Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
适用于 Azure Cosmos DB 的 Azure Monitor 提供一个指标视图,用于监视帐户和创建仪表板。 默认情况下会收集 Azure Cosmos DB 指标。 此功能不需要你明确启用或配置任何东西。
指标定义
规范化 RU 消耗 量是介于 0% 到 100% 之间的指标,用于测量数据库或容器上预配吞吐量的利用率。 指标以 1 分钟间隔发布,定义为时间间隔内所有分区键范围的最大请求单位每秒(RU/秒)使用情况。 每个分区键范围映射到一个物理分区,并分配用于保存一系列可能的哈希值的数据。 通常,规范化 RU 百分比越高,已使用预配吞吐量越多。 该指标还可用于查看数据库或容器上各个分区键范围的利用率。
例如,假设你有一个容器,在其中设置 20,000 RU/秒的自动缩放最大吞吐量(缩放范围为 2000 - 20,000 RU/秒),并且有两个分区键范围(物理分区)P1 和 P2。 由于 Azure Cosmos DB 将预配的吞吐量平均分布到所有分区键范围, 因此 P1 和 P2 可以分别在 1000 到 10,000 RU/秒之间缩放。 假设间隔为 1 分钟,以给定秒为单位, P1 消耗了 6,000 RU,P2 消耗了 8,000 RU。 P1 的规范化 RU 消耗量为 P2 的 60% 到 80%。 整个容器的总体规范化 RU 消耗量为 MAX(60%, 80%) = 80%。
如果你有兴趣查看每秒间隔的请求单位消耗量,以及操作类型,可以使用可选的诊断日志并查询 PartitionKeyRUConsumption 表。 若要大致了解应用程序在 Azure Cosmos DB 资源上执行的作和状态代码,可以使用内置的 Azure Monitor 总请求 数(API for NoSQL)、 Mongo 请求、 Gremlin 请求或 Cassandra 请求 指标。 稍后,可以按 429 状态代码筛选这些请求,并按 作类型拆分这些请求。
规范化 RU/秒较高时会发生的事情和应该做的事情
当规范化 RU 消耗量达到给定分区键范围的 100% 时,如果客户端在该时间范围内向该特定分区键范围发出 1 秒的请求,则会收到速率限制错误(429)。
这不一定表示资源出现了问题。 默认情况下,Azure Cosmos DB 客户端 SDK 和数据导入工具(例如 Azure 数据工厂和批量执行程序库)会自动在 429s 上重试请求。 重试次数通常最多为九次。 因此,虽然指标中可能会显示 429 错误,但这些错误甚至可能尚未返回到应用程序。
一般情况下,对于生产工作负载而言,如果看到出现 429 代码的请求百分比在 1% - 5% 之间,并且端到端延迟可接受,那么这就是一个可以表明 RU/s 受到充分利用的良好迹象。 在这种情况下,“规范化 RU 消耗量”指标达到 100% 仅表示在某一秒内,至少有一个分区键范围使用了其所有预配的吞吐量。 这是可接受的,因为 429 错误的整体比率仍然较低。 无需执行进一步操作。
若要确定请求到数据库或容器后返回 429 状态码的请求百分比,请从 Azure Cosmos DB 帐户中导航至 Insights>请求>按状态代码查看总请求数。 筛选到特定数据库和容器。 对于 API for Gremlin,请使用“Gremlin 请求”指标。

如果多个分区键范围的“规范化 RU 消耗量”指标始终为 100%,且 429 错误的比率大于 5%,建议增加吞吐量。 可使用 Azure Monitor 指标和 Azure Monitor 诊断日志查明哪些操作繁忙及其使用率峰值是多少。 若要了解最佳做法,请参阅 有关缩放预配吞吐量(RU/s)的最佳做法。
并非总是仅因为规范化 RU 已达到 100%,就会看到 429 速率限制错误。 这是因为规范化 RU 是表示所有分区键范围的最大使用量的单个值。 一个分区键范围可能繁忙,但其他分区键范围可以处理请求,而不会出现问题。 例如,单个操作(如在分区键范围内消耗所有 RU/s 的存储过程)会导致规范化 RU 消耗指标出现短暂的峰值。 在这种情况下,如果总体请求速率较低,或者对不同分区键范围的其他分区发出请求,则不存在任何即时速率限制错误。
若要了解详细信息,请参阅 诊断和排查 429 个异常。
如何监视热分区
“规范化 RU 消耗量”指标可用于监视工作负载是否具有热分区。 当一个或几个逻辑分区键由于请求量较高而消耗了过多的总 RU/s 时,即会出现热分区。 而造成这一情况的原因可能是分区键设计导致请求未能均匀分布。 这会导致许多请求定向到逻辑分区的小子集(这意味着分区键范围)变“热”。 由于逻辑分区的所有数据都驻留在一个分区键范围上,RU/s 总数均匀分布于所有分区键范围中,因此热分区可能会导致 429s,吞吐量的使用效率低下。
如何识别热分区
若要验证是否存在热分区,请导航到“见解”“吞吐量”>“按 PartitionKeyRangeID 列出的规范化 RU 消耗量(%)”。 筛选到特定数据库和容器。
每个分区键范围 ID 映射到一个物理分区。 如果某个 PartitionKeyRangeId 的规范化 RU 消耗量明显高于其他 PartitionKeyRangeId(例如,一个 PartitionKeyRangeId 的消耗量一直为 100%,而其他 PartitionKeyRangeId 的消耗量不超过 30%),则可能表示存在热分区。
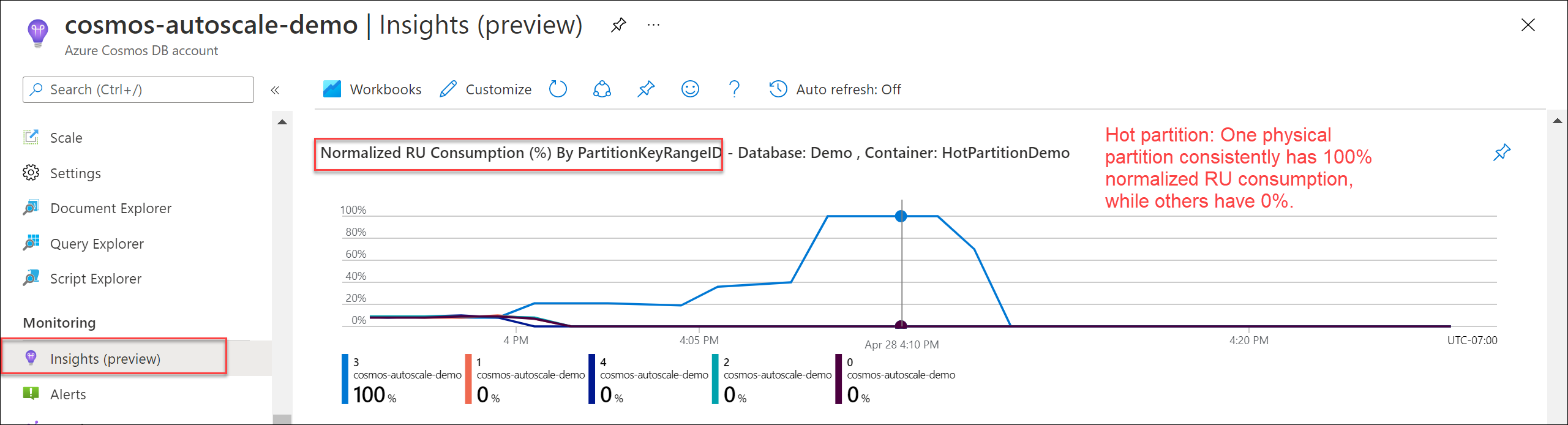
若要标识消耗最多 RU/秒的逻辑分区,请参阅 如何标识热分区。
规范化 RU 消耗量和自动缩放
如果在某一时间间隔的任意一秒内,至少有一个分区键范围消耗了其所有分配的 RU/秒,那么规范化 RU 消耗指标将显示为 100%。 一个常见问题是,为何规范化 RU 消耗量为 100%,但 Azure Cosmos DB 未使用自动缩放将 RU/秒扩展到最大吞吐量?
注释
以下信息描述了自动缩放的当前实现,将来可能会更改。
使用自动缩放时,仅当规范化 RU 消耗量在 5 秒间隔内持续稳定地保持 100% 时,Azure Cosmos DB 才会将 RU/秒扩展到最大吞吐量。 这样做是为了确保缩放逻辑对用户来说成本友好,因为它可确保单一的瞬间峰值不会导致不必要的缩放和更高的成本。 在出现短暂性的高峰时,系统通常会扩展到一个比上次所扩展到的 RU/秒更高,但比最大 RU/秒更低的值。
例如,假设你有一个容器,它的自动缩放最大吞吐量为 20,000 RU/秒(缩放范围为 2000 - 20,000 RU/秒),并且有两个分区键范围。 每个分区键范围的缩放范围为 1000 - 10,000 RU/秒。 由于自动缩放会提前预配所有必需的资源,因此你随时可以使用的量最多为 20,000 RU/秒。
现在假设流量出现间歇性高峰:
在一秒内,分区 1 峰值达到 10,000 RU/秒,然后在接下来的四秒内降至 1,000 RU/秒。
同时,分区 2 峰值达到 8,000 RU/秒,然后在接下来的四秒内下降到 1,000 RU/秒。
这是指标的行为方式:
规范化 RU 消耗量(显示跨所有分区间隔的最大使用量)显示 100% 利用率,因为分区 1 达到了 1 秒最大使用量。
但是,预配的吞吐量和自动缩放的 RU 指标不会因为 1 秒的峰值而增加至最大 RU/秒。 它根据 5 秒间隔调整规模,以提高成本效益。 因此,对前面的示例而言,基于 5 秒间隔,分区 1 和分区 2 的 RU 消耗没有达到 10,000 RU/秒。
因此,即使自动缩放未缩放到最大值,你仍能够使用该峰值秒的总 RU/秒。 若要验证 RU/秒消耗量,可以使用可选的“诊断日志”功能,查询所有分区键范围内每秒水平的总体 RU/秒消耗量。
CDBPartitionKeyRUConsumption
| where TimeGenerated >= (todatetime('2022-01-28T20:35:00Z')) and TimeGenerated <= todatetime('2022-01-28T20:40:00Z')
| where DatabaseName == "MyDatabase" and CollectionName == "MyContainer"
| summarize sum(RequestCharge) by bin(TimeGenerated, 1sec), PartitionKeyRangeId
| render timechart
一般而言,对于使用自动缩放的生产工作负载,如果你发现 1-5% 的请求出现了 429 错误,并且端到端延迟可接受,则这是一个工作正常的信号,表示 RU 已得到充分利用。 即使规范化 RU 消耗量偶尔达到 100%,自动缩放也不会纵向扩展到最大 RU/秒,这是正常的,因为 429 错误的整体比率较低。 无需执行任何操作。
小窍门
如果使用自动缩放,并发现规范化 RU 消耗量始终是 100%,并且你持续扩展到最大 RU/秒,这表示使用手动吞吐量可能更具成本效益。 若要确定自动缩放还是手动吞吐量最适合工作负荷,请参阅 如何选择标准(手动)和自动缩放预配的吞吐量。 Azure Cosmos DB 还会根据工作负荷模式发送 成本建议 ,以建议手动或自动缩放吞吐量。
查看规范化请求单位消耗指标
登录到 Azure 门户。
在左侧导航栏中选择“监视”,然后选择“指标”。
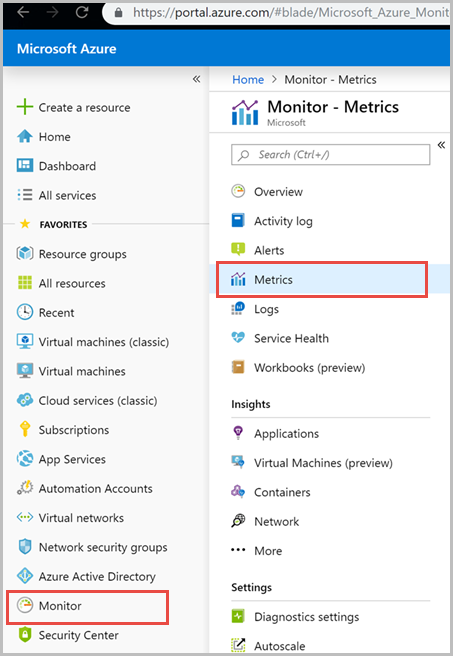
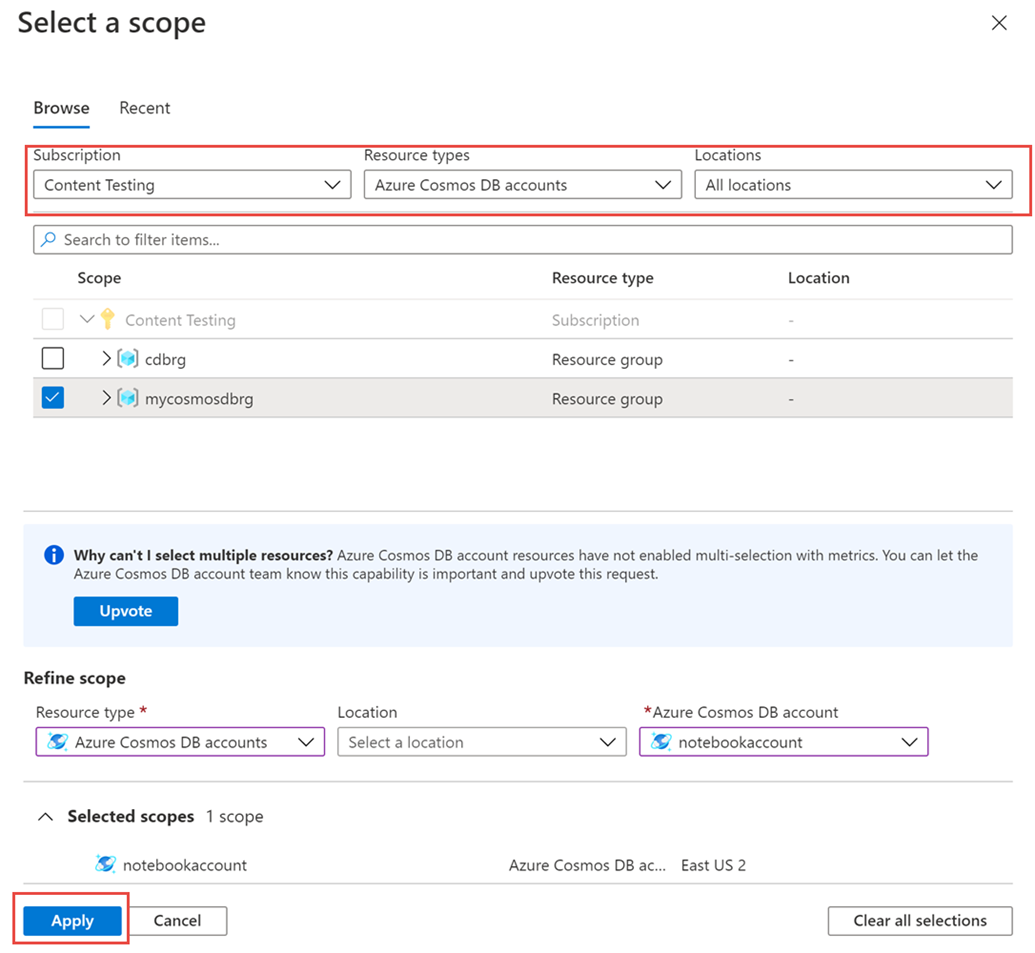
从“指标”窗格中选择一个资源,然后选择所需的订阅和资源组>。 对于“资源类型”,请选择“Azure Cosmos DB 帐户”,接着选择你的现有 Azure Cosmos DB 帐户之一,然后选择“应用”。
接下来,可以从可用指标列表中选择一个指标。 可以选择特定于请求单位、存储、延迟、可用性、Cassandra 和其他方面的指标。 若要详细了解此列表中的所有可用指标,请参阅按类别列出的指标一文。 在此示例中,我们选择“规范化 RU 消耗”指标,并选择“最大值”作为聚合值。
除这些详细信息外,还可以选择指标的“时间范围”和“时间粒度”。 最多可以查看过去 30 天的指标。 应用筛选器后,系统会根据该筛选器显示图表。
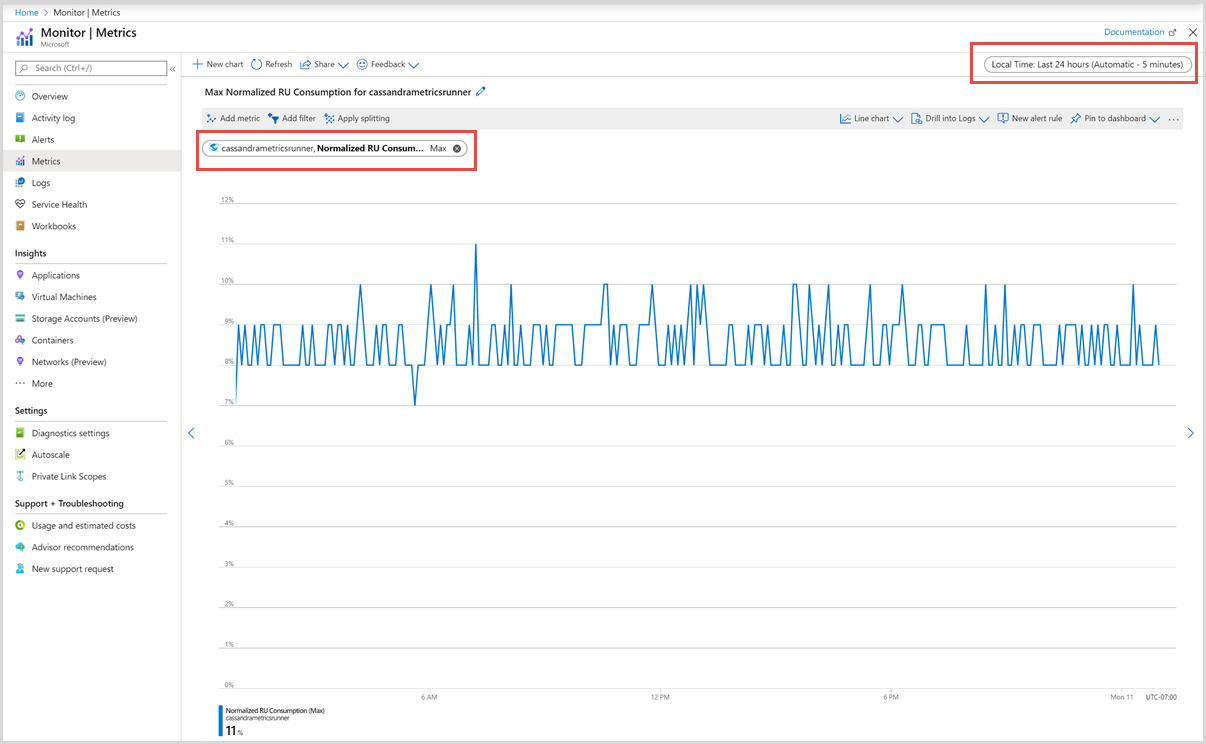



针对“规范化 RU 消耗量”指标的筛选器
还可以按特定的 CollectionName、DatabaseName、PartitionKeyRangeID 和区域筛选所显示的指标和图表。 若要筛选指标,请选择 “添加筛选器 ”,然后选择所需的属性,例如 CollectionName 和感兴趣的相应值。 然后,图中会显示在所选时间段内针对该容器的“规范化 RU 消耗量”指标。
可以使用“应用拆分”选项对指标进行分组。 对于共享吞吐量数据库,“规范化 RU”指标仅以数据库粒度显示数据,不会显示每个集合的任何数据。 因此按集合名称应用拆分时,将看不到共享吞吐量数据库的任何数据。
而是显示每个容器的规范化请求单位消耗指标,如下图所示:
