Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
本教程说明如何使用 Apache Spark 结构化流式处理和 Apache Kafka on Azure HDInsight 来读取和写入数据。
Spark 结构化流式处理是建立在 Spark SQL 上的流处理引擎。 这允许以与批量计算相同的方式表达针对静态数据的流式计算。
本教程介绍如何执行下列操作:
- 使用 Azure 资源管理器模板创建群集
- 将 Spark 结构化流式处理与 Kafka 配合使用
完成本文档中的步骤后,请记得删除这些群集,以免产生额外的费用。
先决条件
jq,一个命令行 JSON 处理程序。 请参阅 https://stedolan.github.io/jq/。
熟悉 Jupyter Notebook 和 Spark on HDInsight 的结合使用。 有关详细信息,请参阅使用 Apache Spark on HDInsight 加载数据并运行查询文档。
熟悉 Scala 编程语言。 本教程所使用的代码是使用 Scala 编写的。
熟悉 Kafka 主题的创建。 有关详细信息,请参阅 Apache Kafka on HDInsight 快速入门文档。
重要
本文档中的步骤需要一个包含 Spark on HDInsight 和 Kafka on HDInsight 群集的 Azure 资源组。 这些群集都位于一个 Azure 虚拟网络中,这样 Spark 群集便可与 Kafka 群集直接通信。
为方便起见,本文档链接到了一个模板,该模板可创建所有所需 Azure 资源。
有关在虚拟网络中使用 HDInsight 的详细信息,请参阅为 HDInsight 规划虚拟网络文档。
将结构化流式处理与 Apache Kafka 配合使用
Spark 结构化流式处理是建立在 Spark SQL 引擎上的流处理引擎。 使用结构化流式处理时,可以使用与编写批处理查询相同的方式来编写流式处理查询。
以下代码片段演示了从 Kafka 读取数据并存储到文件。 第一个为批处理操作,而第二个为流式处理操作:
// Read a batch from Kafka
val kafkaDF = spark.read.format("kafka")
.option("kafka.bootstrap.servers", kafkaBrokers)
.option("subscribe", kafkaTopic)
.option("startingOffsets", "earliest")
.load()
// Select data and write to file
kafkaDF.select(from_json(col("value").cast("string"), schema) as "trip")
.write
.format("parquet")
.option("path","/example/batchtripdata")
.option("checkpointLocation", "/batchcheckpoint")
.save()
// Stream from Kafka
val kafkaStreamDF = spark.readStream.format("kafka")
.option("kafka.bootstrap.servers", kafkaBrokers)
.option("subscribe", kafkaTopic)
.option("startingOffsets", "earliest")
.load()
// Select data from the stream and write to file
kafkaStreamDF.select(from_json(col("value").cast("string"), schema) as "trip")
.writeStream
.format("parquet")
.option("path","/example/streamingtripdata")
.option("checkpointLocation", "/streamcheckpoint")
.start.awaitTermination(30000)
在这两个代码片段中,从 Kafka 读取数据并写入文件。 示例之间的区别如下:
| 批处理 | 流式处理 |
|---|---|
read |
readStream |
write |
writeStream |
save |
start |
流式处理操作还使用 awaitTermination(30000),这会在 30,000 毫秒后停止流。
若要将结构化流式处理与 Kafka 配合使用,项目必须具有针对 org.apache.spark : spark-sql-kafka-0-10_2.11 包的依赖项。 此包的版本应与 Spark on HDInsight 的版本相匹配。 对于 Spark 2.4(在 HDInsight 4.0 中可用),可以在 https://search.maven.org/#artifactdetails%7Corg.apache.spark%7Cspark-sql-kafka-0-10_2.11%7C2.2.0%7Cjar 中找到各种项目类型的依赖项信息。
对于在本教程中使用的 Jupyter Notebook,以下单元格会加载此包依赖项:
%%configure -f
{
"conf": {
"spark.jars.packages": "org.apache.spark:spark-sql-kafka-0-10_2.11:2.2.0",
"spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.11"
}
}
创建群集
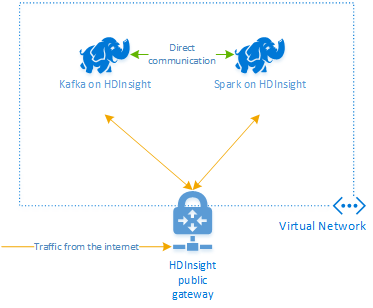
Apache Kafka on HDInsight 不提供通过公共 Internet 访问 Kafka 中转站的权限。 使用 Kafka 的任何项都必须位于同一 Azure 虚拟网络中。 在本教程中,Kafka 和 Spark 群集位于同一 Azure 虚拟网络。
下图显示通信在 Spark 和 Kafka 之间的流动方式:
注意
Kafka 服务仅限于虚拟网络内的通信。 通过 Internet 可访问群集上的其他服务,例如 SSH 和 Ambari。 有关可用于 HDInsight 的公共端口的详细信息,请参阅 HDInsight 使用的端口和 URI。
若要创建 Azure 虚拟网络,然后在其中创建 Kafka 和 Spark 群集,请使用以下步骤:
使用以下按钮登录到 Azure,并在 Azure 门户中打开模板。

Azure 资源管理器模板位于 https://raw.githubusercontent.com/Azure-Samples/hdinsight-spark-kafka-structured-streaming/master/azuredeploy.json 。
此模板可创建以下资源:
HDInsight 4.0 或 5.0 群集上的 Kafka。
HDInsight 4.0 或 5.0 群集上的 Spark 2.4 或 3.1。
包含 HDInsight 群集的 Azure 虚拟网络。
重要
本教程使用的结构化流式处理笔记本需要 HDInsight 4.0 或 5.0 上的 Spark 2.4 或 3.1。 如果使用早期版本的 Spark on HDInsight,则使用笔记本时会收到错误消息。
使用以下信息填充“自定义模板”部分的条目:
设置 值 订阅 Azure 订阅 资源组 包含资源的资源组。 位置 创建资源时所在的 Azure 区域。 Spark 群集名称 Spark 群集的名称。 前六个字符必须与 Kafka 群集名称不同。 Kafka 群集名称 Kafka 群集的名称。 前六个字符必须与 Spark 群集名称不同。 群集登录用户名 群集的管理员用户名。 群集登录密码 群集的管理员用户密码。 SSH 用户名 要为群集创建的 SSH 用户。 SSH 密码 用于 SSH 用户的密码。 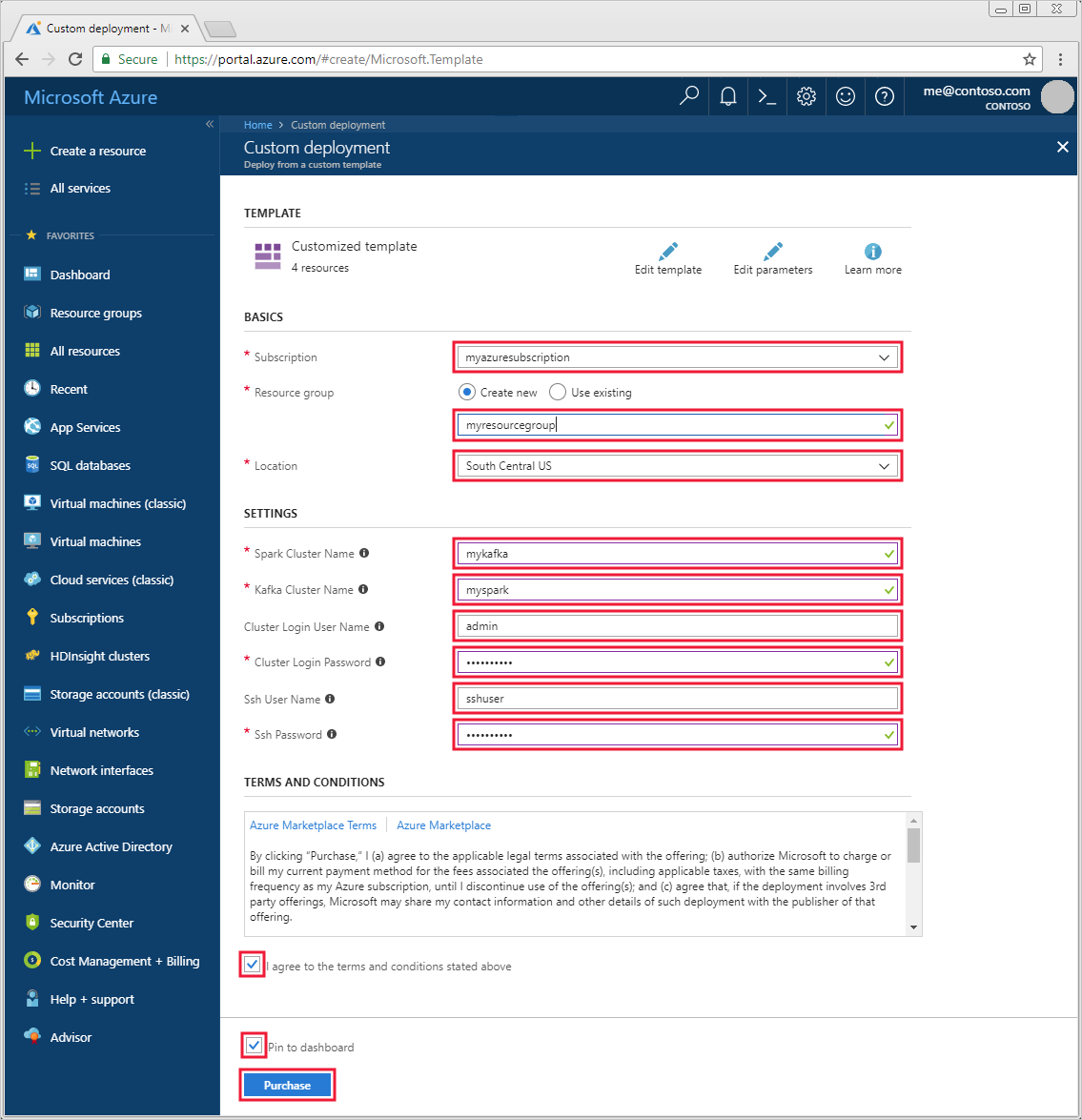
阅读“条款和条件”,然后选择“我同意上述条款和条件” 。
选择“购买”。
注意
创建群集可能需要长达 20 分钟的时间。
使用 Spark 结构化流式处理
收集主机信息。 使用下面的 curl 和 jq 命令获取 Kafka ZooKeeper 主机和代理主机信息。 这些命令设计用于 Windows 命令提示符,在其他环境中需要进行细微的更改。 将
KafkaCluster替换为 Kafka 群集的名称,并将KafkaPassword替换为群集登录密码。 另外,将C:\HDI\jq-win64.exe替换为 jq 安装的实际路径。 在 Windows 命令提示符中输入命令,然后保存输出,以便在后续步骤中使用。REM Enter cluster name in lowercase set CLUSTERNAME=KafkaCluster set PASSWORD=KafkaPassword curl -u admin:%PASSWORD% -G "https://%CLUSTERNAME%.azurehdinsight.cn/api/v1/clusters/%CLUSTERNAME%/services/ZOOKEEPER/components/ZOOKEEPER_SERVER" | C:\HDI\jq-win64.exe -r "["""\(.host_components[].HostRoles.host_name):2181"""] | join(""",""")" curl -u admin:%PASSWORD% -G "https://%CLUSTERNAME%.azurehdinsight.cn/api/v1/clusters/%CLUSTERNAME%/services/KAFKA/components/KAFKA_BROKER" | C:\HDI\jq-win64.exe -r "["""\(.host_components[].HostRoles.host_name):9092"""] | join(""",""")"在 Web 浏览器中,导航到
https://CLUSTERNAME.azurehdinsight.cn/jupyter,其中CLUSTERNAME是群集的名称。 出现提示时,输入创建群集时使用的群集登录名(管理员)和密码。选择“新建”>“Spark”,创建一个笔记本。
Spark 流式处理具有微型批处理,这意味着数据是成批传入的,而执行程序则对这批数据运行。 如果执行程序的空闲超时少于处理批处理所需的时间,则将不断添加和删除执行程序。 如果执行程序的空闲超时大于批处理持续时间,则不会删除执行程序。 因此,我们建议你在运行流式处理应用程序时通过将 spark.dynamicAllocation.enabled 设置为 false 来禁用动态分配。
加载供 Notebook 使用的包,方法是在 Notebook 单元格中输入以下信息。 使用 CTRL + ENTER 运行该命令。
%%configure -f { "conf": { "spark.jars.packages": "org.apache.spark:spark-sql-kafka-0-10_2.11:2.2.0", "spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.11", "spark.dynamicAllocation.enabled": false } }创建 Kafka 主题。 编辑以下命令,将
YOUR_ZOOKEEPER_HOSTS替换为在第一步提取的 Zookeeper 主机信息。 在 Jupyter Notebook 中输入编辑的命令,创建tripdata主题。%%bash export KafkaZookeepers="YOUR_ZOOKEEPER_HOSTS" /usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 3 --partitions 8 --topic tripdata --zookeeper $KafkaZookeepers检索出租车行程数据。 先将数据加载到数据帧中,然后将数据帧作为单元格输出显示。
import spark.implicits._ val url="https://data.cityofnewyork.us/resource/pqfs-mqru.json" val result = scala.io.Source.fromURL(url).mkString // Create a dataframe from the JSON data val taxiDF = spark.read.json(Seq(result).toDS) // Display the dataframe containing trip data taxiDF.show()设置 Kafka 代理主机信息。 将
YOUR_KAFKA_BROKER_HOSTS替换为在步骤 1 中提取的代理主机信息。 在下一 Jupyter Notebook 单元格中输入编辑的命令。// The Kafka broker hosts and topic used to write to Kafka val kafkaBrokers="YOUR_KAFKA_BROKER_HOSTS" val kafkaTopic="tripdata" println("Finished setting Kafka broker and topic configuration.")将数据发送到 Kafka。 在以下命令中,
vendorid字段用作 Kafka 消息的键值。 将数据分区时,此键供 Kafka 使用。 所有字段都作为 JSON 字符串值存储在 Kafka 消息中。 在 Jupyter 中输入以下命令,使用批量查询将数据保存到 Kafka。// Select the vendorid as the key and save the JSON string as the value. val query = taxiDF.selectExpr("CAST(vendorid AS STRING) as key", "to_JSON(struct(*)) AS value").write.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("topic", kafkaTopic).save() println("Data sent to Kafka")声明一个架构。 以下命令演示了从 Kafka 读取 JSON 数据时如何使用架构。 在下一 Jupyter 单元格中输入此命令。
// Import bits used for declaring schemas and working with JSON data import org.apache.spark.sql._ import org.apache.spark.sql.types._ import org.apache.spark.sql.functions._ // Define a schema for the data val schema = (new StructType).add("dropoff_latitude", StringType).add("dropoff_longitude", StringType).add("extra", StringType).add("fare_amount", StringType).add("improvement_surcharge", StringType).add("lpep_dropoff_datetime", StringType).add("lpep_pickup_datetime", StringType).add("mta_tax", StringType).add("passenger_count", StringType).add("payment_type", StringType).add("pickup_latitude", StringType).add("pickup_longitude", StringType).add("ratecodeid", StringType).add("store_and_fwd_flag", StringType).add("tip_amount", StringType).add("tolls_amount", StringType).add("total_amount", StringType).add("trip_distance", StringType).add("trip_type", StringType).add("vendorid", StringType) // Reproduced here for readability //val schema = (new StructType) // .add("dropoff_latitude", StringType) // .add("dropoff_longitude", StringType) // .add("extra", StringType) // .add("fare_amount", StringType) // .add("improvement_surcharge", StringType) // .add("lpep_dropoff_datetime", StringType) // .add("lpep_pickup_datetime", StringType) // .add("mta_tax", StringType) // .add("passenger_count", StringType) // .add("payment_type", StringType) // .add("pickup_latitude", StringType) // .add("pickup_longitude", StringType) // .add("ratecodeid", StringType) // .add("store_and_fwd_flag", StringType) // .add("tip_amount", StringType) // .add("tolls_amount", StringType) // .add("total_amount", StringType) // .add("trip_distance", StringType) // .add("trip_type", StringType) // .add("vendorid", StringType) println("Schema declared")选择数据并启动流。 以下命令演示了如何使用批处理查询从 Kafka 检索数据。 然后,将输出结果写入到 Spark 群集上的 HDFS 中。 在此示例中,
select从 Kafka 检索消息(值字段),然后为其应用架构。 然后,将数据以 parquet 格式写入 HDFS(WASB 或 ADL)。 在下一 Jupyter 单元格中输入此命令。// Read a batch from Kafka val kafkaDF = spark.read.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("subscribe", kafkaTopic).option("startingOffsets", "earliest").load() // Select data and write to file val query = kafkaDF.select(from_json(col("value").cast("string"), schema) as "trip").write.format("parquet").option("path","/example/batchtripdata").option("checkpointLocation", "/batchcheckpoint").save() println("Wrote data to file")可以在下一 Jupyter 单元格中输入此命令,验证这些文件是否已创建。 它会在
/example/batchtripdata目录中列出文件。%%bash hdfs dfs -ls /example/batchtripdata上一示例使用了批量查询,而以下命令则演示如何使用流式处理查询执行相同的操作。 在下一 Jupyter 单元格中输入此命令。
// Stream from Kafka val kafkaStreamDF = spark.readStream.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("subscribe", kafkaTopic).option("startingOffsets", "earliest").load() // Select data from the stream and write to file kafkaStreamDF.select(from_json(col("value").cast("string"), schema) as "trip").writeStream.format("parquet").option("path","/example/streamingtripdata").option("checkpointLocation", "/streamcheckpoint").start.awaitTermination(30000) println("Wrote data to file")运行以下单元格,验证是否已通过流式处理查询写入这些文件。
%%bash hdfs dfs -ls /example/streamingtripdata
清理资源
若要清理本教程创建的资源,可以删除资源组。 删除资源组还会删除关联的 HDInsight 群集, 以及与该资源组关联的任何其他资源。
若要使用 Azure 门户删除资源组,请执行以下操作:
- 在 Azure 门户中,展开左侧的菜单以打开服务菜单,然后选择“资源组”以显示资源组列表。
- 找到要删除的资源组,然后右键单击列表右侧的“更多”按钮 (...)。
- 选择“删除资源组”,然后进行确认。
警告
HDInsight 群集计费在创建群集之后便会开始,删除群集后才会停止。 HDInsight 群集按分钟收费,因此不再需要使用群集时,应将其删除。
删除 Kafka on HDInsight 群集会删除存储在 Kafka 中的任何数据。