Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
APPLIES TO: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
数据流可在Azure 数据工厂管道和Azure Synapse Analytics管道中使用。 本文适用于映射数据流。 如果你不熟悉转换,请参阅介绍性文章: 使用映射数据流转换数据。
借助排序转换,可对当前数据流上的传入行进行排序。 可以选择各个列,然后按升序或降序对其进行排序。
注意
映射数据流在跨多个节点和分区分布数据的 Spark 群集上执行。 如果选择在后续转换中重新分区数据,则由于数据重新洗牌,可能会丢失排序。 若要在数据流中维护排序顺序,最佳方法是在转换的“优化”选项卡中设置单个分区,并使排序转换尽可能接近接收器。
Configuration
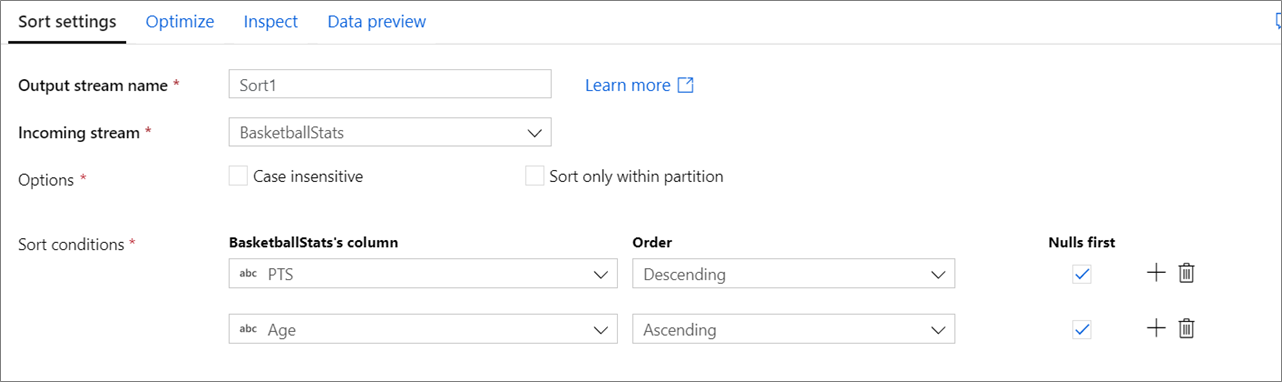
不区分大小写: 对字符串或文本字段排序时是否要忽略大小写
仅在分区中排序: 数据流在 Spark 上运行时,所有数据流都将划分为多个分区。 此设置仅对传入分区中的数据排序,不对整个数据流排序。
排序条件:选择用于排序的列,并确定排序的顺序。 顺序决定排序优先级。 选择是否在数据流的开头或末尾显示 null。
计算列
若要在排序前修改或提取列值,请将鼠标悬停在列上并选择“计算列”。 在表达式生成器中,为排序操作创建表达式,而不是使用列值。
数据流脚本
语法
<incomingStream>
sort(
desc(<sortColumn1>, { true | false }),
asc(<sortColumn2>, { true | false }),
...
) ~> <sortTransformationName<>
示例
以上排序配置的数据流脚本位于下面的代码片段中。
BasketballStats sort(desc(PTS, true),
asc(Age, true)) ~> Sort1
相关内容
排序后,可能需要使用 聚合转换