Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
重要
你是否正在寻找一种数据库解决方案,以应对需要高扩展性、99.999% 可用性服务级别协议(SLA)、即时自动扩展和跨多个区域的自动故障转移的场景? 请考虑 Azure Cosmos DB for NoSQL。
本文提供有关使用图形数据模型的建议。 这些最佳做法对于确保随着数据的发展,图形数据库系统的可伸缩性和性能至关重要。 高效的数据模型对于大型图形尤其重要。
要求
本指南中概述的过程基于以下假设:
- 标识问题空间中的 实体 。 这些实体旨在在每个请求 中以原子方式 使用。 换句话说,数据库系统不设计为在多个查询请求中检索单个实体的数据。
- 了解数据库系统的 读取和写入要求 。 这些要求指导图形数据模型所需的优化。
- 可以很好地了解 Apache 中属性图标准 的原则。
何时需要图形数据库?
如果数据域中的实体和关系具有以下任何特征,则可以充分利用图形数据库解决方案:
- 这些实体通过描述性关系 高度连接 。 此方案中的好处是关系保留在存储中。
- 存在 循环关系 或 自引用实体。 使用关系数据库或文档数据库时,此模式通常是一个难题。
- 实体之间存在 动态演变的关系 。 此模式特别适用于具有多个级别的分层或树状数据。
- 实体之间存在 多对多关系 。
- 实体 和关系都有写入和读取要求。
如果满足上述条件,图形数据库方法可能会为查询复杂性、数据模型可伸缩性和查询性能提供优势。
下一步是确定图形是否用于分析或事务目的。 如果图形用于大量计算和数据处理工作负载,则值得探索 Cosmos DB Spark 连接器 和 GraphX 库。
如何使用图形对象
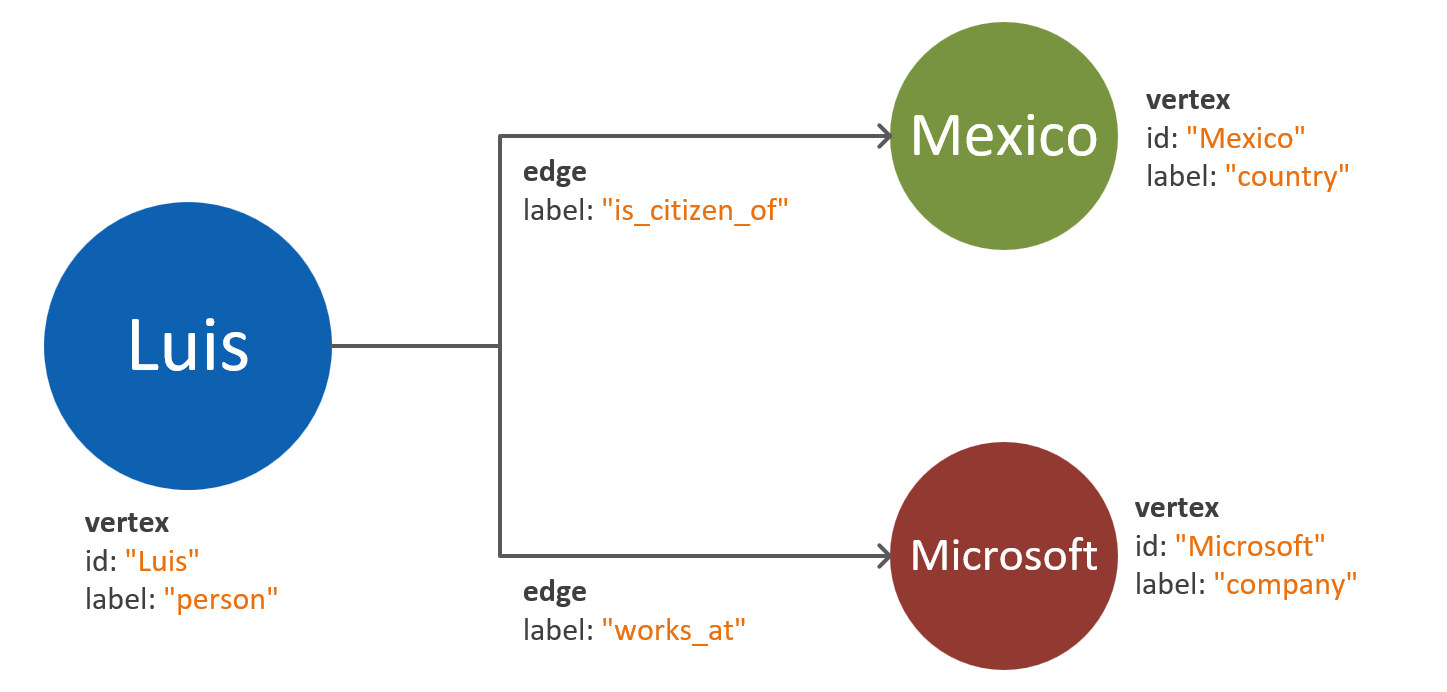
Apache 中的属性图标准定义了两种类型的对象:顶点和边缘。
下面是图形对象中属性的最佳做法:
| Object | 资产 | 类型 | 注释 |
|---|---|---|---|
| 顶点 | ID | String | 每个分区唯一强制实施。 如果在插入时未提供值,则会存储自动生成的 GUID。 |
| 顶点 | 标签 | String | 此属性用于定义顶点所表示的实体的类型。 如果未提供值,则使用默认值 顶点 。 |
| 顶点 | 属性 | 字符串、布尔值、数值 | 每个顶点中存储为键值对的单独属性的列表。 |
| 顶点 | 分区键 | 字符串、布尔值、数值 | 此属性定义顶点及其传出边缘的存储位置。 详细了解 图形分区。 |
| 边缘 | ID | String | 每个分区唯一强制实施。 默认情况下自动生成。 通常不需要使用 ID 唯一检索边缘。 |
| 边缘 | 标签 | String | 此属性用于定义两个顶点具有的关系类型。 |
| 边缘 | 属性 | 字符串、布尔值、数值 | 每个边缘中存储为键值对的单独属性的列表。 |
注释
边缘不需要分区键值,因为该值会根据其源顶点自动分配。 在 Azure Cosmos DB 中使用分区图了解详细信息。
实体和关系建模指南
以下指南可帮助你对 Azure Cosmos DB for Apache Gremlin 图形数据库进行数据建模。 这些准则假定数据域存在现有定义并查询数据域。
注释
以下步骤显示为建议。 在将最终模型视为生产就绪之前,应对其进行评估和测试。 此外,建议特定于 Azure Cosmos DB 的 Gremlin API 实现。
对顶点和属性进行建模
图形数据模型的第一步是将每个标识的实体映射到 顶点对象。 所有实体到顶点的一对一映射应该是初始步骤,可能会更改。
一个常见的陷阱是将单个实体的属性映射为单独的顶点。 请考虑以下示例,其中同一实体以两种不同的方式表示:
基于顶点的属性:在此方法中,实体使用三个单独的顶点和两个边缘来描述其属性。 虽然此方法可能会降低冗余,但它会增加模型复杂性。 模型复杂性增加可能会导致增加延迟、查询复杂性和计算成本。 此模型还可以在分区方面带来挑战。
属性嵌入顶点:此方法利用键值对列表来表示顶点内实体的所有属性。 此方法可降低模型复杂性,这会导致更简单的查询和更具成本效益的遍历。

注释
上图显示了一个简化的图形模型,该模型仅比较了划分实体属性的两种方式。
属性嵌入顶点模式通常提供更高性能且可缩放的方法。 新图形数据模型的默认方法应引向此模式。
但是,在某些情况下,引用属性可能会带来优势。 例如,如果引用的属性经常更新。 使用单独的顶点来表示不断变化的属性,以最大程度地减少更新所需的写入作量。
边缘方向的关系模型
对顶点进行建模后,可以添加边缘来表示它们之间的关系。 需要评估的第一个方面是 关系的方向。
使用或out()函数时outE(),边缘具有默认方向,后跟遍历。 这种自然方向会导致高效作,因为所有顶点都存储有其传出边缘。
通过使用 in() 函数,在边缘的相反方向遍历始终会导致跨分区查询。 详细了解 图形分区。 如果需要频繁遍历 in() 函数,请在两个方向添加边缘。
可以通过在 Gremlin 步骤中使用 .to() 谓词或 .from() 谓词 .addE() 来确定边缘方向。 或者,使用 Gremlin API 的批量执行程序库。
注释
默认情况下,边缘有方向。
关系标签
使用描述性关系标签可以提高边缘解析作的效率。 可通过以下方式应用此模式:
- 使用非泛型术语标记关系。
- 将源顶点的标签与目标顶点的标签与关系名称相关联。
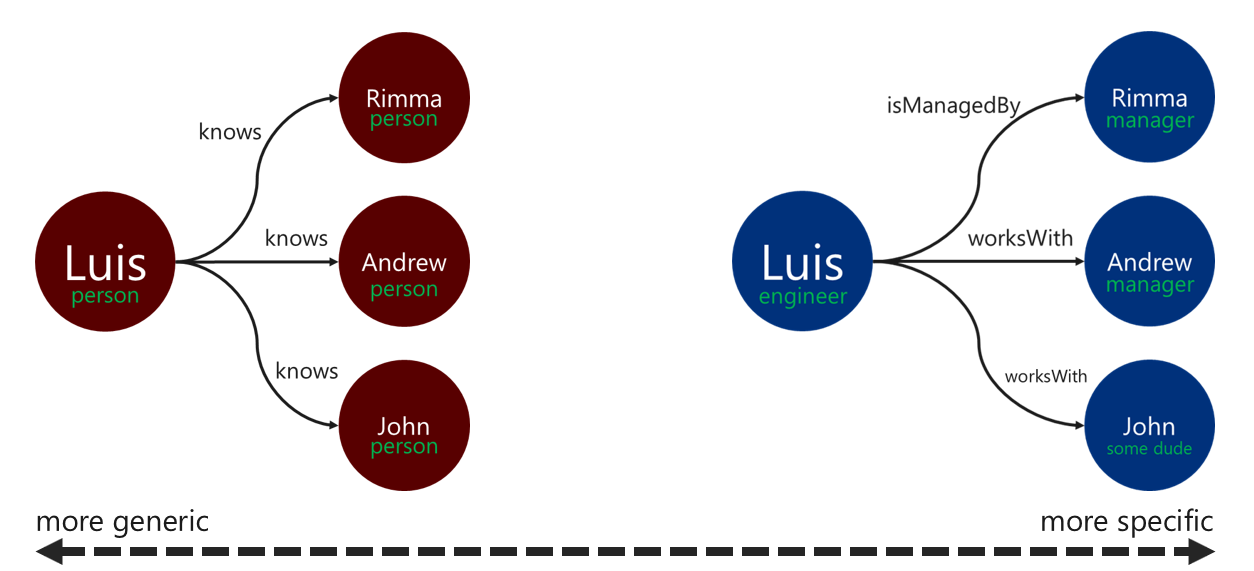
遍历器用于筛选边缘的标签越具体,越好。 此决策也会对查询成本产生重大影响。 可以使用该步骤随时 executionProfile 评估查询成本。