Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
提取、转换和加载 (ETL) 是从各种来源获取数据的过程。 在标准位置收集、清理和处理数据。 最终,数据将加载到可以查询它的数据存储中。 传统的 ETL 过程是导入数据、就地清理该数据,然后将其存储在关系数据引擎中。 使用 Azure HDInsight 时,各种 Apache Hadoop 环境组件都支持大规模 ETL。
在 ETL 过程中使用 HDInsight 通过以下管道来总结:
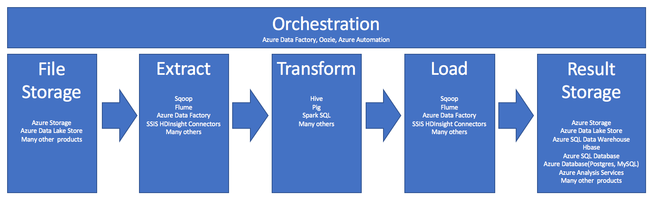
以下部分探讨每个 ETL 阶段及其关联的组件。
业务流程
业务流程跨越 ETL 管道的所有阶段。 HDInsight 中的 ETL 作业通常涉及到多个相互配合运行的不同产品。 例如:
- 可使用 Apache Hive 来清理部分数据,使用 Apache Pig 来清理另一部分数据。
- 可以使用 Azure 数据工厂将数据从 Azure Data Lake Store 载入 Azure SQL 数据库。
若要在适当的时间运行适当的作业,则需要业务流程。
Apache Oozie
Apache Oozie 是一个管理 Hadoop 作业的工作流协调系统。 Oozie 在 HDInsight 群集中运行,并与 Hadoop 堆栈集成。 Oozie 支持对 Apache Hadoop MapReduce、Pig、Hive 和 Sqoop 执行 Hadoop 作业。 可以使用 Oozie 来计划特定于某系统的作业,例如 Java 程序或 shell 脚本。
有关详细信息,请参阅在 HDInsight 中将 Apache Oozie 与 Apache Hadoop 配合使用以定义和运行工作流。 另请参阅操作数据管道。
Azure 数据工厂
Azure 数据工厂以平台即服务 (PaaS) 的形式提供业务流程功能。 Azure 数据工厂是基于云的数据集成服务。 它可让你创建数据驱动的工作流,用于协调和自动化数据移动和数据转换。
使用 Azure 数据工厂可以:
- 创建和安排数据驱动的工作流。 通过这些管道从不同的数据存储引入数据。
- 使用计算服务(如 HDInsight 或 Hadoop)处理和转换数据。 对于此步骤,还可使用 Spark、Azure Data Lake Analytics、Azure Batch 或 Azure 机器学习。
- 将输出数据发布到数据存储(例如 Azure Synapse Analytics),供 BI 应用程序使用。
有关 Azure 数据工厂的详细信息,请参阅文档。
提取文件存储和结果存储
源数据文件通常加载到 Azure 存储或 Azure Data Lake Storage 中的某个位置。 这些文件通常采用平面格式,如 CSV。 但它们可以采用任何格式。
Azure 存储
Azure 存储具有特定的自适应性目标。 请参阅 Blob 存储的可伸缩性和性能目标获取详细信息。 对于大多数分析节点而言,在处理许多较小的文件时,Azure 存储的可伸缩性最佳。 只要在帐户限制范围内,无论文件大小如何,Azure 存储都可保证提供相同的性能。 你可以存储 TB 级的数据,并且仍然可以获得一致的性能。 无论你使用的是子集还是所有数据,效果都一样。
Azure 存储包含多种类型的 Blob。 “追加 Blob”是存储 Web 日志或传感器数据的极佳选项。
多个 Blob 可以分布在多个服务器上,以横向扩展对它们的访问。 但是,单个 Blob 仅由单个服务器提供服务。 虽然 Blob 可在 Blob 容器中进行逻辑分组,但这种分组不会对分区产生影响。
Azure 存储为 Blob 存储提供了一个 WebHDFS API 层。 所有 HDInsight 服务都可以访问 Azure Blob 存储中的文件,以便进行数据清理和数据处理。 这类似于这些服务使用 Hadoop 分布式文件系统 (HDFS) 的方式。
数据通常通过 PowerShell、Azure 存储 SDK 或 AzCopy 引入到 Azure 存储中。
Azure Data Lake Storage
Azure Data Lake Storage 是一个托管的超大规模存储库,用于分析数据。 它与 HDFS 兼容并使用类似于 HDFS 的设计范例。 Data Lake Storage 为总容量和单个文件的大小提供无限制的适应性。 它非常适合与大型文件配合运行,因为大型文件可以跨多个节点存储。 Data Lake Storage 中的数据分区在后台执行。 通过数以千计的并发执行程序,可高效读取和写入数百 TB 的数据,从而可获得极大的吞吐量来运行分析作业。
数据通常通过 Azure 数据工厂引入到 Data Lake Storage 中。 你还可以使用 Data Lake Storage SDK、AdlCopy 服务、Apache DistCp 或 Apache Sqoop。 所选的服务取决于数据的位置。 如果数据位于现有的 Hadoop 群集中,则可以使用 Apache DistCp、AdlCopy 服务或 Azure 数据工厂。 对于 Azure Blob 存储中的数据,则可以使用 Azure Data Lake Storage .NET SDK、Azure PowerShell 或 Azure 数据工厂。
Data Lake Storage 已针对通过 Azure 事件中心的事件引入进行了优化。
两种存储选项的注意事项
如果上传的数据集达到 TB 量级,网络延迟可能是一个重要问题。 如果数据来自本地位置,则更是如此。 这种情况下,可使用以下选项:
Azure ExpressRoute: 在 Azure 数据中心与本地基础结构之间创建专用连接。 这些连接为传输大量数据提供了可靠选项。 有关详细信息,请参阅 Azure ExpressRoute 文档。
从硬盘驱动器上传数据: 可以使用 Azure 导入/导出服务将包含数据的硬盘驱动器发送到 Azure 数据中心。 数据会首先上传到 Azure Blob 存储。 然后可使用 Azure 数据工厂或 AdlCopy 工具从 Azure Blob 存储将数据复制到 Data Lake Storage。
Azure Synapse Analytics
Azure Synapse Analytics 是存储准备好的结果的合适选择。 可以使用 Azure HDInsight 为 Azure Synapse Analytics 执行这些服务。
Azure Synapse Analytics 是已针对分析工作负荷进行优化的关系数据库存储。 它根据分区表进行缩放。 表可以跨多个节点分区。 在创建节点时便选择了节点。 可以在事后缩放节点,但是,该主动过程可能需要移动数据。 有关详细信息,请参阅管理 Azure Synapse Analytics 中的计算资源。
Apache HBase
Apache HBase 是 Azure HDInsight 中提供的键/值存储。 它是一种开放源代码 NoSQL 数据库,构建于 Hadoop 基础之上,并基于 Google BigTable 模型化。 HBase 针对大量非结构化和结构化数据提供高性能随机访问和强一致性。
由于 HBase 是一个无架构数据库,因此在使用列和数据类型之前,不需要定义它们。 数据存储在表的各行中,按列系列分组。
开放源代码可进行线性伸缩,以处理上千节点上数 PB 的数据。 HBase 依赖 Hadoop 环境中的分布式应用程序提供的数据冗余、批处理以及其他功能。
HBase 是供将来分析的传感器和日志数据的绝佳目标。
HBase 自适应性取决于 HDInsight 群集中的节点数。
Azure SQL 数据库
Azure 提供三个 PaaS 关系数据库:
- Azure SQL 数据库是 Microsoft SQL Server 的一种实现。 有关性能的详细信息,请参阅优化 Azure SQL 数据库性能。
- Azure Database for MySQL 是 Oracle MySQL 的一种实现。
- Azure Database for PostgreSQL 是 PostgreSQL 的一种实现。
添加更多 CPU 和内存以横向扩展这些产品。 还可以选择使用高级磁盘配合这些产品来获得更好的 I/O 性能。
Azure Analysis Services
Azure Analysis Services 是用于决策支持和业务分析的分析数据引擎。 它为业务报表和客户端应用程序(如 Power BI)提供分析数据。 分析数据还可用于 Excel、SQL Server Reporting Services 报表和其他数据可视化工具。
可通过更改每个多维数据集的层来缩放这些分析多维数据集。 有关详细信息,请参阅 Azure Analysis Services 定价。
提取和加载
将数据存储到 Azure 中后,可以使用许多服务将这些数据提取和加载到其他产品。 HDInsight 支持 Sqoop 和 Flume。
Apache Sqoop
Apache Sqoop 是专用于在结构化、半结构化和非结构化数据源之间有效传输数据的工具。
Sqoop 使用 MapReduce 导入和导出数据,可提供并行操作和容错。
Apache Flume
Apache Flume 是分布式、可靠且高度可用的服务,能够有效地收集、聚合与移动大量日志数据。 它灵活的体系结构基于流式传输数据流。 Flume 既可靠又能容错,提供可优化的可靠性机制。 还具有许多故障转移和恢复机制。 Flume 使用一个允许联机分析应用程序的简单可扩展数据模型。
Apache Flume 无法与 Azure HDInsight 配合使用。 但是,本地 Hadoop 安装可以使用 Flume 将数据发送到 Azure Blob 存储或 Azure Data Lake Storage。 有关详细信息,请参阅将 Apache Flume 与 HDInsight 配合使用。
转换
将数据存储到所选的位置后,需要根据特定的使用模式清理、合并或准备这些数据。 Hive、Pig 和 Spark SQL 都是适合用于完成此类任务的极佳选择。 HDInsight 支持所有这些产品。