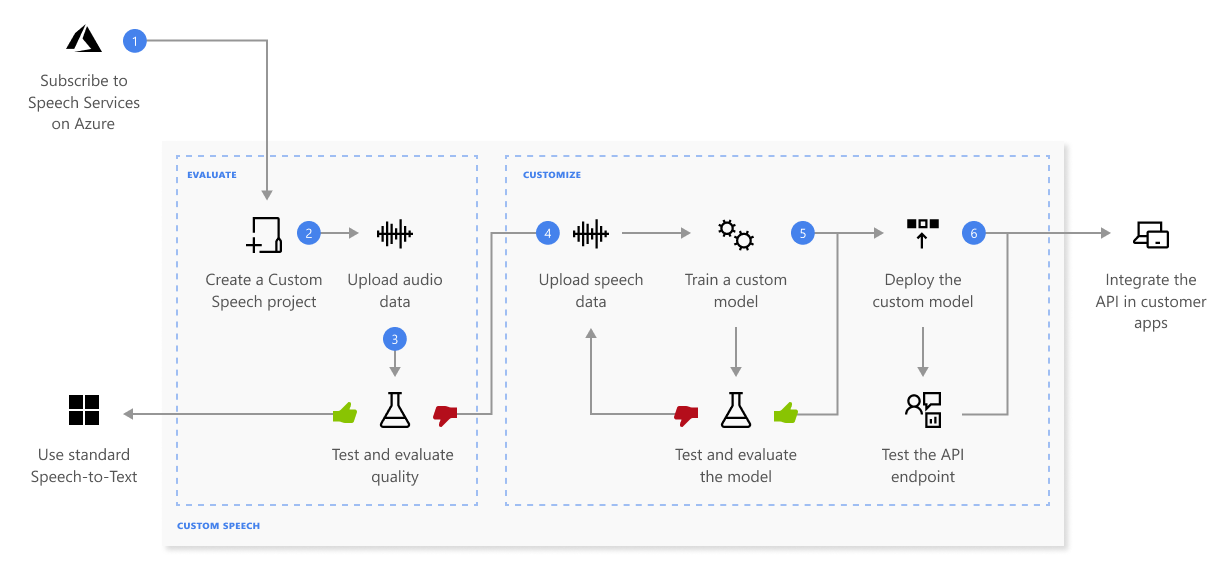
下面详细介绍了上述关系图显示的步骤序列:
创建项目并选择模型。 如果使用音频数据训练自定义模型,请在具有专用硬件的区域中选择服务资源来训练音频数据。 有关详细信息,请参阅区域表中的脚注。
上传测试数据。 上传测试数据,以便针对你的应用程序、工具和产品评估语音转文本产品/服务。
训练模型。 提供书面脚本和相关文本以及相应的音频数据。 可以选择在训练之前和之后测试模型,但建议这样做。
注意
你将为自定义语音识别模型使用和终结点托管付费。 如果基础模型是在 2023 年 10 月 1 日和更高版本创建的,则还需支付自定义语音模型训练费用。 如果基础模型是在 2023 年 10 月之前创建的,则无需支付训练费用。 有关详细信息,请参阅语音到文本 3.2 迁移指南中的Azure 语音定价和适应费用部分。
测试识别质量。 使用 Speech Studio 播放上传的音频,检查测试数据的语音识别质量。
量化测试模型。 评估和提高语音转文本模型的准确度。 语音服务会提供定量的字词错误率 (WER),该指标可以用来确定是否需要更多的训练。
部署模型。 对测试结果感到满意后,将模型部署到自定义终结点。 除了批量听录之外,还必须部署自定义终结点才能使用自定义语音模型。
选择模型
可通过多种方法使用自定义语音识别模型:
- 基础模型现成地为一系列方案提供准确的语音识别。 基础模型会定期更新以提高准确度和质量。 如果你使用基础模型,我们建议使用最新的默认基础模型。 如果所需的自定义功能仅适用于较旧的模型,则你可以选择较旧的基础模型。
- 自定义模型增强了基础模型,包含在所有自定义域区域中共享的领域专用词汇。
- 当自定义域具有多个区域,而每个区域使用特定的词汇时,可以使用多个自定义模型。
查看基础模型是否足够的一种推荐方法是分析从基础模型生成的听录,并将其与人工针对相同音频生成的脚本进行比较。 可以比较文本并获取字词错误率 (WER)评分。 如果 WER 评分较高,建议训练一个自定义模型来识别认错的字词。
如果词汇在不同的域区域之间存在差异,则建议使用多个模型。 例如,奥运会评论员报道各项赛事,每项赛事与其自身的专业用语关联。 由于每项奥运赛事词汇与其他词汇明显不同,生成特定于某项赛事的自定义模型可以通过限制与该特定赛事相关的语句数据来提高准确度。 因此,该模型无需筛选不相关的数据即可进行匹配。 但无论如何,训练仍然需要得当且多样化的训练数据。 包含口音、性别、年龄等特征不同的多位评论员的音频。
模型稳定性和生命周期
使用自定义语音识别部署到终结点的基础模型或自定义模型在你决定进行更新之前是固定的。 即使发布了新的基础模型,语音识别的准确度和质量也将保持一致。 这样,便可以在使用更新的模型之前锁定特定模型的行为。
无论你是训练自己的模型还是使用基础模型的快照,都可以将该模型使用有限的一段时间。 有关详细信息,请参阅模型和终结点生命周期。