教程:使用 Azure Cosmos DB for PostgreSQL 设计实时分析仪表板
适用对象:![]() Azure Cosmos DB for PostgreSQL(由 PostgreSQL 的 Citus 数据库扩展提供支持)
Azure Cosmos DB for PostgreSQL(由 PostgreSQL 的 Citus 数据库扩展提供支持)
在本教程中,你将使用适用于 PostgreSQL 的 Azure Cosmos DB 来了解如何执行以下操作:
- 创建群集
- 使用 psql 实用工具创建架构
- 在节点之间将表分片
- 生成示例数据
- 执行汇总
- 查询原始数据和聚合数据
- 使数据过期
先决条件
如果没有 Azure 订阅,请在开始前创建一个试用版订阅帐户。
创建群集
登录到 Azure 门户,并按照以下步骤创建 Azure Cosmos DB for PostgreSQL 群集:
转到 Azure 门户中的创建 Azure Cosmos DB for PostgreSQL 群集。
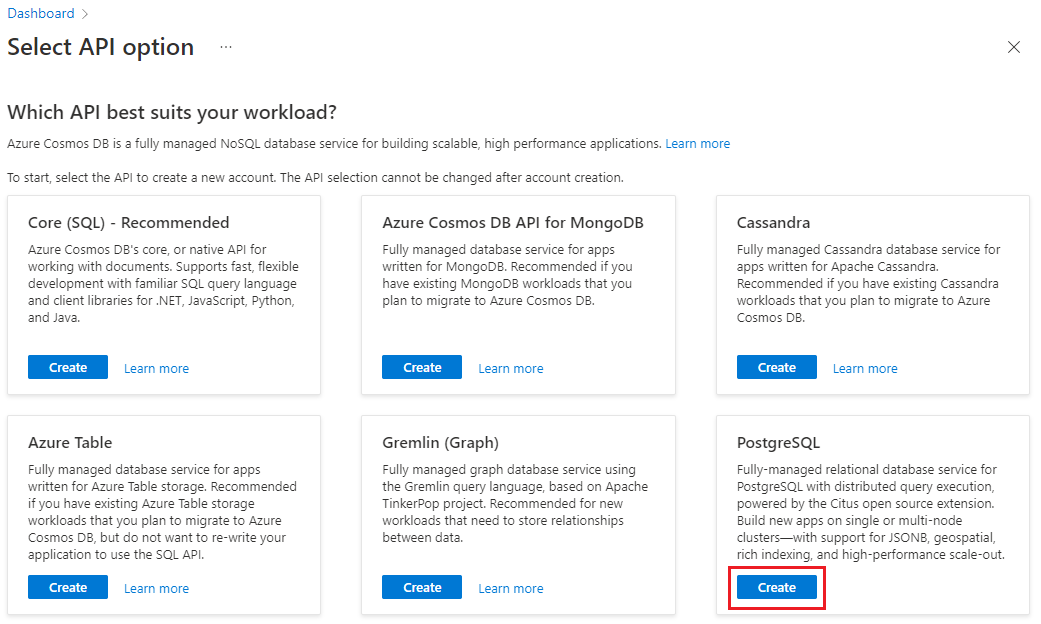
在“创建适用于 PostgreSQL 的 Azure Cosmos DB 群集”窗体上:
在“基本信息”选项卡上填写相关信息。
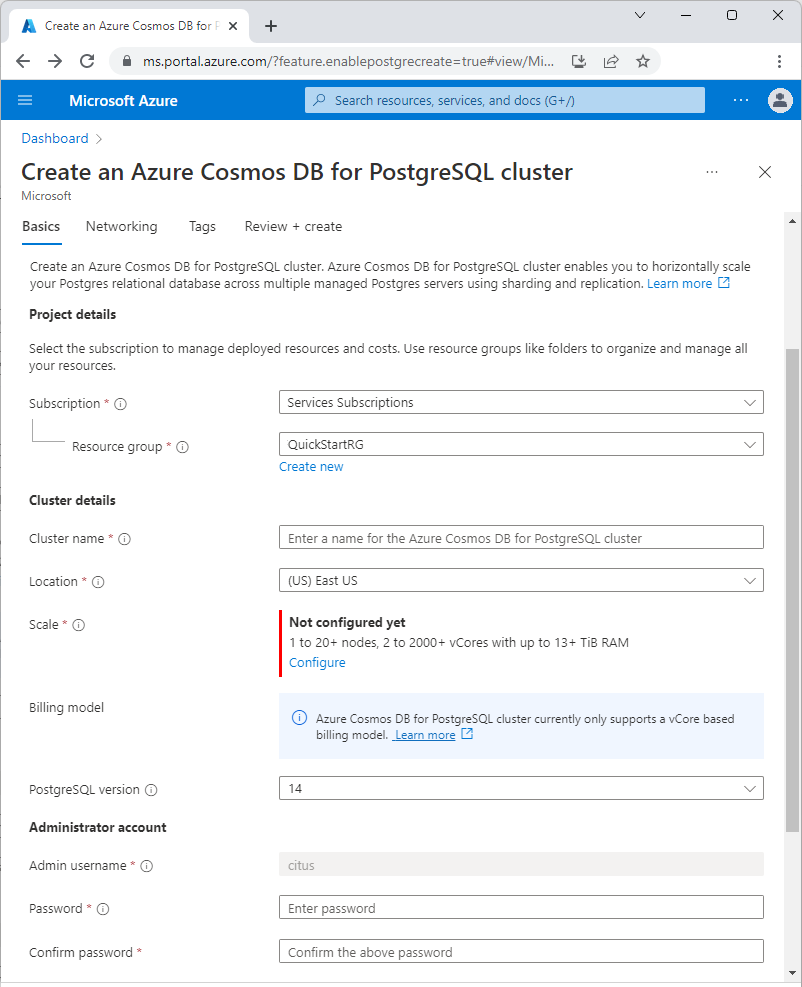
大多数选项都是一目了然的,但请记住:
- 群集名称决定应用程序用来进行连接的 DNS 名称(采用
<node-qualifier>-<clustername>.<uniqueID>.postgres.database.chinacloudapi.cn格式)。 - 可以选择主要 PostgreSQL 版本,例如 15。 Azure Cosmos DB for PostgreSQL 始终支持所选主要 Postgres 版本的最新 Citus 版本。
- 管理员用户名必须是值
citus。 - 可以将数据库名称保留为默认值“citus”,也可以定义唯一的数据库名称。 预配群集后无法重命名数据库。
- 群集名称决定应用程序用来进行连接的 DNS 名称(采用
在屏幕底部选择“下一步: 网络”。
在“网络”屏幕中,选择“允许从 Azure 内的 Azure 服务和资源公开访问此群集”。
选择“查看 + 创建”,在验证通过时,选择“创建”以创建群集。
预配需要数分钟。 页面会重定向,以监视部署。 当状态从“部署进行中”更改为“部署已完成”时,请选择“转到资源”。
使用 psql 实用工具创建架构
使用 psql 连接到 Azure Cosmos DB for PostgreSQL 后,可以完成一些基本任务。 本教程将引导你从 Web 分析引入流量数据,然后汇总数据以基于这些数据提供实时仪表板。
让我们创建一个使用所有原始 Web 流量数据的表。 在 psql 终端中运行以下命令:
CREATE TABLE http_request (
site_id INT,
ingest_time TIMESTAMPTZ DEFAULT now(),
url TEXT,
request_country TEXT,
ip_address TEXT,
status_code INT,
response_time_msec INT
);
我们还要创建一个表用于保存每分钟的聚合,并创建一个表用于保留上次汇总数据的位置。 还在 psql 中运行以下命令:
CREATE TABLE http_request_1min (
site_id INT,
ingest_time TIMESTAMPTZ, -- which minute this row represents
error_count INT,
success_count INT,
request_count INT,
average_response_time_msec INT,
CHECK (request_count = error_count + success_count),
CHECK (ingest_time = date_trunc('minute', ingest_time))
);
CREATE INDEX http_request_1min_idx ON http_request_1min (site_id, ingest_time);
CREATE TABLE latest_rollup (
minute timestamptz PRIMARY KEY,
CHECK (minute = date_trunc('minute', minute))
);
现在,可以使用以下命令在表列表中查看新建的表:
\dt
在节点之间将表分片
Azure Cosmos DB for PostgreSQL 部署基于用户指定的列的值存储不同节点上的表行。 此“分布列”标识数据在节点之间的分片方式。
让我们将分布列设置为 site_id,即分片键。 在 psql 中运行以下函数:
SELECT create_distributed_table('http_request', 'site_id');
SELECT create_distributed_table('http_request_1min', 'site_id');
重要
需要分发表或使用基于架构的分片才能利用 Azure Cosmos DB for PostgreSQL 性能功能。 如果不分发表或架构,则工作器节点无法帮助运行涉及其数据的查询。
生成示例数据
现在,我们的群集应已准备好引入一些数据。 可以通过 psql 连接在本地运行以下命令,以持续插入数据。
DO $$
BEGIN LOOP
INSERT INTO http_request (
site_id, ingest_time, url, request_country,
ip_address, status_code, response_time_msec
) VALUES (
trunc(random()*32), clock_timestamp(),
concat('http://example.com/', md5(random()::text)),
('{China,India,USA,Indonesia}'::text[])[ceil(random()*4)],
concat(
trunc(random()*250 + 2), '.',
trunc(random()*250 + 2), '.',
trunc(random()*250 + 2), '.',
trunc(random()*250 + 2)
)::inet,
('{200,404}'::int[])[ceil(random()*2)],
5+trunc(random()*150)
);
COMMIT;
PERFORM pg_sleep(random() * 0.25);
END LOOP;
END $$;
该查询会每秒插入大约八行。 系统会根据分布列 site_id 的指示,在不同的工作器节点上存储行。
注意
让数据生成查询保持运行,并针对本教程中所述的剩余命令打开另一个 psql 连接。
查询
使用 Azure Cosmos DB for PostgreSQL 可让多个节点并行处理查询以加快速度。 例如,数据库可在工作器节点上计算 SUM 和 COUNT 等聚合,并将结果合并成最终的应答。
以下查询统计每分钟的 Web 请求数并提供一些统计信息。 请尝试在 psql 中运行此查询并观察结果。
SELECT
site_id,
date_trunc('minute', ingest_time) as minute,
COUNT(1) AS request_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 1 ELSE 0 END) as success_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 0 ELSE 1 END) as error_count,
SUM(response_time_msec) / COUNT(1) AS average_response_time_msec
FROM http_request
WHERE date_trunc('minute', ingest_time) > now() - '5 minutes'::interval
GROUP BY site_id, minute
ORDER BY minute ASC;
汇总数据
前面的查询在早期阶段可顺利运行,但随着数据的不断增加,其性能将会降级。 即使使用分布式处理,预先计算数据也要比反复重新计算数据更快。
可以通过定期将原始数据汇总到聚合表,来确保仪表板保持快速工作状态。 可以尝试聚合持续时间。 我们使用了每分钟聚合表,但可以改为将数据拆分为 5、15 或 60 分钟。
为了更轻松地运行此汇总,我们将它放入 plpgsql 函数中。 在 psql 中运行以下命令来创建 rollup_http_request 函数。
-- initialize to a time long ago
INSERT INTO latest_rollup VALUES ('10-10-1901');
-- function to do the rollup
CREATE OR REPLACE FUNCTION rollup_http_request() RETURNS void AS $$
DECLARE
curr_rollup_time timestamptz := date_trunc('minute', now());
last_rollup_time timestamptz := minute from latest_rollup;
BEGIN
INSERT INTO http_request_1min (
site_id, ingest_time, request_count,
success_count, error_count, average_response_time_msec
) SELECT
site_id,
date_trunc('minute', ingest_time),
COUNT(1) as request_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 1 ELSE 0 END) as success_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 0 ELSE 1 END) as error_count,
SUM(response_time_msec) / COUNT(1) AS average_response_time_msec
FROM http_request
-- roll up only data new since last_rollup_time
WHERE date_trunc('minute', ingest_time) <@
tstzrange(last_rollup_time, curr_rollup_time, '(]')
GROUP BY 1, 2;
-- update the value in latest_rollup so that next time we run the
-- rollup it will operate on data newer than curr_rollup_time
UPDATE latest_rollup SET minute = curr_rollup_time;
END;
$$ LANGUAGE plpgsql;
创建函数后,请执行它来汇总数据:
SELECT rollup_http_request();
将数据放入预先聚合的表单后,可以查询汇总表以获取与前面相同的报告。 运行以下查询:
SELECT site_id, ingest_time as minute, request_count,
success_count, error_count, average_response_time_msec
FROM http_request_1min
WHERE ingest_time > date_trunc('minute', now()) - '5 minutes'::interval;
使旧数据过期
汇总可以加快查询的速度,但我们仍需将旧数据过期,以免存储成本超限。 确定要将每个粒度的数据保留多长时间,并使用标准查询来删除已过期的数据。 在以下示例中,我们决定将原始数据保留一天,并在一个月中每隔一分钟聚合一次数据:
DELETE FROM http_request WHERE ingest_time < now() - interval '1 day';
DELETE FROM http_request_1min WHERE ingest_time < now() - interval '1 month';
在生产环境中,可将这些查询包装在某个函数中,并在 cron 作业中每隔一分钟调用该函数。
清理资源
在前面的步骤中,你已在群集中创建了 Azure 资源。 如果你认为以后不需要这些资源,请删除该群集。 在群集的“概述”页中,按“删除”按钮。 弹出页面上出现提示时,请确认群集的名称,然后单击最后一个“删除”按钮。
后续步骤
在本教程中,你已了解如何预配群集。 你已使用 psql 连接到该组,创建了架构并分布了数据。 你已了解如何查询原始表单中的数据、定期聚合数据、查询聚合表,并使旧数据过期。