Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
若要系统地测试和改进 GenAI 应用程序,请使用评估数据集。 评估数据集是一组选定的示例输入(已标记(具有已知预期输出)或未标记(无实数答案)。 评估数据集可通过以下方式帮助你提高应用的性能:
- 通过在生产中对已知有问题的示例进行修复方案测试来提高质量。
- 防止回归。 创建一组必须始终正常工作的示例“黄金集”。
- 比较应用版本。 针对相同的数据测试不同的提示、模型或应用逻辑。
- 以特定功能为目标。 为安全、域知识或边缘案例构建专用数据集。
- 在 LLMOps 中跨不同环境验证应用。
MLflow 评估数据集存储在 Unity 目录中,该目录提供内置版本控制、世系、共享和治理。
要求
- 若要创建评估数据集,必须具有对
CREATE TABLEUnity 目录架构的权限。 - 评估数据集已连接到 MLflow 实验。 如果还没有试验,请参阅 创建 MLflow 试验 以创建一个。
评估数据集的数据源
可以使用以下任一项来创建评估数据集:
- 现有痕迹。 如果您已经从 GenAI 应用程序捕获跟踪记录,您可以使用这些记录基于真实世界场景创建评估数据集。
- 现有数据集或直接输入的示例。 此选项可用于快速原型制作或针对特定功能的定向测试。
- 综合数据。 Databricks 可以从文档自动生成具有代表性的评估集,使你能够快速评估代理并很好地涵盖测试用例。
本页介绍如何创建 MLflow 评估数据集。 还可以使用其他类型的数据集,例如 Pandas 数据帧或字典列表。 请参阅 GenAI 的 MLflow 评估示例。
使用 UI 创建数据集
按照以下步骤使用 UI 从现有跟踪创建数据集。 有关参考信息,请参阅 MLflow 评估数据集 UI。
单击边栏中的 “试验 ”以显示“试验”页。
点击您的实验名称以将其打开。
在左侧栏中,单击“ 跟踪”。
使用跟踪列表左侧的复选框选择要添加的跟踪。 若要选择当前页上的所有跟踪,请单击列标题中 跟踪 ID 旁边的复选框。
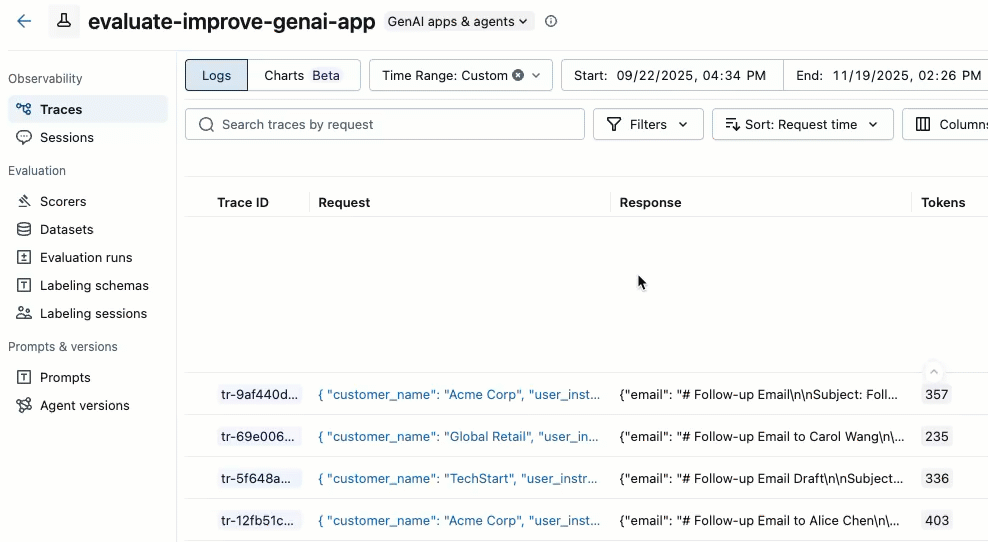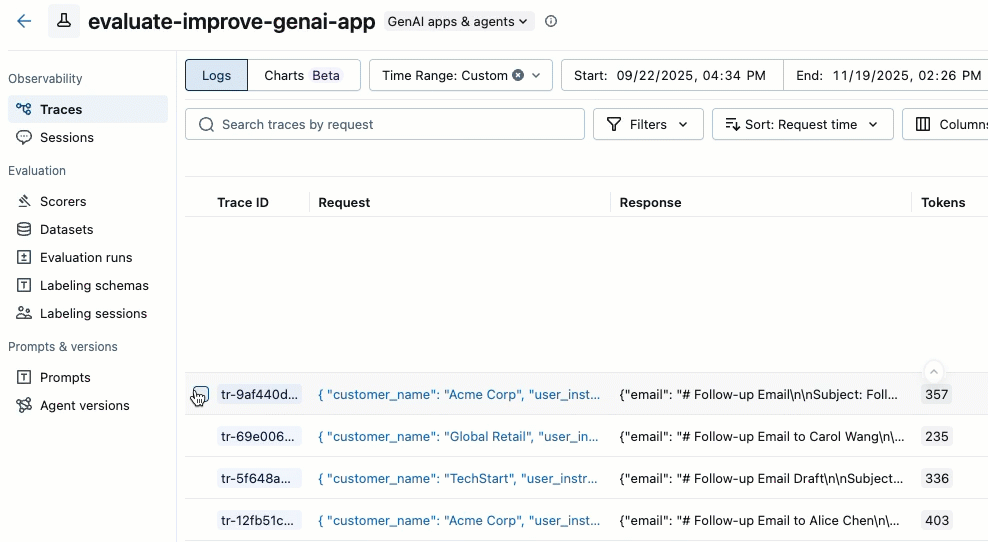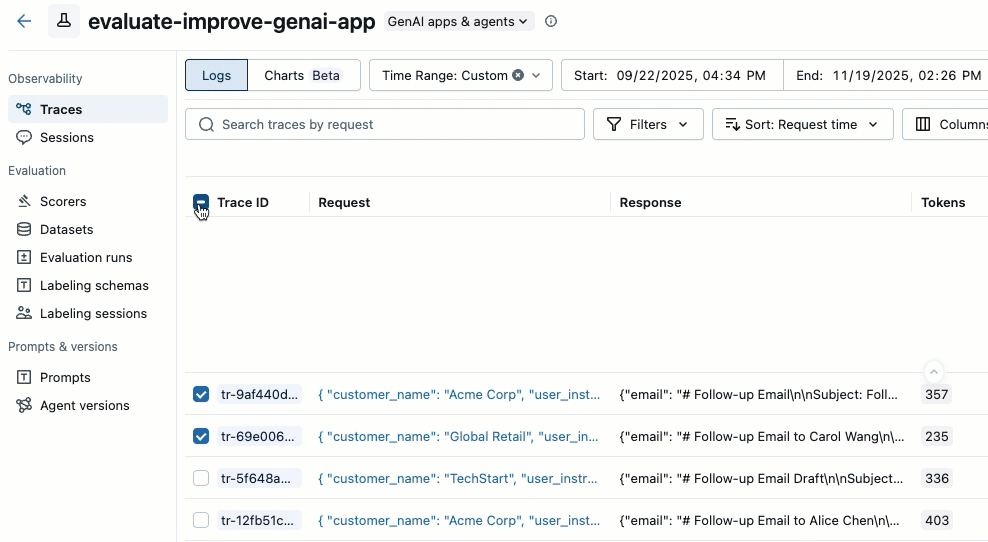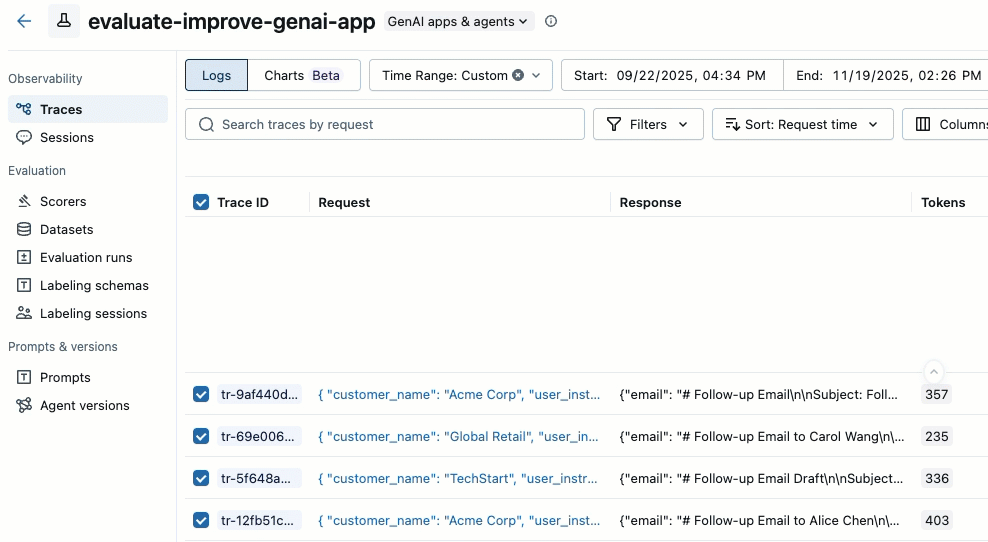
单击 操作。 按钮标签显示所选跟踪的数量,例如 Actions (3)。
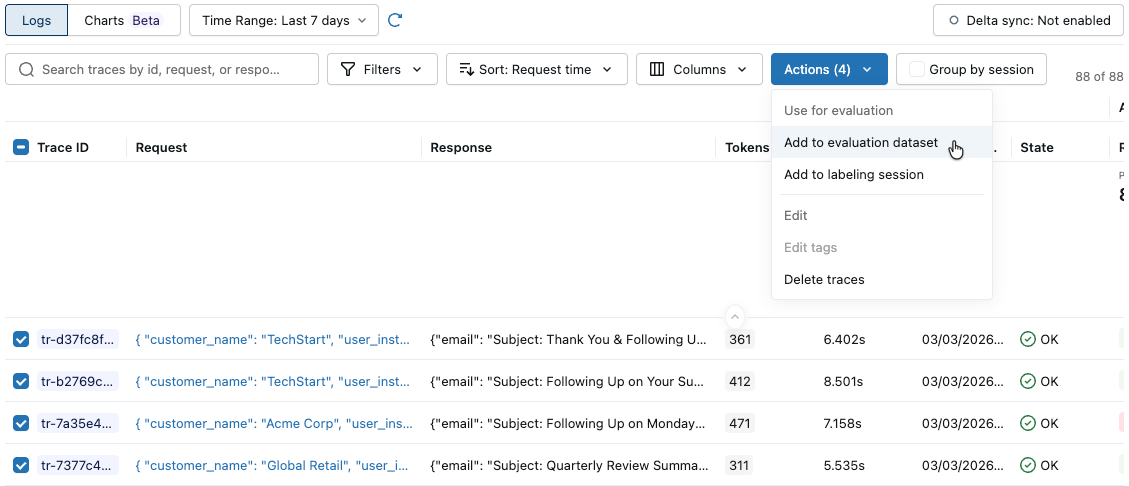
在“ 用于评估”下,选择“ 添加到评估数据集”。 此时将打开 “向评估数据集添加跟踪 ”对话框。
如果此试验不存在评估数据集,或者想要向新数据集添加跟踪,请按照以下步骤创建新的评估数据集:
- 单击“ 创建新数据集”。
- 选择 Unity 目录架构以保存新数据集。
- 输入数据集的名称,然后单击“ 创建数据集”。
- 单击“ 导出 ”,然后单击“ 完成”。
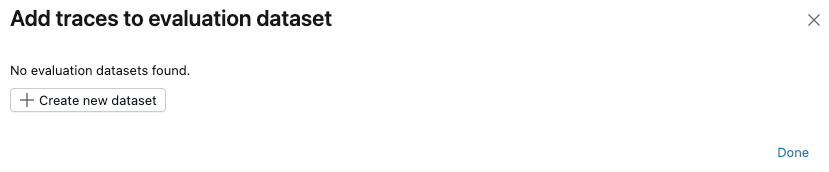
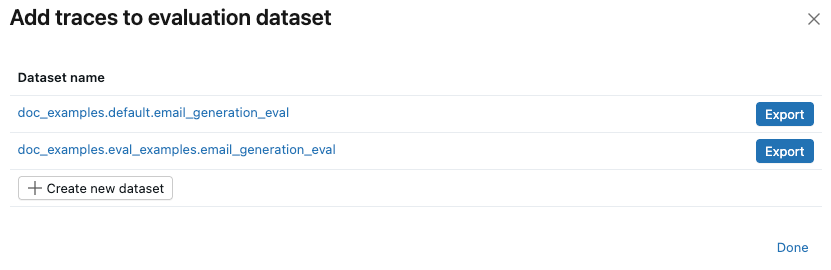
如果试验已存在评估数据集,请单击要向其添加跟踪的数据集右侧的 “导出 ”。 可以导出到多个数据集。 导出完成后,单击“ 完成”。
使用 SDK 创建数据集
按照以下步骤使用 SDK 创建数据集。 有关参考信息,请参阅 评估数据集参考。
步骤 1. 创建数据集
import mlflow
import mlflow.genai.datasets
import time
from databricks.connect import DatabricksSession
# 0. If you are using a local development environment, connect to Serverless Spark which powers MLflow's evaluation dataset service
spark = DatabricksSession.builder.remote(serverless=True).getOrCreate()
# 1. Create an evaluation dataset
# Replace with a Unity Catalog schema where you have CREATE TABLE permission
uc_schema = "workspace.default"
# This table will be created in the above UC schema
evaluation_dataset_table_name = "email_generation_eval"
eval_dataset = mlflow.genai.datasets.create_dataset(
name=f"{uc_schema}.{evaluation_dataset_table_name}",
)
print(f"Created evaluation dataset: {uc_schema}.{evaluation_dataset_table_name}")
步骤 2:将记录添加到数据集
本部分介绍向评估数据集添加记录的多个选项。
从现有痕迹
构建相关评估数据集的最有效方法之一是直接从 MLflow 跟踪捕获的应用程序的历史交互中挑选示例。 您可以使用 MLflow 监控 UI 或 SDK 从跟踪创建数据集。
以编程方式搜索跟踪,然后使用 search_traces() 将其添加到数据集。 使用筛选器通过成功、失败、生产环境中使用或其他属性来识别跟踪。 以 编程方式查看搜索跟踪。
import mlflow
# 2. Search for traces
traces = mlflow.search_traces(
filter_string="attributes.status = 'OK'",
order_by=["attributes.timestamp_ms DESC"],
tags.environment = 'production',
max_results=10
)
print(f"Found {len(traces)} successful traces")
# 3. Add the traces to the evaluation dataset
eval_dataset = eval_dataset.merge_records(traces)
print(f"Added {len(traces)} records to evaluation dataset")
# Preview the dataset
df = eval_dataset.to_df()
print(f"\nDataset preview:")
print(f"Total records: {len(df)}")
print("\nSample record:")
sample = df.iloc[0]
print(f"Inputs: {sample['inputs']}")
选择用于评估数据集的痕迹
在将跟踪添加到数据集之前,请确定哪些跟踪表示评估需求的重要测试用例。 可以使用定量分析和定性分析来挑选具有代表性的轨迹。
定量跟踪选择
使用 MLflow UI 或 SDK 根据可度量的特征筛选和分析跟踪:
-
在 MLflow UI 中:按标记(例如,)
tag.quality_score < 0.7筛选,搜索特定输入/输出,按延迟或令牌使用情况排序 - 以编程方式:查询跟踪以执行高级分析
import mlflow
import pandas as pd
# Search for traces with potential quality issues
traces_df = mlflow.search_traces(
filter_string="tag.quality_score < 0.7",
max_results=100
)
# Analyze patterns
# For example, check if quality issues correlate with token usage
correlation = traces_df["span.attributes.usage.total_tokens"].corr(traces_df["tag.quality_score"])
print(f"Correlation between token usage and quality: {correlation}")
有关完整的跟踪查询语法和示例,请参阅 以编程方式搜索跟踪。
定性跟踪选择
检查单个日志跟踪以识别需要人工判断的模式:
- 检查导致低质量输出的输入
- 查找应用程序如何处理边缘事例的模式
- 识别缺少的上下文或错误推理
- 比较高质量跟踪与低质量跟踪,以了解差异因素
确定具有代表性的跟踪后,使用上述搜索和合并方法将其添加到数据集。
小窍门
使用预期结果或质量指标扩充跟踪信息,以便进行基准比较。 请参阅 收集域专家反馈 以添加人工标签。
来自领域专家的标签
利用从 MLflow 标记会话中获得的域专家反馈,用真实标签丰富您的评估数据集。 在执行这些步骤之前,请按照 收集域专家反馈 指南创建标记会话。
import mlflow.genai.labeling as labeling
# Get a labeling sessions
all_sessions = labeling.get_labeling_sessions()
print(f"Found {len(all_sessions)} sessions")
for session in all_sessions:
print(f"- {session.name} (ID: {session.labeling_session_id})")
print(f" Assigned users: {session.assigned_users}")
# Sync from the labeling session to the dataset
all_sessions[0].sync(dataset_name=f"{uc_schema}.{evaluation_dataset_table_name}")
小窍门
收集专家反馈后,你可以使评委与人工反馈相匹配。 请参阅 与人类对齐的评委。
从头开始构建或导入现有
可以导入现有数据集或从头开始策划示例。 数据必须匹配(或转换以匹配) 评估数据集架构。
# Define comprehensive test cases
evaluation_examples = [
{
"inputs": {"question": "What is MLflow?"},
"expected": {
"expected_response": "MLflow is the largest open source AI engineering platform for agents, LLMs, and ML models.",
"expected_facts": [
"open source AI engineering platform",
"agents, LLMs, and ML models",
"experiment tracking",
"model deployment"
]
},
},
]
eval_dataset = eval_dataset.merge_records(evaluation_examples)
使用合成数据进行初始化
生成综合数据可以通过快速创建各种输入并覆盖边缘事例来扩展测试工作。
用于对话模拟
若要启用可重现的多轮次测试,请使用类似于下面的代码来存储用于聊天模拟的测试用例。 有关模拟多轮对话的完整文档,请参阅 对话模拟。
from mlflow.genai.datasets import create_dataset, get_dataset
from mlflow.genai.simulators import ConversationSimulator
# Create a dataset for simulation test cases
dataset = create_dataset(
name="conversation_scenarios",
tags={"type": "simulation", "agent": "support-bot"},
)
# Define test cases with goals and personas
simulation_test_cases = [
{
"inputs": {
"goal": "Get help setting up experiment tracking",
"persona": "You are a data scientist new to MLflow",
},
},
{
"inputs": {
"goal": "Debug a model deployment error",
"persona": "You are a senior engineer who expects precise answers",
},
},
{
"inputs": {
"goal": "Understand model versioning best practices",
"persona": "You are building an ML platform for your team",
"context": {"team_size": "large", "compliance": "strict"},
},
},
]
dataset.merge_records(simulation_test_cases)
# Later, use the dataset with ConversationSimulator
dataset = get_dataset(name="conversation_scenarios")
simulator = ConversationSimulator(test_cases=dataset)
更新现有数据集
可以使用 UI 或 SDK 更新评估数据集。
Databricks 用户界面
使用 UI 将记录添加到现有评估数据集。
在 Databricks 工作区中打开数据集页:
- 在 Databricks 工作区中,进入实验。
- 在左侧边栏中,单击 “数据集”。
- 单击列表中的数据集的名称。
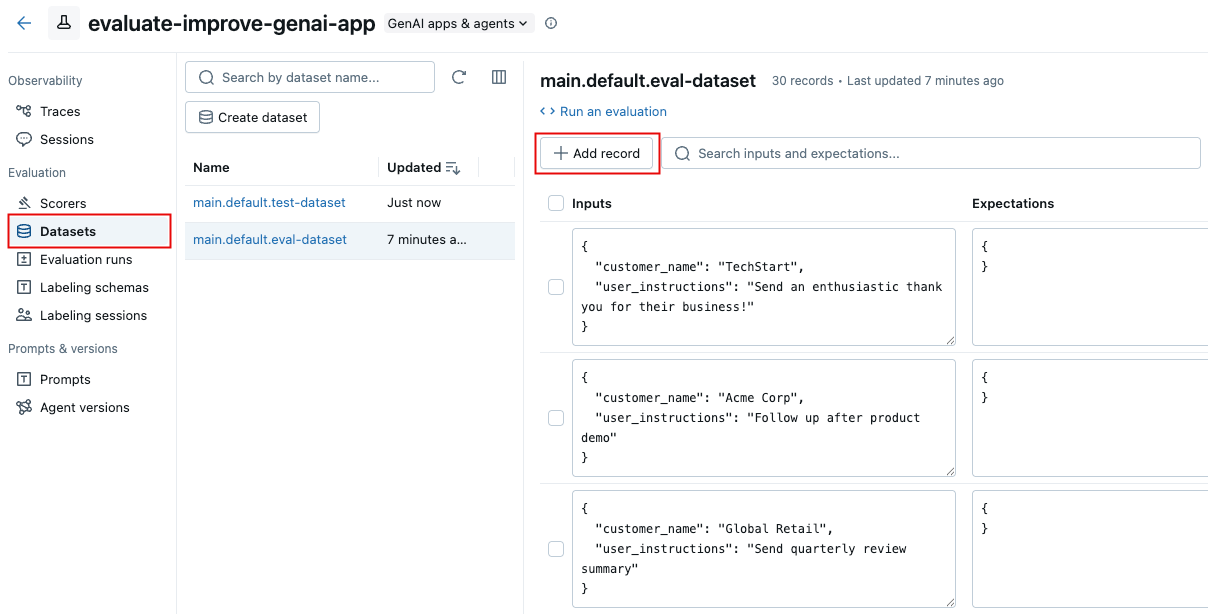
单击“ 添加记录”。 此时会显示一个新行,其中包含泛型内容。
直接编辑新行以输入新记录的输入和期望值。 (可选)为新记录设置任何标签。
单击“保存更改”。
MLflow SDK
使用 MLflow SDK 更新和现有评估数据集:
import mlflow.genai.datasets
import pandas as pd
# Load existing dataset
dataset = mlflow.genai.datasets.get_dataset(name="catalog.schema.eval_dataset")
# Add new test cases
new_cases = [
{
"inputs": {"question": "What are MLflow models?"},
"expectations": {
"expected_facts": ["model packaging", "deployment", "registry"],
"min_response_length": 100
}
}
]
# Merge new cases
dataset = dataset.merge_records(new_cases)
局限性
- 不支持客户管理的密钥(CMK)。
- 每个评估数据集最多 2000 行。
- 每个数据集记录最多 20 个预期。
如果需要为用例放宽上述任何限制,请联系 Databricks 代表。
后续步骤
- 评估应用 - 使用新创建的数据集进行评估
- 创建自定义法官 - 生成自定义 LLM 法官以评估应用程序输出
- 使评委与反馈保持一致 - 通过使评委与专家反馈保持一致来持续改进评估
- 通过 SDK 查询跟踪 - 用于数据集选择的高级程序化跟踪分析