Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
适用于: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
pipeline 中的 Azure Synapse Spark 作业定义活动在 Azure Synapse Analytics 工作区中运行 Synapse Spark 作业定义。 本文基于数据转换活动一文,它概述了数据转换和受支持的转换活动。
设置 Apache Spark 作业定义画布
若要在管道中使用 Synapse 的 Spark 作业定义活动,请完成以下步骤:
常规设置
在管道的“活动”窗格中搜索“Spark 作业定义”,然后将 Synapse 下的 Spark 作业定义活动拖动到管道画布上。
如果尚未选择,请在画布上选择新的 Spark 作业定义活动。
在常规选项卡中,输入“示例”作为名称。
(选项)也可以输入说明。
超时:活动可以运行的最长时间。 默认值为 7 天,这也是允许的最长时间。 格式为 D.HH:MM:SS。
重试:最大重试尝试次数。
重试间隔:两次重试尝试之间的时间,以秒为单位。
选中“安全输出”后,活动输出将不会被日志记录捕获。
安全输入:选中后,活动的输入将不会记录到日志中。
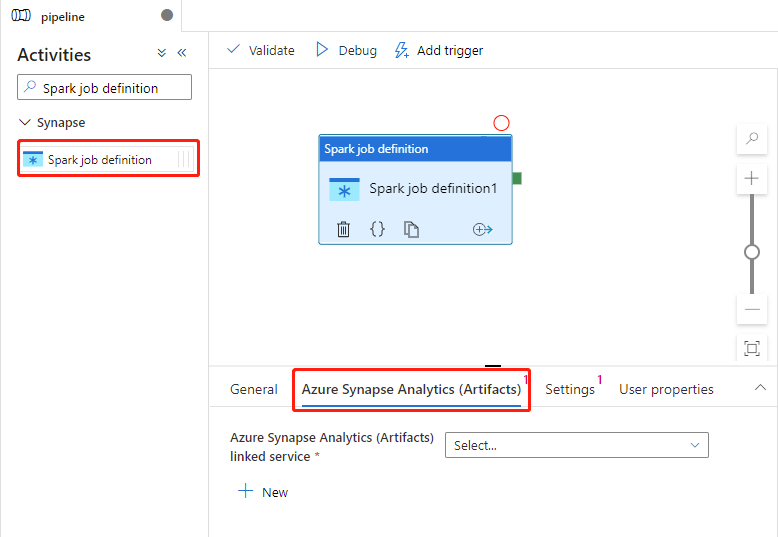
Azure Synapse Analytics(工件)设置
如果尚未选择,请在画布上选择新的 Spark 作业定义活动。
选择“Azure Synapse Analytics(Artifacts)选项卡,选择或创建将执行 Spark 作业定义活动的新Azure Synapse Analytics链接服务。
“设置”选项卡
如果尚未选择,请在画布上选择新的 Spark 作业定义活动。
选择“设置”选项卡。
展开 Spark 作业定义列表,可以在链接的Azure Synapse Analytics工作区中选择现有的 Apache Spark 作业定义。
(可选)可以填写 Apache Spark 作业定义的信息。 如果以下设置为空,将使用 Spark 作业定义本身的设置来运行;如果以下设置不为空,这些设置将替换 Spark 作业定义本身的设置。
属性 说明 主定义文件 用于作业的主文件。 从存储中选择一个 PY/JAR/ZIP 文件。 可以选择“上传文件”以将文件上传到存储帐户。
示例:abfss://…/path/to/wordcount.jar来自子文件夹的引用 从主定义文件的根文件夹中扫描子文件夹时,这些文件将被添加为引用文件。 将扫描名为“jars”、“pyFiles”、“files”或“archives”的文件夹,文件夹名称区分大小写。 主类名 主定义文件中的完全限定标识符或主类。
示例:WordCount命令行参数 可以通过单击“新建”按钮来添加命令行参数。 应当注意的是,添加命令行参数将替代由 Spark 作业定义定义的命令行参数。
示例:abfss://…/path/to/shakespeare.txtabfss://…/path/to/resultApache Spark 池 可以从列表中选择 Apache Spark 池。 Python代码参考 在主定义文件中用于引用的其他 Python 代码文件。
它支持将文件(.py、.py3、.zip)传递到“pyFiles”属性。 它将替代 Spark 作业定义中定义的“pyFiles”属性。引用文件 主定义文件中用于作为参考的附加文件。 Apache Spark 池 可以从列表中选择 Apache Spark 池。 动态分配执行器 此设置映射到用于 Spark 应用程序执行工具分配的 Spark 配置中的动态分配属性。 最小执行器数 要在作业的指定 Spark 池中分配的最小执行程序数。 最大执行程序数 要为作业在指定的 Spark 池中分配的最大执行程序数。 驱动程序大小 指定作业的 Apache Spark 池中用于驱动程序的核心数量和内存量。 Spark 配置 指定在以下主题中列出的 Spark 配置属性的值:Spark 配置 - 应用程序属性。 用户可以使用默认配置和自定义配置。 身份验证 Spark 作业定义中已支持用户分配的托管标识或系统分配的托管标识。 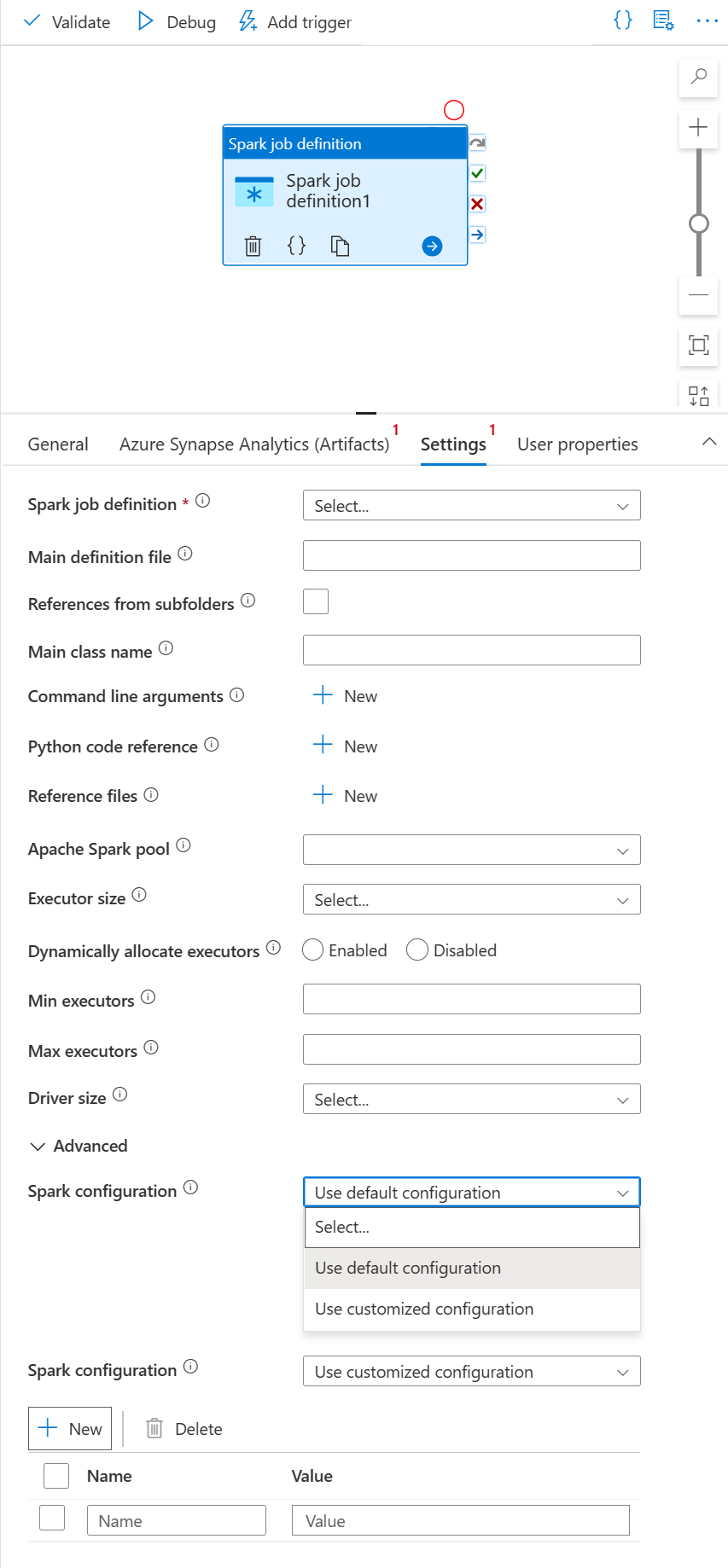
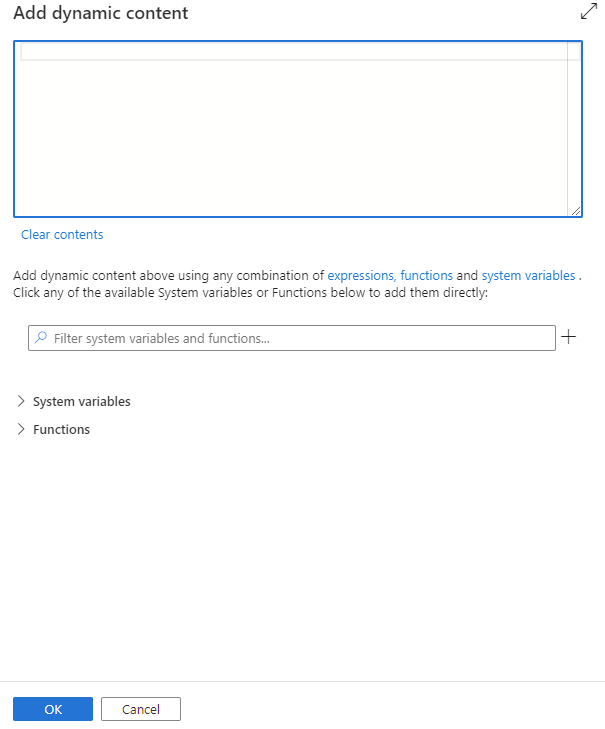
可以通过单击“添加动态内容”按钮或按快捷键 Alt++ 来添加动态内容。 在“添加动态内容”页面,可以使用表达式、函数和系统变量的任意组合来添加动态内容。
“用户属性”选项卡
可以在此面板中为 Apache Spark 作业定义活动添加属性。
Azure Synapse spark 作业定义活动定义
下面是 Azure Synapse Analytics Notebook 活动的示例 JSON 定义:
{
"activities": [
{
"name": "Spark job definition1",
"type": "SparkJob",
"dependsOn": [],
"policy": {
"timeout": "7.00:00:00",
"retry": 0,
"retryIntervalInSeconds": 30,
"secureOutput": false,
"secureInput": false
},
"typeProperties": {
"sparkJob": {
"referenceName": {
"value": "Spark job definition 1",
"type": "Expression"
},
"type": "SparkJobDefinitionReference"
}
},
"linkedServiceName": {
"referenceName": "AzureSynapseArtifacts1",
"type": "LinkedServiceReference"
}
}
],
}
Azure Synapse Spark 作业定义属性
下表描述了 JSON 定义中使用的 JSON 属性:
| 属性 | 说明 | 必需 |
|---|---|---|
| 姓名 | 管道中活动的名称。 | 是 |
| 描述 | 描述活动用途的文本。 | 否 |
| 类型 | 对于Azure Synapse spark 作业定义活动,活动类型为 SparkJob。 | 是 |
请参阅 Azure Synapse Spark 作业定义活动运行历史记录
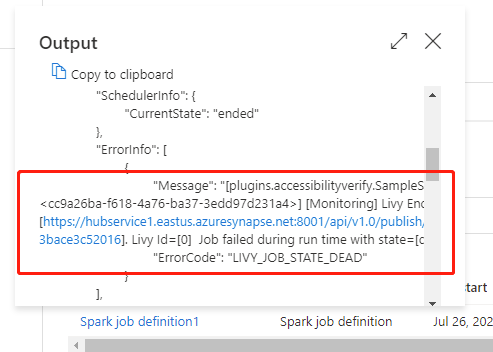
转到“监视”选项卡下的“管道运行”部分,您会看到已触发的管道。 打开包含 Azure Synapse Spark 作业定义活动的管道以查看运行历史记录。
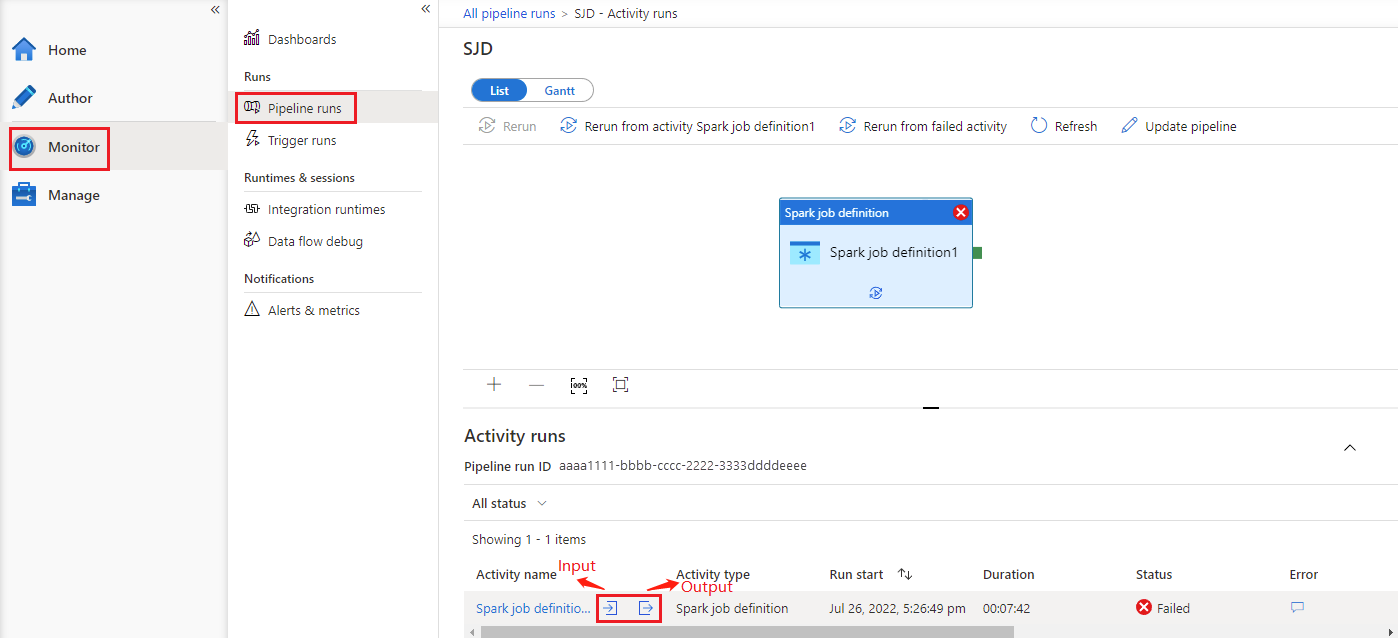
可以通过选择“输入”或“输出”按钮查看笔记本活动输入或输出。 如果管道因用户错误而失败,可以选择“输出”来检查“结果”字段,以查看详细的用户错误回溯 。