Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
适用于: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
在映射数据流中,许多转换属性都作为表达式输入。 这些表达式由列值、参数、函数、运算符和文本组成,它们在运行时的计算结果为 Spark 数据类型。 映射数据流具有一个专门的功能,旨在协助您构建被称为“表达式生成器”的表达式。 通过 IntelliSense 代码完成功能来实现突出显示、语法检查和自动完成,表达式生成器可简化数据流的生成。 本文介绍如何使用表达式生成器有效地生成业务逻辑。
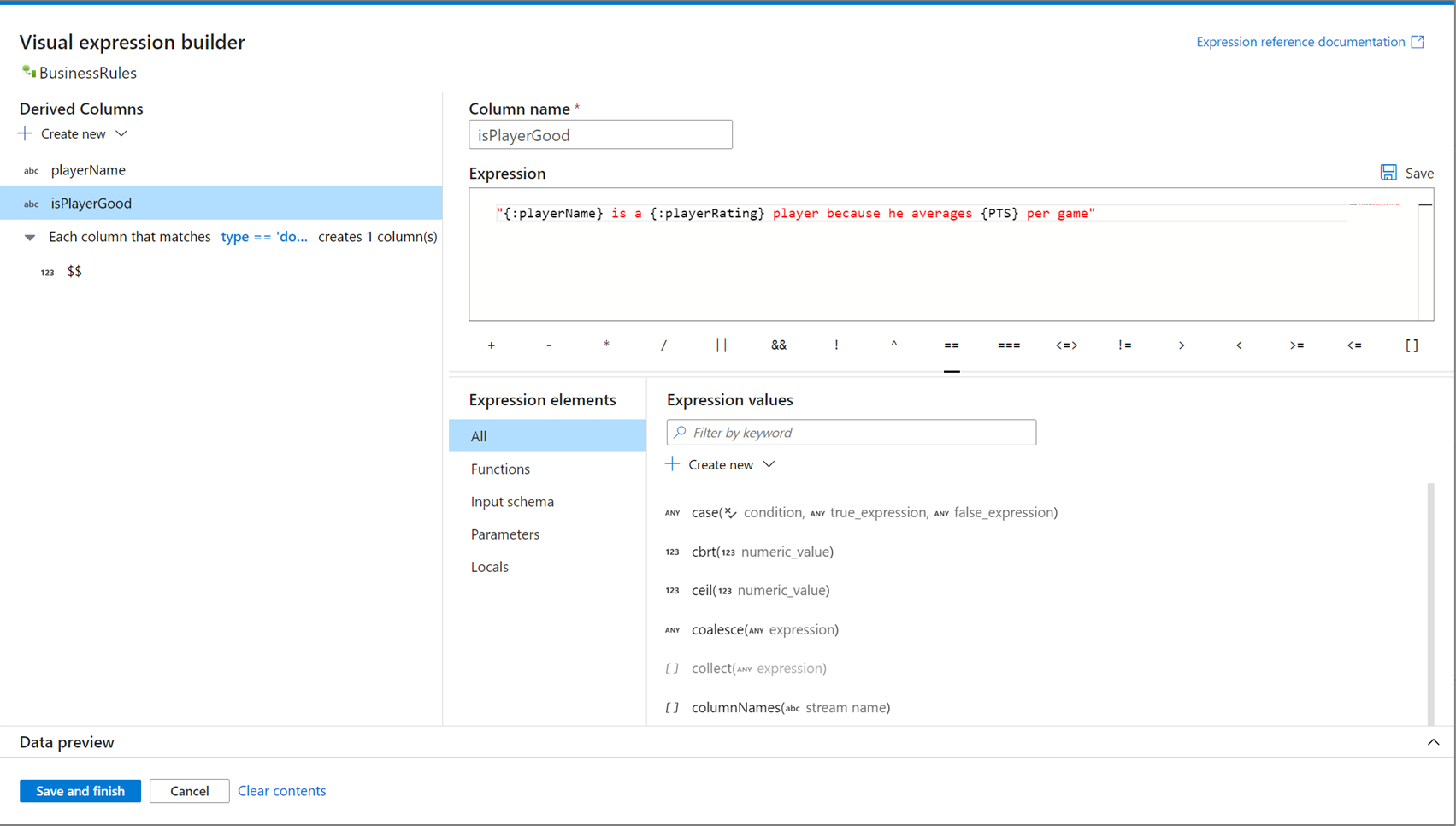
打开表达式生成器
有多个打开表达式生成器的入口点。 这些都取决于数据流转换的具体上下文。 最常见的用例是转换(如派生列和聚合转换),用户使用数据流表达式语言创建或更新列。 可以通过在列列表上方选择“打开表达式生成器”来打开表达式生成器。 还可以选择列上下文,然后直接打开该表达式的表达式生成器。
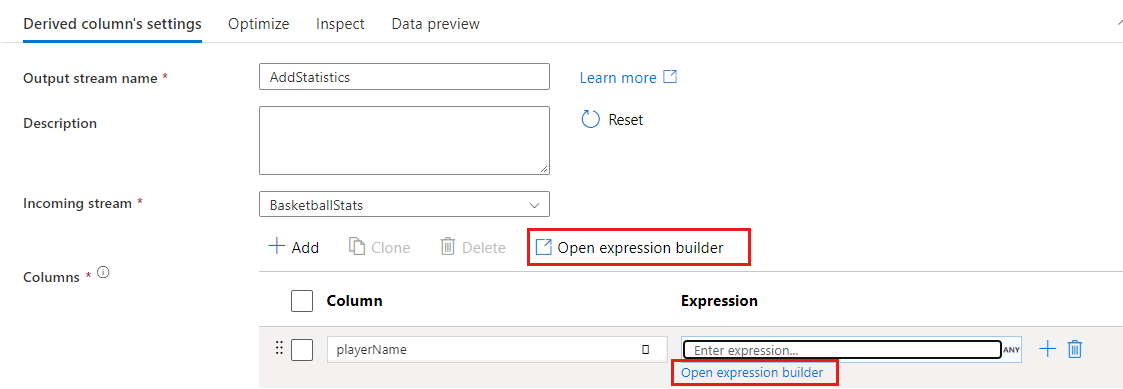
在某些转换(如筛选器)中,单击蓝色表达式文本框会打开表达式生成器。
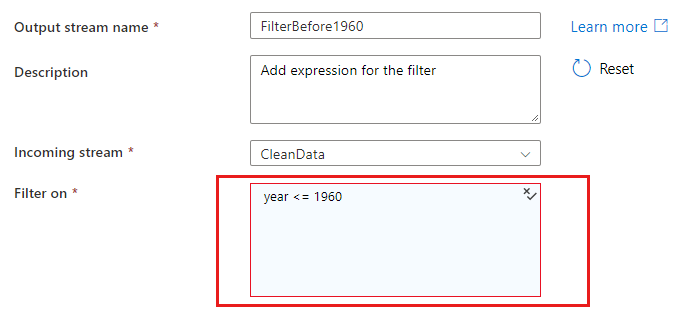
在使用匹配或分组依据条件引用列时,表达式可以从列中提取值。 若要创建表达式,请选择“计算列”。

如果表达式或文本值是有效的输入,请选择“添加动态内容”以生成计算结果为文本值的表达式。

表达式元素
在映射数据流中,表达式可以由列值、参数、函数、局部变量、运算符和文本组成。 这些表达式的计算结果必须为 Spark 数据类型,如字符串、布尔值或整数。
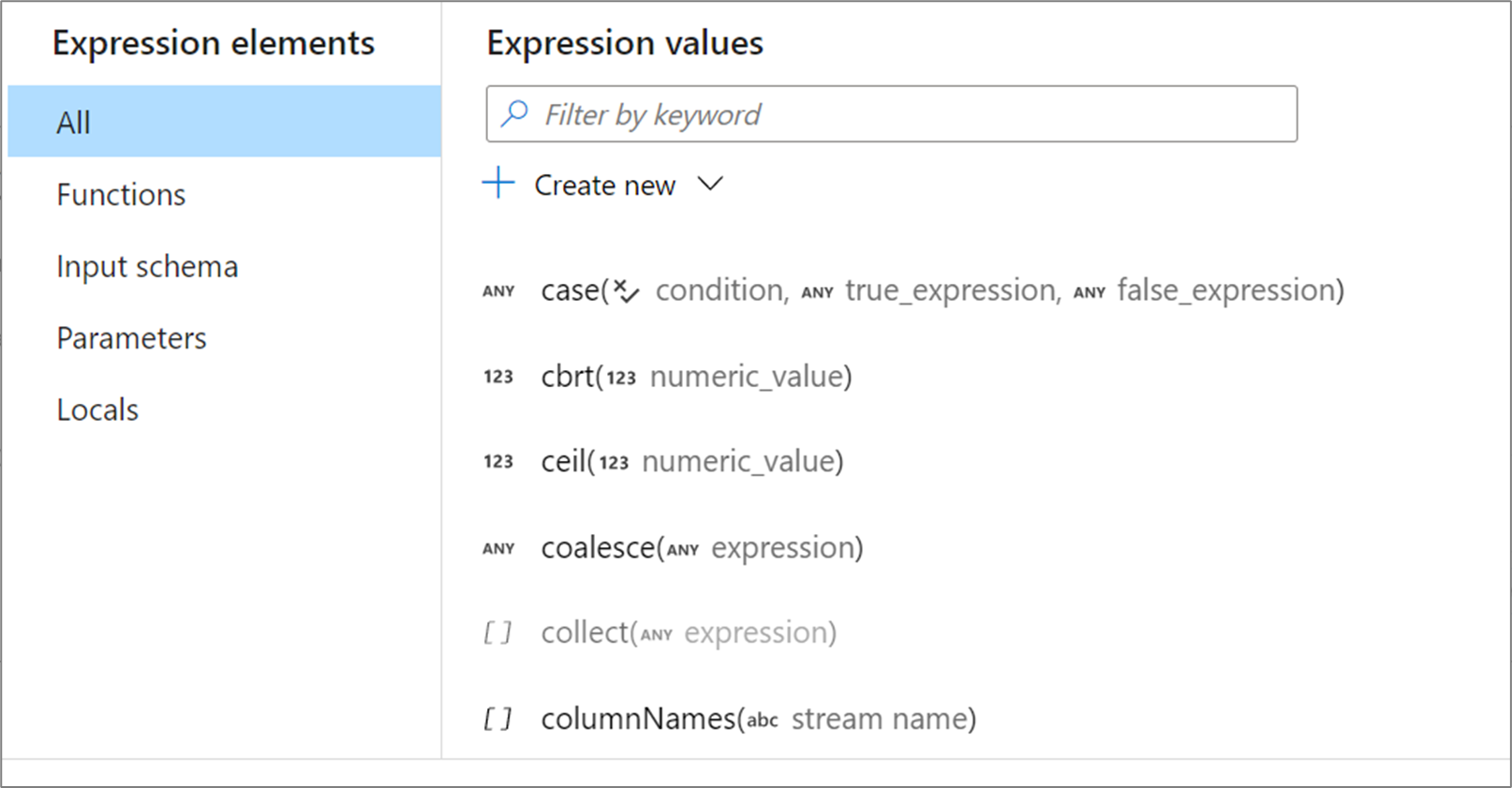
Functions
映射数据流具有可用于表达式的内置函数和运算符。 有关可用函数的列表,请参阅映射数据流语言参考。
用户定义的函数(预览版)
映射数据流支持创建和使用用户定义的函数。 若要了解如何创建和使用用户定义的函数,请参阅用户定义的函数。
寻址数组索引
在处理返回数组类型的列或函数时,请使用括号 ([]) 访问特定元素。 如果索引不存在,表达式的计算结果为 NULL。
重要
在映射数据流时,数组从 1 开始,这意味着第一个元素使用索引 1 引用。 例如,myArray[1] 将访问名为“myArray”的数组的第一个元素。
输入架构
如果数据流在其任何源中使用定义的架构,则你可以在许多表达式中按名称引用列。 如果使用架构偏差,则可以使用 byName() 或 byNames() 函数显式引用列,或使用列模式进行匹配。
包含特殊字符的列名称
如果列名称包含特殊字符或空格,请用大括号将名称括起来,以便在表达式中引用它们。
{[dbo].this_is my complex name$$$}
参数
参数是在运行时从管道传递到数据流的值。 若要引用参数,请选择“表达式元素”视图中的参数,或者在其名称前面用美元符号引用该参数。 例如,通过 $parameter1 引用名为 parameter1 的参数。 若要了解详细信息,请参阅将映射数据流参数化。
缓存查找
通过缓存查找,你可以对缓存接收器的输出进行内联查找。 每个接收器上可以使用两个函数:lookup() 和 outputs()。 引用这些函数的语法为 cacheSinkName#functionName()。 有关详细信息,请参阅缓存终端。
lookup() 以参数的形式接收当前转换中的匹配列,并返回一个与缓存接收器中键列匹配的行相等的复杂列。 返回的复杂列中包含一个子列,代表缓存接收器中映射的每个列。 例如,如果你有一个错误代码缓存存储器 errorCodeCache,该存储器有一个与代码匹配的键列和一个名为 Message 的列。 调用 errorCodeCache#lookup(errorCode).Message 将返回与传入的代码对应的消息。
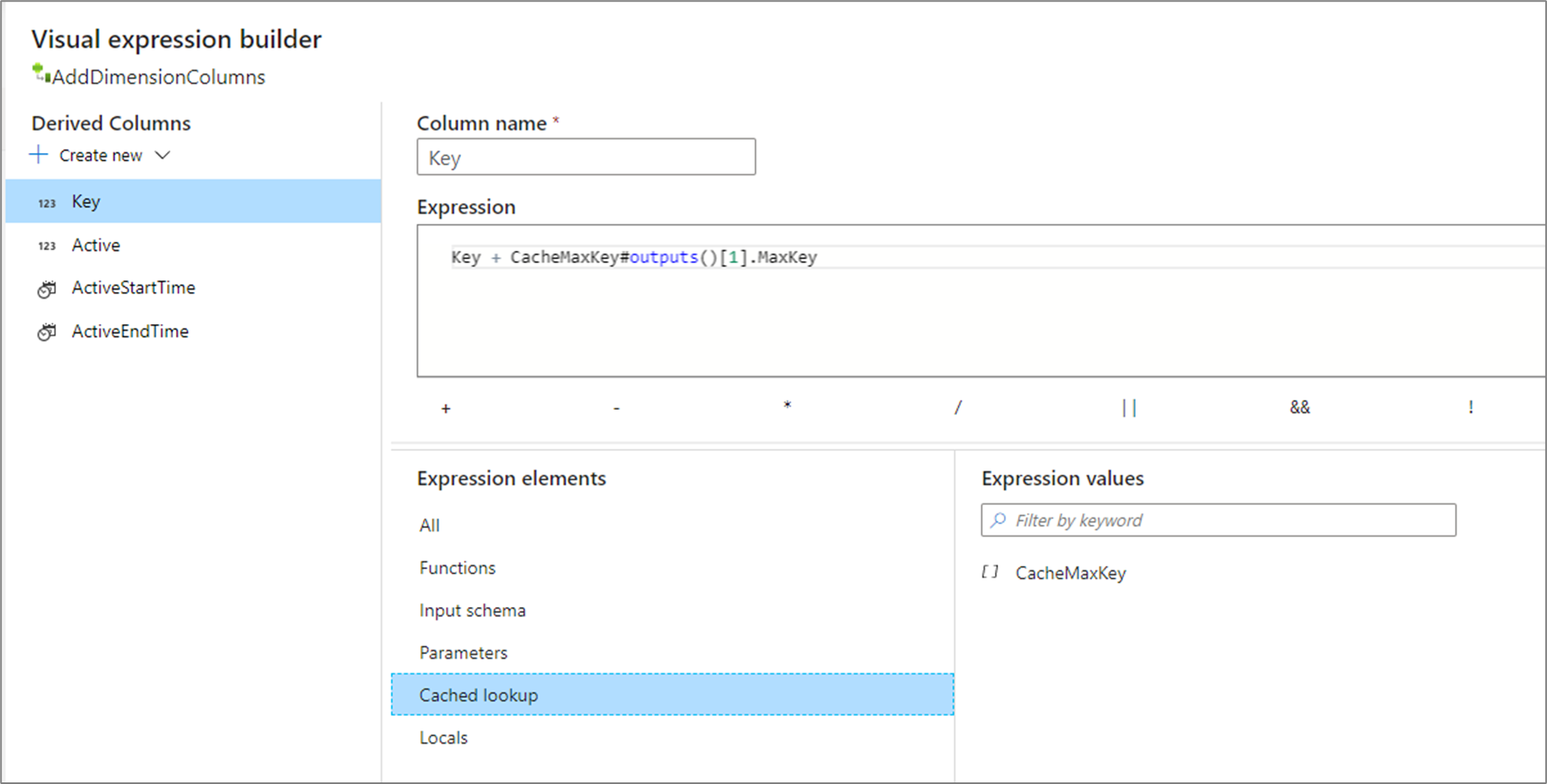
outputs() 不接收任何参数,并以一组复杂列的形式返回整个缓存池。 如果在接收器中指定了关键列,则无法调用此方法,并且仅在缓存接收器中有少量数据时才应使用此方法。 常见的用例是追加递增键的最大值。 如果缓存的单个聚合行 CacheMaxKey 包含列 MaxKey,则可以通过调用 CacheMaxKey#outputs()[1].MaxKey 引用第一个值。
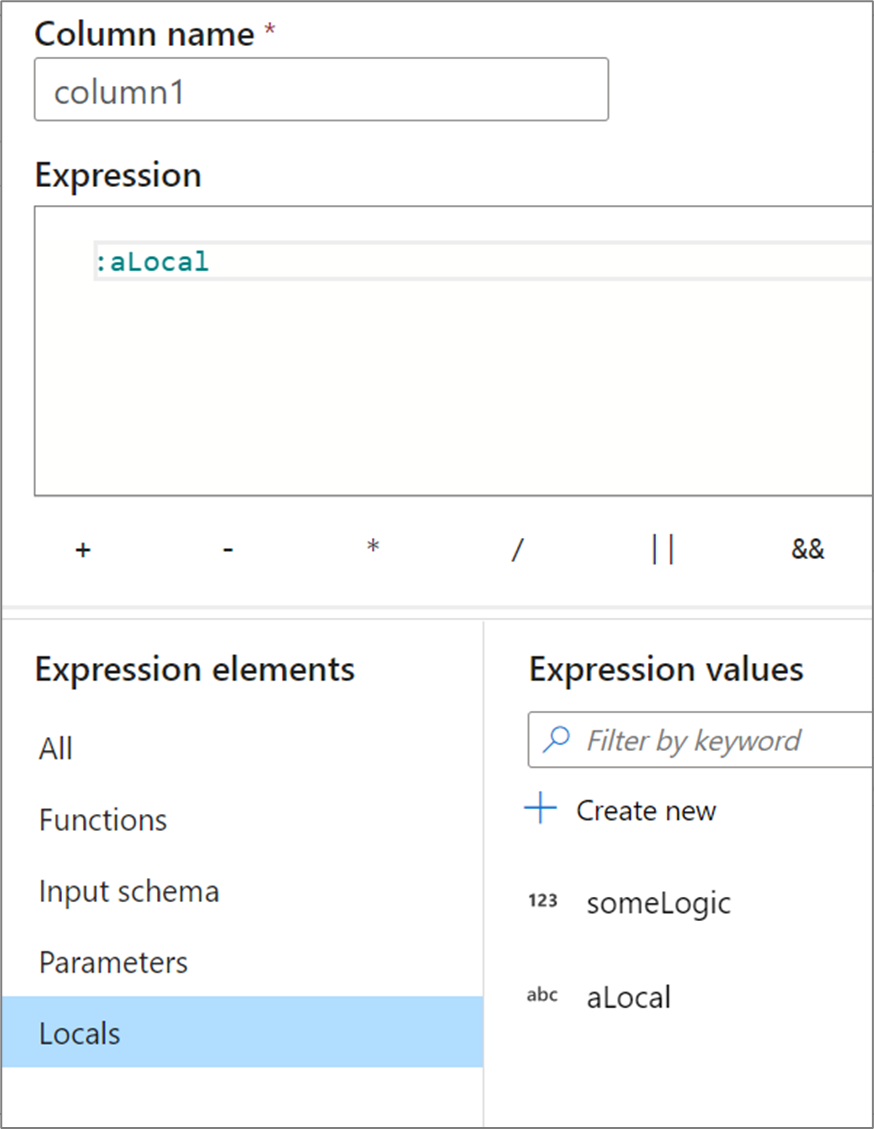
当地人
如果要跨多个列共享逻辑或想要划分逻辑,可以创建一个局部变量。 局部变量是一组逻辑,不会传播到下游的以下转换。 通过转到表达式元素并选择“局部变量”,可以在表达式生成器中创建局部变量 。 选择新建以创建一个新的。
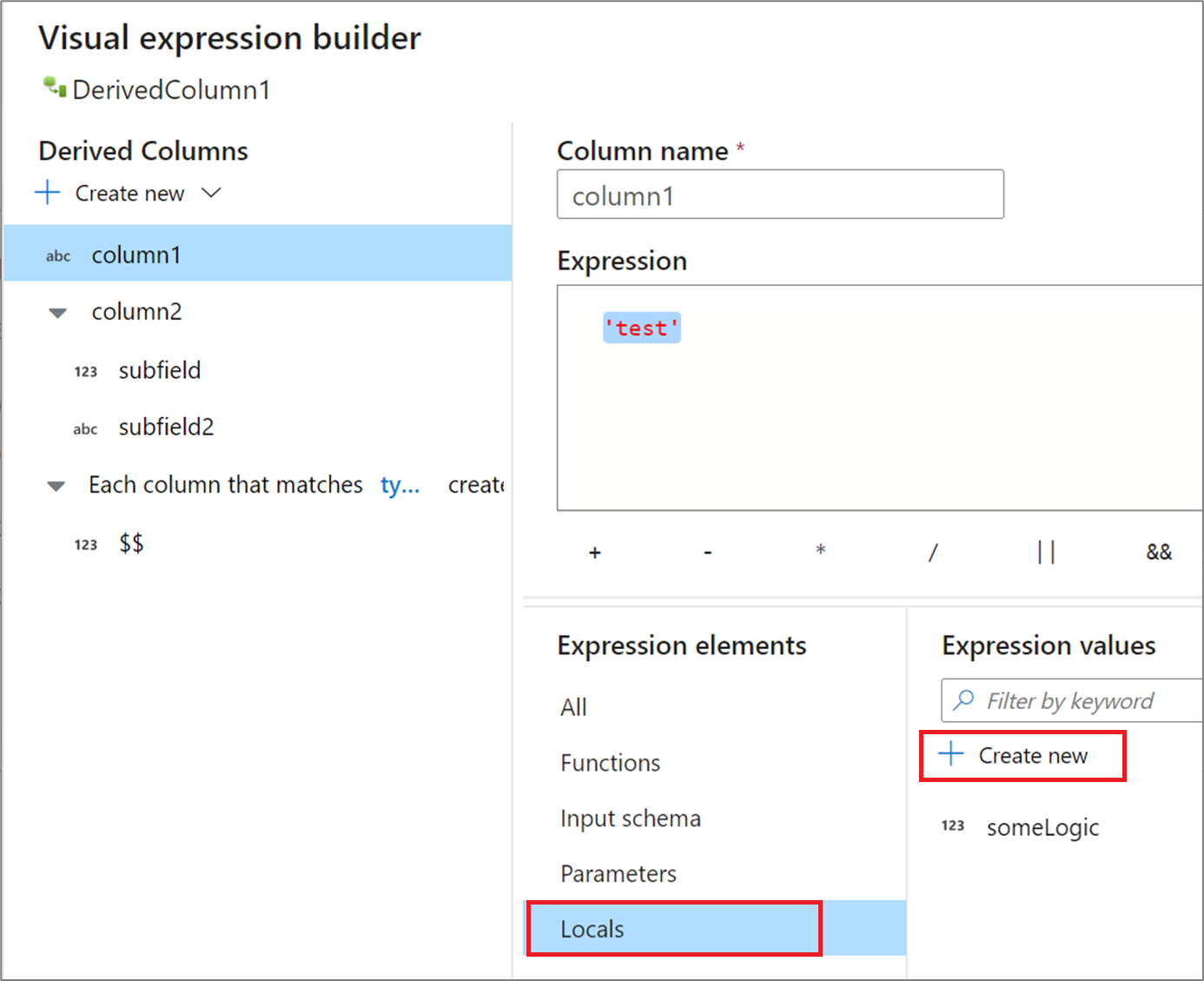
局部变量可以引用任何表达式元素,包括函数、输入架构、参数和其他局部变量。 引用其他局部变量时,顺序很重要,因为引用的局部变量需要“高于”当前的局部变量。
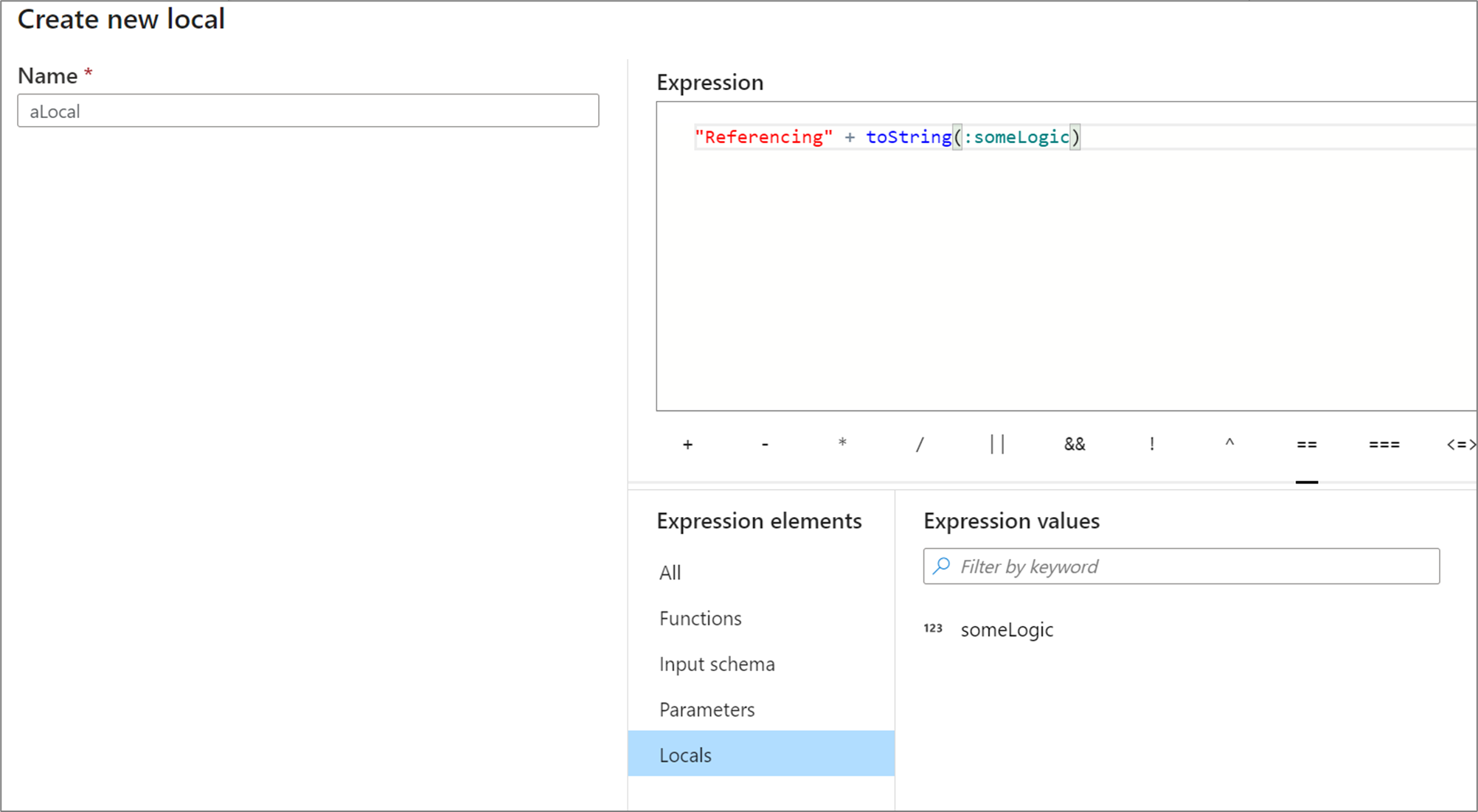
若要引用转换中的局部变量,请选择“表达式元素”视图中的局部变量,或者在其名称前面用冒号引用它。 例如,名为 local1 的局部变量将由 :local1 引用。 若要编辑局部变量的定义,请将鼠标悬停在“表达式元素”视图中,然后选择铅笔图标。
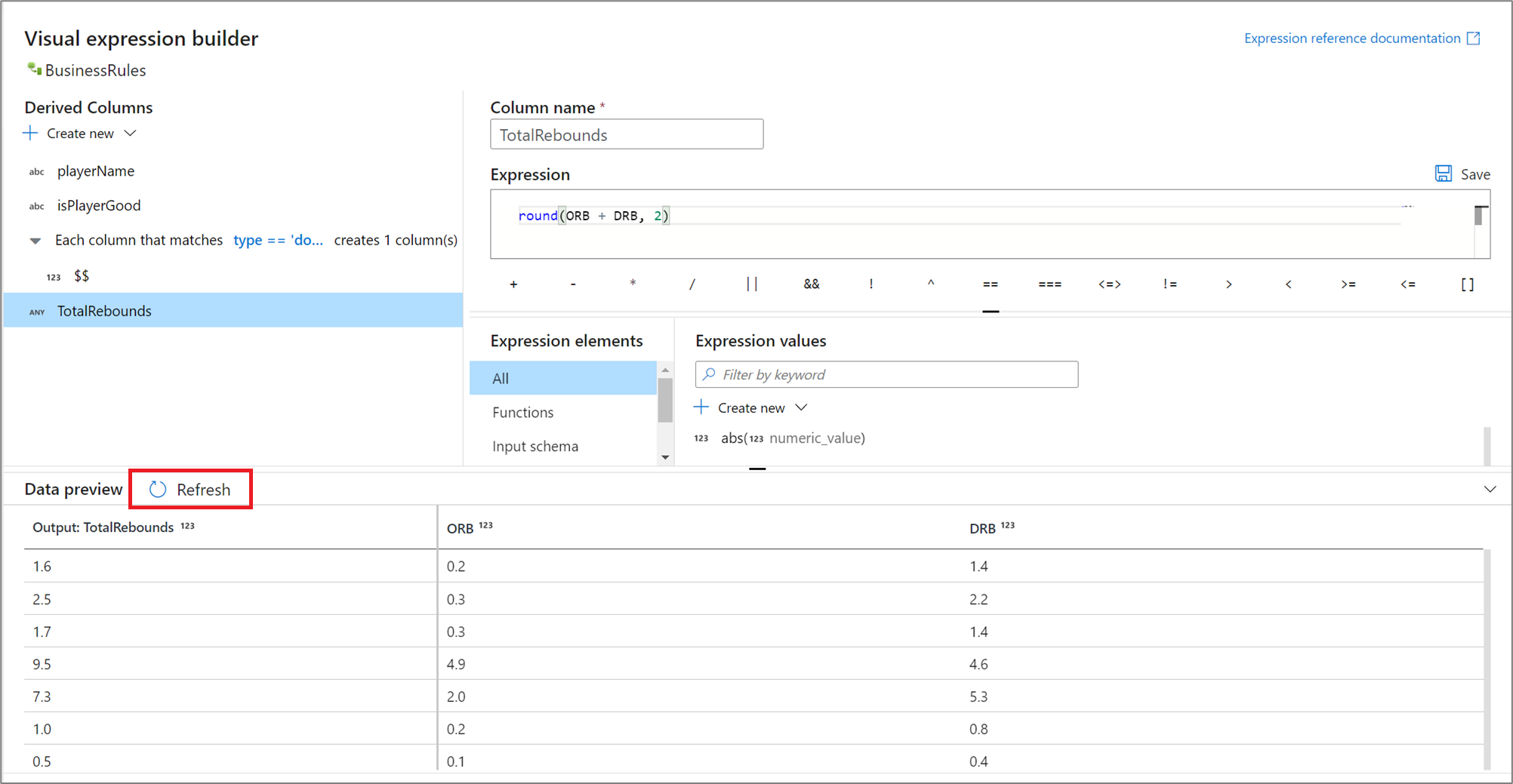
预览表达式结果
如果启用了调试模式,则可以交互方式使用调试群集预览表达式的计算结果。 选择数据预览旁边的“刷新”以更新数据预览的结果。 你可以看到给定输入列的每一行的输出。
字符串内插
创建使用表达式元素的长字符串时,请使用字符串内插来轻松生成复杂的字符串逻辑。 当参数包含在查询字符串中时,字符串内插可避免大量使用字符串串联。 使用双引号将文本字符串文本与表达式括起来。 可以包括表达式函数、列和参数。 若要使用表达式语法,请用大括号将其括起来,
字符串内插的一些示例:
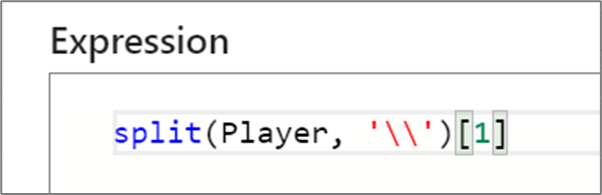
"My favorite movie is {iif(instr(title,', The')>0,"The {split(title,', The')[1]}",title)}""select * from {$tablename} where orderyear > {$year}""Total cost with sales tax is {round(totalcost * 1.08,2)}""{:playerName} is a {:playerRating} player"
注意
在 SQL 源查询中使用字符串内插语法时,查询字符串必须位于一行上,且不带“/n”。
注释表达式
使用单行和多行注释语法,将注释添加到代码表达式中。
以下示例是有效的注释:
/* This is my comment *//* This is amulti-line comment */
如果将注释放在您所写的表达式顶部,则该注释将显示在转换文本框中,用于记录您的转换表达式。

正则表达式
许多表达式语言函数使用正则表达式语法。 使用正则表达式函数时,表达式生成器会尝试将反斜杠 (\) 解释为转义字符序列。 在正则表达式中使用反斜杠时,请将整个正则表达式括在反引号 (`) 中,或使用双反斜杠。
使用反引号的示例:
regex_replace('100 and 200', `(\d+)`, 'digits')
使用双斜杠的示例:
regex_replace('100 and 200', '(\\d+)', 'digits')
键盘快捷方式
下面是表达式生成器中可用的快捷方式列表。 创建表达式时,大多数 intellisense 快捷方式都可用。
- Ctrl+K Ctrl+C:注释整行。
- Ctrl+K Ctrl+U:取消注释。
- F1:提供编辑器帮助命令。
- Alt+向下键:向下移动当前行。
- Alt+向上键:向上移动当前行。
- Ctrl+空格键:显示上下文帮助。
常用表达式
转换为日期或时间戳
若要在时间戳输出中包含字符串文本,请将转换包裹在 toString() 中。
toString(toTimestamp('12/31/2016T00:12:00', 'MM/dd/yyyy\'T\'HH:mm:ss'), 'MM/dd /yyyy\'T\'HH:mm:ss')
若要将毫秒从纪元转换为日期或时间戳,请使用 toTimestamp(<number of milliseconds>)。 如果时间以秒为单位,则乘以 1,000。
toTimestamp(1574127407*1000l)
上一个表达式末尾的“l”指示转换为长类型作为内联语法。
从纪元时间或 Unix 时间计算出的时间
toLong(currentTimestamp() - toTimestamp('1970-01-01 00:00:00.000', 'yyyy-MM-dd HH:mm:ss.SSS')) * 1000l
数据流时间评估
数据流处理直至毫秒级别。 对于“2018-07-31T20:00:00.2170000”,你会在输出中看到“2018-07-31T20:00:00.217”。 在服务的门户中,时间戳在“当前浏览器设置”中显示(可能会消除 217),但当你以端到端方式运行数据流时,217(毫秒部分)也会被处理。 可以使用 toString(myDateTimeColumn) 作为表达式,在预览中查看全精度数据。 在所有实际用途中,应将 datetime 视为 date/time 进行处理,而非视为字符串。