适用于: Azure SQL 数据库
Azure SQL 数据库
“超大规模”服务层级提供了一个高度可缩放的存储和计算性能层,它利用 Azure 体系结构来横向扩展 Azure SQL 数据库的存储和计算资源,远远超出了“常规用途”和“业务关键”服务层级的可用限制。
本文链接到执行超大规模数据库的基本管理任务的重要指南,包括将现有数据库转换为“超大规模”数据库、将超大规模数据库还原到其他区域、从“超大规模”反向迁移到另一个服务层级,以及监视针对超大规模数据库正在进行的和最近作的状态。
了解如何在快速入门:在 Azure SQL 数据库中创建超大规模数据库中创建新的超大规模数据库。
监视超大规模数据库的操作
你可以使用 Azure 门户、Azure CLI、PowerShell 或 Transact-SQL 监视正在对 Azure SQL 数据库进行的操作或最近已完成的操作的状态。
选择你的首选方法的选项卡来监视操作。
当迁移、反向迁移或还原等操作正在进行时,Azure 门户会显示 Azure SQL 数据库中数据库的通知。

- 在 Azure 门户中导航到数据库。
- 在左侧导航栏中,选择“概述”。
- 查看右窗格底部的“通知”部分。 如果操作正在进行,将显示一个通知框。
- 选中通知框可以查看详细信息。
- 此时将打开正在进行的操作窗格。 可以查看正在进行的操作的详细信息。
此代码示例调用 az sql db op list,返回 Azure SQL 数据库中数据库的最近操作或正在进行的操作。
在运行以下代码示例之前,将 resourceGroupName、serverName、databaseName 和 serviceObjective 替换为相应的值:
resourceGroupName="myResourceGroup"
serverName="server01"
databaseName="mySampleDatabase"
az sql db op list -g $resourceGroupName -s $serverName --database $databaseName
Get-AzSqlDatabaseActivity cmdlet 返回 Azure SQL 数据库中数据库的最近操作或正在进行的操作。
在运行示例代码之前,将 $resourceGroupName、$serverName 和 $databaseName 参数设置为适当的值:
$resourceGroupName = "myResourceGroup"
$serverName = "server01"
$databaseName = "mySampleDatabase"
Get-AzSqlDatabaseActivity -ResourceGroupName $resourceGroupName -ServerName $serverName -DatabaseName $databaseName
若要监视超大规模数据库的操作,首先使用master或您选择的客户端连接到逻辑服务器上的,以运行 Transact-SQL 命令。
查询 sys.dm_operation_status 动态管理视图,以查看有关对 [逻辑服务器](logical-servers.md] 上的数据库执行的最近操作的信息。
此代码示例返回指定数据库的 sys.dm_operation_status 中的所有条目,按最近开始的操作排序。 在运行代码示例之前,将数据库名称替换为相应的值。
SELECT *
FROM sys.dm_operation_status
WHERE major_resource_id = 'mySampleDatabase'
ORDER BY start_time DESC;
GO
查看“超大规模”服务层级中的数据库
将数据库迁移到“超大规模”或重新配置“超大规模”服务层级中的数据库后,可能需要查看和/或记录超大规模数据库的配置。
Azure 门户显示了逻辑服务器上所有数据库的列表。
定价层列包括每个数据库的服务层级。
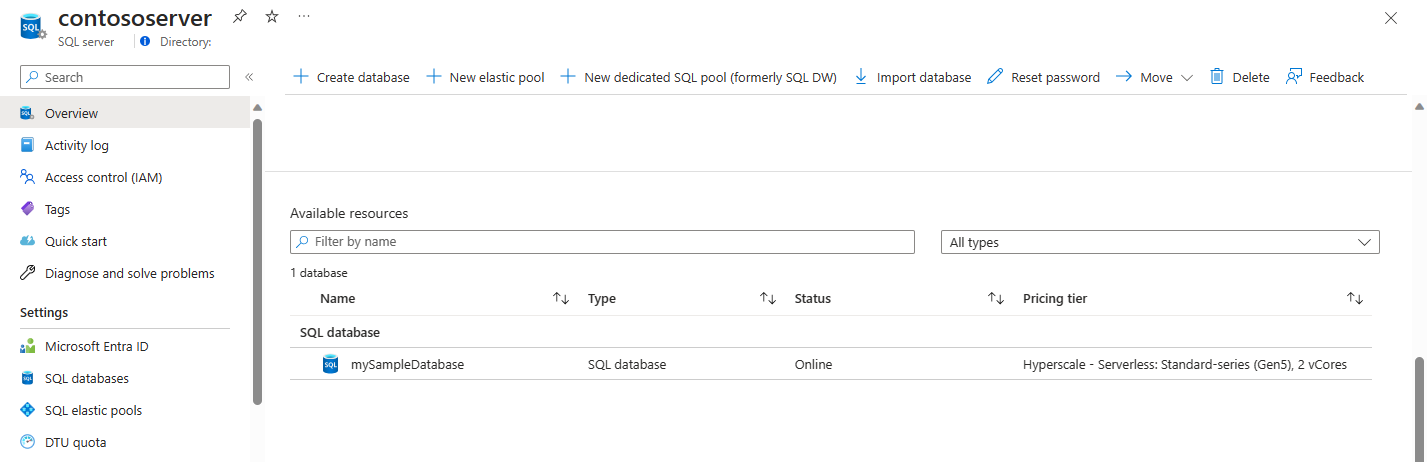
- 在 Azure 门户中导航到逻辑服务器。
- 在左侧导航栏中,选择“概述”。
- 滚动到窗格底部的资源列表。 该窗口将显示逻辑服务器上的 SQL 弹性池和数据库。
- 查看“定价层”列以标识“超大规模”服务层级中的数据库。
此 Azure CLI 代码示例调用 az sql db list,列出逻辑服务器上的超大规模数据库,其中包含名称、位置、服务级别目标、最大大小和高可用性副本数。
在运行以下代码示例之前,将 resourceGroupName 和 serverName 替换为相应的值:
resourceGroupName="myResourceGroup"
serverName="server01"
az sql db list -g $resourceGroupName -s $serverName --query "[].{Name:name, Location:location, SLO:currentServiceObjectiveName, Tier:currentSku.tier, maxSizeBytes:maxSizeBytes,HAreplicas:highAvailabilityReplicaCount}[?Tier=='Hyperscale']" --output table
Azure PowerShell Get-AzSqlDatabase cmdlet 返回逻辑服务器上的超大规模数据库列表,其中包含名称、位置、服务级别目标、最大大小和高可用性副本数。
在运行示例代码之前,将 $resourceGroupName 和 $serverName 参数设置为适当的值:
$resourceGroupName = "myResourceGroup"
$serverName = "server01"
Get-AzSqlDatabase -ResourceGroupName $resourceGroupName -ServerName $serverName | `
Where-Object { $_.Edition -eq 'Hyperscale' } | `
Select-Object DatabaseName, Location, currentServiceObjectiveName, Edition, `
MaxSizeBytes, HighAvailabilityReplicaCount | `
Format-Table
查看“版本”列以标识“超大规模”服务层级中的数据库。
若要使用 Transact-SQL 查看逻辑服务器上的所有超大规模数据库的服务层,请先使用 master 连接到数据库。
查询 sys.database_service_objectives 系统目录视图,以查看“超大规模”服务层级中的数据库:
SELECT d.name, dso.edition, dso.service_objective
FROM sys.database_service_objectives AS dso
JOIN sys.databases as d on dso.database_id = d.database_id
WHERE dso.edition = 'Hyperscale';
GO
将数据库转换为Hyperscale
可以使用 Azure 门户、Azure CLI、PowerShell 或 Transact-SQL 将 Azure SQL 数据库中的现有数据库转换为“超大规模”。
转换过程分为两个阶段-数据转换,在现有数据库处于联机状态时发生,然后直接切换到新的“超大规模”数据库。 你可以选择何时进行切换 - 数据库准备就绪后立即切换,或者在您选择的时间手动切换。
有关详细信息和步骤,请参阅 将现有数据库转换为超大规模。
从超大规模反向迁移
反向迁移到“常规用途”服务层级允许最近将 Azure SQL 数据库中的现有数据库转换为“超大规模”的客户在紧急情况下移回,如果“超大规模”无法满足其需求。 虽然反向迁移是由服务层级更改发起的,但它本质上是不同体系结构之间的数据规模的移动。
有关详细信息和步骤,请参阅 从超大规模反向迁移数据库。
相关内容

