Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
本页演示如何在 Databricks 上部署 GenAI 应用程序,以便自动捕获生产跟踪。
有关在 Databricks 外部部署的应用,请参阅 Databricks 外部部署的跟踪代理。
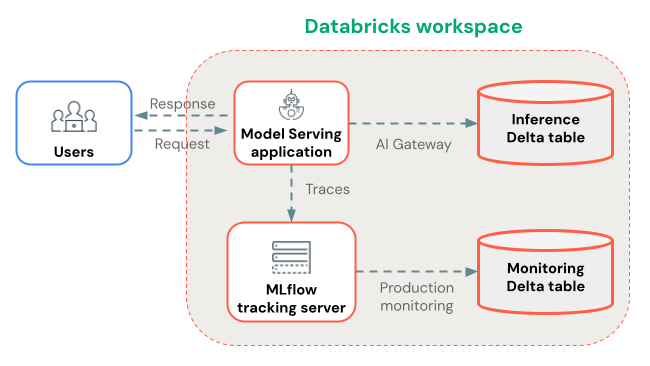
使用代理框架进行部署(建议)
设置跟踪数据的存储位置:
接下来,在 Python 笔记本中,使用 MLflow 跟踪检测代理,并使用 Agent Framework 部署代理:
在 Python 环境中安装最新版本
mlflow[databricks]。使用
mlflow.set_experiment(...)连接到 MLflow 实验。使用 MLflow
ResponsesAgent包装代理代码。 在代理代码中,使用 自动 或 手动 工具启用 MLflow 追踪。将代理记录为 MLflow 模型,并将其注册到 Unity 目录。
确保
mlflow位于模型的 Python 依赖项中,其包版本与笔记本环境中所用的包版本相同。用于
agents.deploy(...)将 Unity 目录模型(代理)部署到模型服务终结点。
注释
如果要从存储在 Databricks Git 文件夹中的笔记本部署代理,则默认情况下,MLflow 3 实时跟踪不起作用。
若要启用实时跟踪,请先将试验设置为非 Git 关联的试验 mlflow.set_experiment() ,然后再运行 agents.deploy()。
此笔记本演示上述部署步骤。
代理框架与 MLflow 追踪笔记本
使用自定义 CPU 服务进行部署(替代)
如果无法使用代理框架,请改用自定义 CPU 模型服务部署代理。
首先,为跟踪设置存储位置:
接下来,在 Python 笔记本中,使用 MLflow 跟踪检测代理,并使用模型服务 UI 或 API 来部署代理:
将模型部署到 CPU 服务环境。
预配具有 MLflow 试验访问权限的服务主体或个人访问令牌(PAT
CAN_EDIT)。在 CPU 服务终结点页中,转到“编辑终结点”。对于要跟踪的每个已部署模型,请添加以下环境变量:
ENABLE_MLFLOW_TRACING=trueMLFLOW_EXPERIMENT_ID=<ID of the experiment you created>如果预配了服务主体,请设置
DATABRICKS_CLIENT_ID和DATABRICKS_CLIENT_SECRET。 如果预配了 PAT,请设置DATABRICKS_HOST和DATABRICKS_TOKEN。
跟踪数据存储
Databricks 会在部署过程中将跟踪记录到由 mlflow.set_experiment(...) 设置的 MLflow 实验中。 追踪可实时在 MLflow UI 中查看。
跟踪被存储为工件,您可以指定自定义存储位置。 例如,如果您创建一个工作区实验并将artifact_location设置为 Unity Catalog 卷,那么数据访问的跟踪将受到Unity Catalog 卷权限的管理。
使用生产监控长期存储跟踪数据
将跟踪记录到 MLflow 试验后,可以选择使用 生产监控 (beta 版)将其长久存储在 Delta 表中。
生产监控在跟踪存储中的优点:
- 持久存储:在 Delta 表中存储跟踪,以便在 MLflow 试验项目生命周期之外长期保留。
- 无跟踪大小限制:与备用存储方法不同,生产监视处理任何大小的跟踪。
- 自动化质量评估:在生产跟踪上运行 MLflow 评分程序以持续监视应用程序质量。
- 快速同步:跟踪大约每 15 分钟同步到 Delta 表。
后续步骤
- 在 Databricks MLflow UI 中查看跟踪 - 在 MLflow UI 中查看跟踪。
- 生产监控 - 在 Delta 表中存储跟踪数据以实现长期保留,然后使用评分工具自动进行评估。
- 将上下文添加到跟踪 - 附加用于请求跟踪、用户会话和环境数据的元数据。