Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
数据流可在Azure 数据工厂管道和Azure Synapse Analytics管道中使用。 本文适用于映射数据流。 如果你不熟悉转换,请参阅介绍性文章: 使用映射数据流转换数据。
使用联接转换可以在映射数据流中合并来自两个源或流的数据。 输出流包括两个源中的所有列,这些列都基于联接条件进行匹配。
联接类型
映射数据流目前支持五种不同的联接类型。
内部联接
内连接只输出在两个表中具有匹配值的行。
左外部
左外部联接返回左侧流中的所有行以及右侧流中的匹配记录。 如果左侧流中的某一行没有匹配项,则右侧流中的输出列将设置为 NULL。 输出是内连接返回的行以及左侧数据流中不匹配的行。
注意
数据流使用的 Spark 引擎偶尔会由于联接条件中的可能笛卡尔产品而失败。 如果发生这种情况,可以切换到自定义交叉联接,并手动输入联接条件。 这可能会导致数据流的性能降低,因为执行引擎可能需要计算关系双方的所有行,然后筛选行。
右外部
右外连接返回右侧流中的所有行以及从左侧流获得的匹配记录。 如果右侧流中的某一行没有匹配项,则左侧流中的输出列将设置为 NULL。 输出是由内连接返回的行,加上来自右侧数据流中不匹配的行。
完全外连接
全外连接输出来自两侧的所有列和行,对于不匹配的列则使用 NULL 值。
自定义交叉联接
交叉联接根据条件输出两个流的叉积。 如果使用的条件不相等,请指定一个自定义表达式作为交叉联接条件。 输出流是满足联接条件的所有行。
可以将此联接类型用于非等值联接和 OR 条件。
如果您想显式生成完整的笛卡尔积,请在连接之前,在两个独立流的各流中使用派生列转换来创建用于匹配的合成键。 例如,在每个名为 SyntheticKey 的流的派生列中创建一个新列,并将其设置为等于 1。 然后使用 a.SyntheticKey == b.SyntheticKey 作为自定义联接表达式。
注意
在自定义交叉联接中,确保包含左右关系每一侧中的至少一列。 如果对静态值而不是每一侧的列执行交叉联接,则会对整个数据集进行完全扫描,从而导致数据流性能不佳。
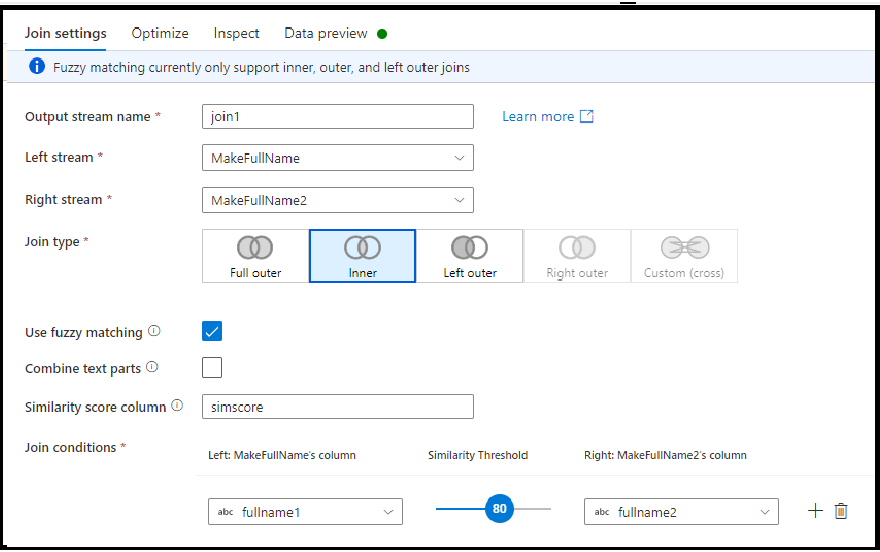
模糊联接
通过启用“使用模糊匹配”复选框选项,可以选择基于模糊联接逻辑进行联接,而不是完全列值匹配。
- 组合文本部分:使用此选项通过删除单词之间的空格来查找匹配项。 例如,如果启用此选项,则 Data Factory 与 DataFactory 匹配。
- 相似性分数列:可以选择将每一行的匹配分数存储在一个列中,方法是在这里输入一个新的列名来存储该值。
- 相似性阈值:选择一个介于 60 和 100 之间的值,作为所选列中的值之间的百分比匹配。
注意
模糊匹配目前仅适用于字符串列类型和内部、左外部和完整外部联接类型。 使用模糊匹配联接时,必须关闭广播优化。
配置
- 在“右边数据流”下拉菜单中选择要加入的数据流。
- 选择“联接类型”
- 选择要根据联接条件进行匹配的键列。 默认情况下,数据流在每个流中的一列之间查找相等性。 若要通过计算值进行比较,请将鼠标悬停在列下拉菜单上,然后选择“计算列”。
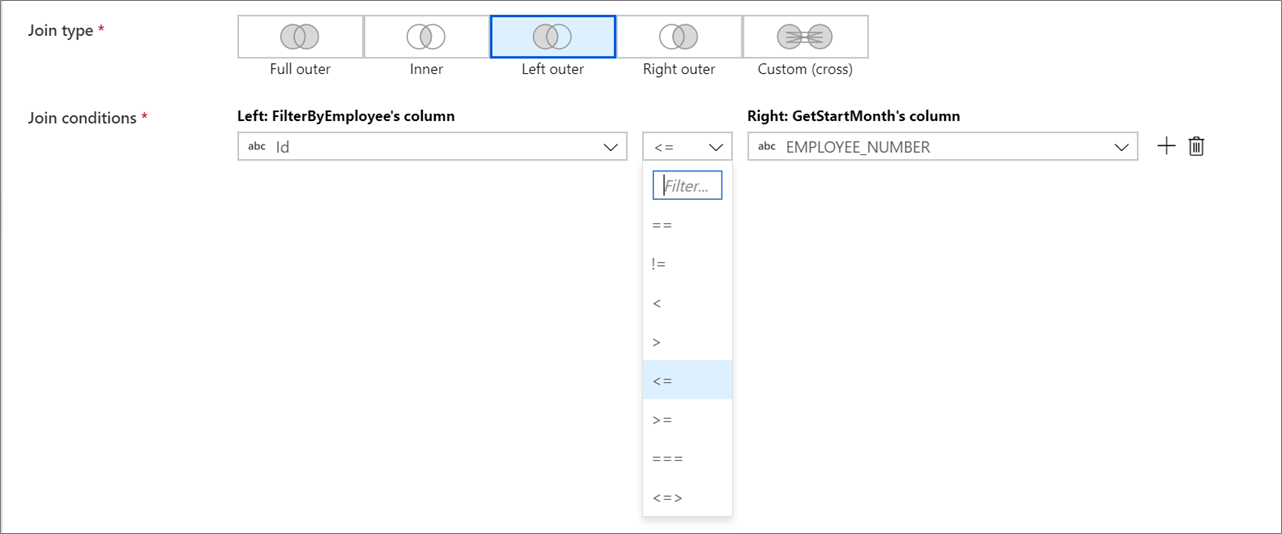
非等值联接
若要在联接条件中使用条件运算符,例如不等于 (!=) 或大于 (>),请更改两列之间的运算符下拉菜单。 非等值联接要求使用“优化”选项卡中的“固定”广播来广播两个流中的至少一个流 。
优化联接性能
与 SSIS 等工具中的合并联接不同,联接转换不是强制性的合并联接操作。 联接键无需排序。 联接操作是在 Spark 中进行的最佳联接操作的基础上进行的,可能是广播联接或映射侧联接。
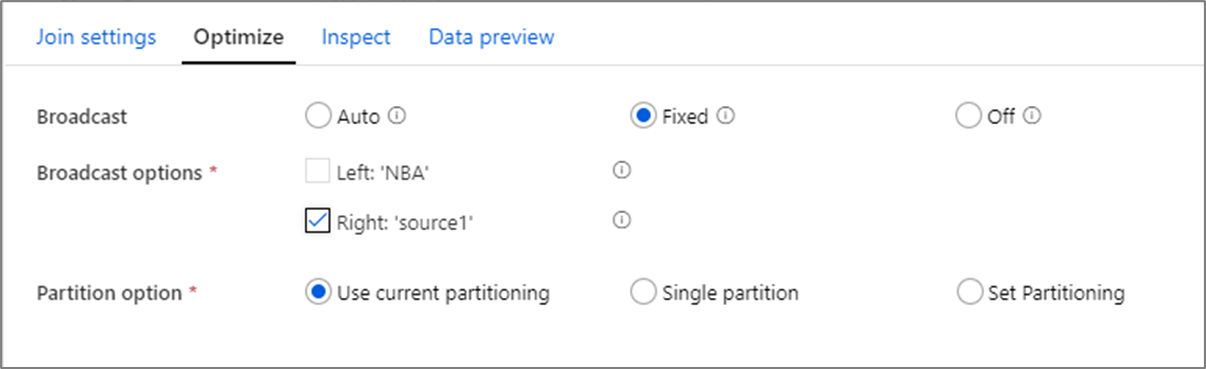
在联接、查找和存在转换中,如果工作器节点内存可容纳一个数据流或同时容纳两个数据流,则可以通过启用“广播”来优化性能。 默认情况下,Spark 引擎会自动决定是否广播一侧。 若要手动选择要广播的一侧,请选择“固定”。
不建议通过“关闭”选项禁用广播,除非联接遇到超时错误。
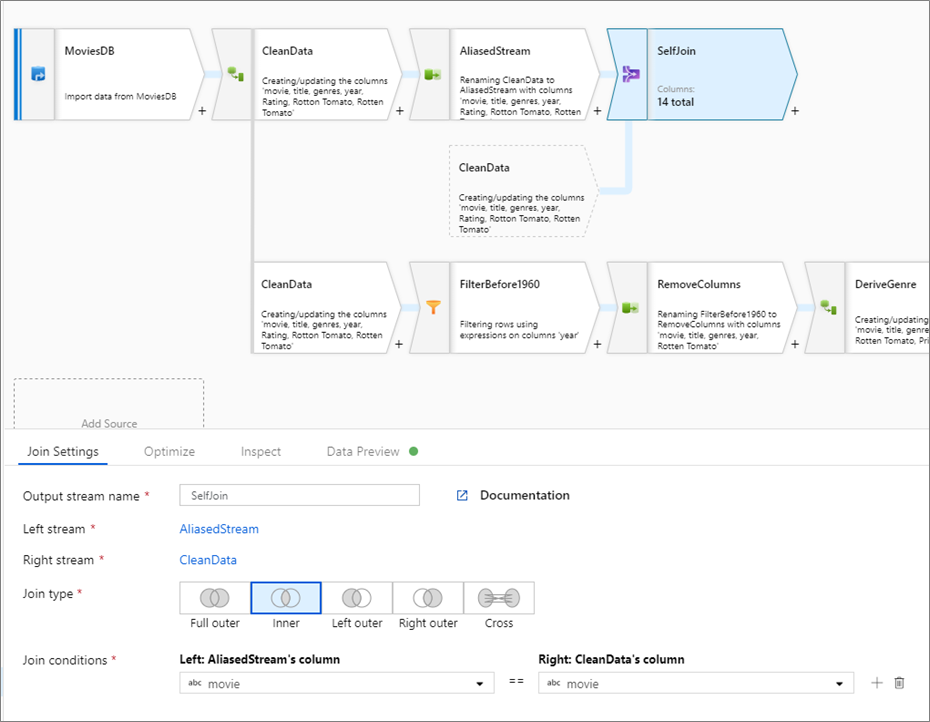
自联接
若要对数据流进行自联接,可以使用选择转换为现有流设置一个别名。 通过单击转换旁边的加号图标并选择“新建分支”,来创建新的分支。 添加选择转换,以便为原始流添加别名。 添加一个联接转换,选择原始流作为“左侧流”,选择转换结果作为“右侧流”。
测试联接条件
在调试模式下使用数据预览测试联接转换时,请使用一小部分已知数据。 从大型数据集采样行时,无法预测要读取哪些行和键进行测试。 结果是不确定的,这意味着联接条件可能不会返回任何匹配项。
数据流脚本
语法
<leftStream>, <rightStream>
join(
<conditionalExpression>,
joinType: { 'inner'> | 'outer' | 'left_outer' | 'right_outer' | 'cross' }
broadcast: { 'auto' | 'left' | 'right' | 'both' | 'off' }
) ~> <joinTransformationName>
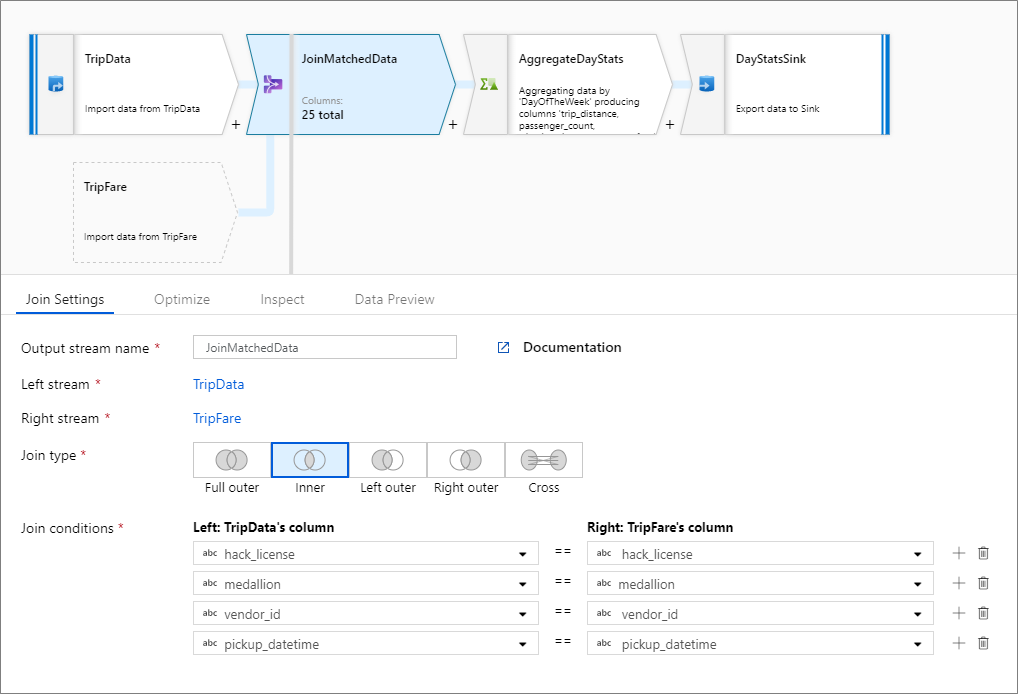
内连接示例
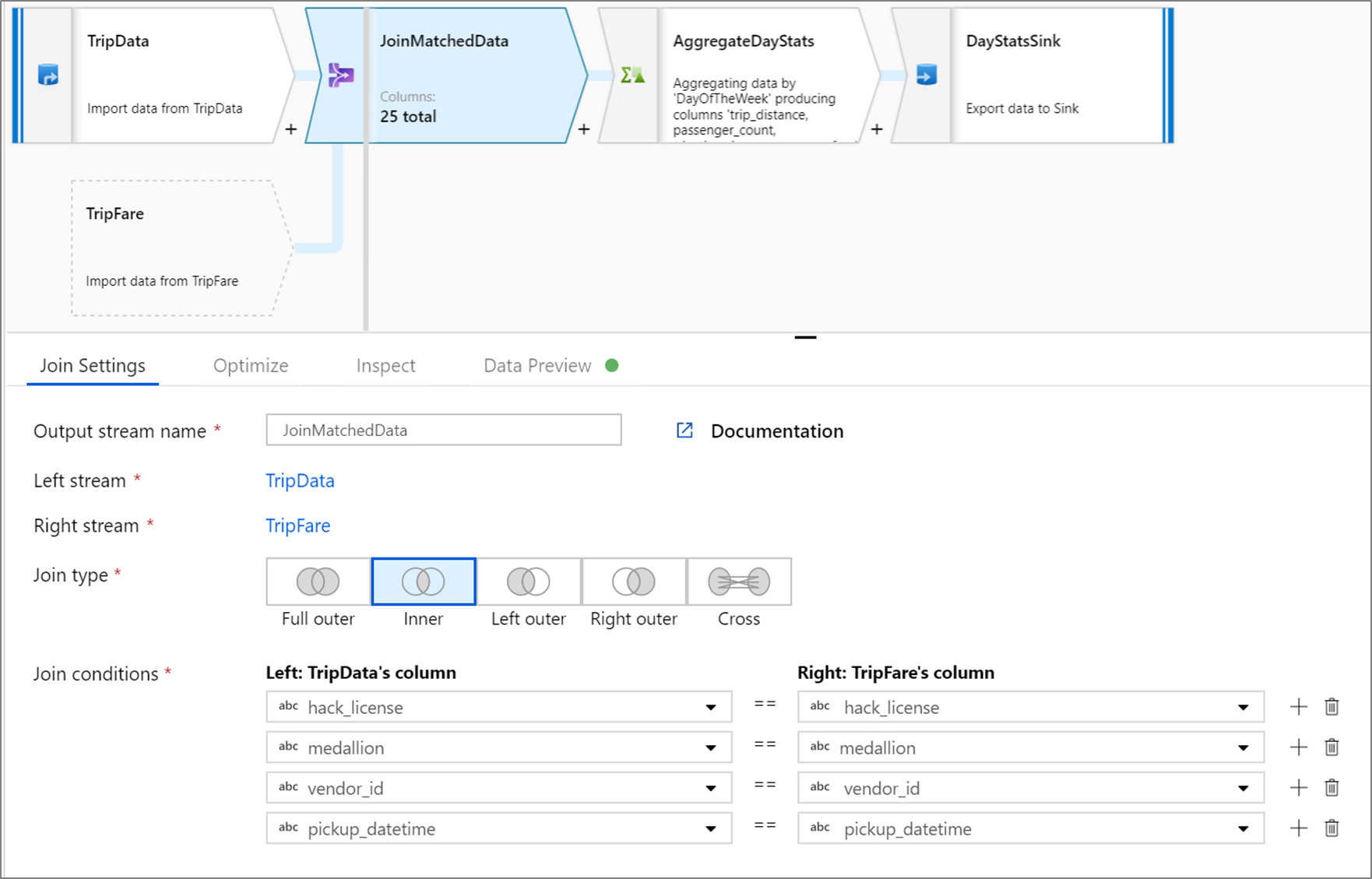
此示例是一个名为JoinMatchedData的连接转换,它处理左流TripData和右流TripFare。 联接条件为表达式 hack_license == { hack_license} && TripData@medallion == TripFare@medallion && vendor_id == { vendor_id} && pickup_datetime == { pickup_datetime},如果每个流中的 hack_license、medallion、vendor_id 和 pickup_datetime 列均匹配,则返回 true。
joinType 为 'inner'。 我们仅在左侧流中启用广播功能,因此 broadcast 的值为 'left'。
在 UI 中,此转换如下所示:
此转换的数据流脚本位于以下代码片段中:
TripData, TripFare
join(
hack_license == { hack_license}
&& TripData@medallion == TripFare@medallion
&& vendor_id == { vendor_id}
&& pickup_datetime == { pickup_datetime},
joinType:'inner',
broadcast: 'left'
)~> JoinMatchedData
自定义交叉联接示例
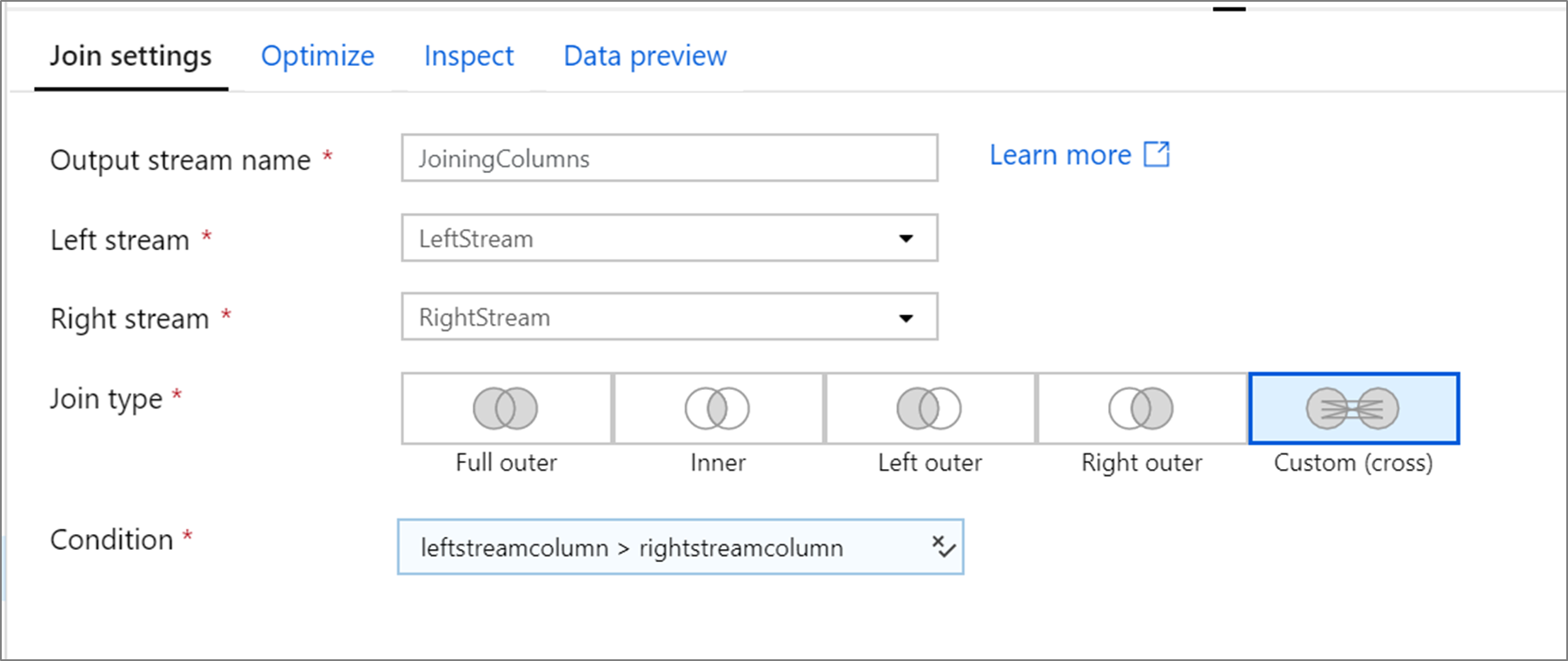
此示例是一个名为JoiningColumns的连接转换,它处理左流LeftStream和右流RightStream。 此转换接收两个流,并将 leftstreamcolumn 列大于 rightstreamcolumn 列的所有行联接在一起。
joinType 为 cross。 未启用广播 broadcast 并且存在值为 'none'。
在 UI 中,此转换如下所示:
此转换的数据流脚本位于代码片段中:
LeftStream, RightStream
join(
leftstreamcolumn > rightstreamcolumn,
joinType:'cross',
broadcast: 'none'
)~> JoiningColumns