Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
为了给分析组件提供最佳的可用性级别,我们使用独特的体系结构开发了 HDInsight,以确保关键服务的高可用性 (HA)。 此体系结构的某些组件由 Azure 开发,旨在提供自动故障转移。 其他组件是为了支持特定的服务而部署的标准 Apache 组件。 本文介绍 HDInsight 中 HA 服务模型的体系结构,HDInsight 如何支持 HA 服务的故障转移,以及在其他服务发生中断后如何进行恢复。
注意
本文包含对术语“从属”的引用,这是 Azure 不再使用的术语。 在从软件中删除该术语后,我们会将其从本文中删除。
高可用性基础结构
HDInsight 提供自定义的基础结构,以确保四个主要服务具有高可用性和自动故障转移功能:
- Apache Ambari 服务器
- 适用于 Apache YARN 的应用程序时间线服务器
- 适用于 Hadoop MapReduce 的作业历史记录服务器
- Apache Livy
此基础结构由许多服务和软件组件构成,其中的一些组件由 Microsoft 设计。 下面是 HDInsight 平台中特有的组件:
- 从属故障转移控制器
- 主故障转移控制器
- 从属高可用性服务
- 主高可用性服务
此外,还有开源 Apache 可靠性组件支持的其他高可用性服务。 HDInsight 群集中还包含以下组件:
- Hadoop 文件系统 (HDFS) NameNode
- YARN ResourceManager
- HBase Master
以下部分将详细介绍这些服务如何协同工作。
HDInsight 高可用性服务
Microsoft Azure 为下表中所述的 HDInsight 群集中的四个 Apache 服务提供支持。 为了将这些服务与 Apache 组件支持的高可用性服务区分开来,下表中将它们称作“HDInsight HA 服务”。
| 服务 | 群集节点 | 群集类型 | 目的 |
|---|---|---|---|
| Apache Ambari 服务器 | 活动头节点 | 全部 | 监视和管理群集。 |
| 适用于 Apache YARN 的应用程序时间线服务器 | 活动头节点 | 除 Kafka 以外的所有服务 | 维护有关群集上运行的 YARN 作业的调试信息。 |
| 适用于 Hadoop MapReduce 的作业历史记录服务器 | 活动头节点 | 除 Kafka 以外的所有服务 | 维护 MapReduce 作业的调试数据。 |
| Apache Livy | 活动头节点 | Spark | 用于通过 REST 接口轻松与 Spark 群集交互 |
注意
HDInsight 企业安全性套餐 (ESP) 群集目前仅提供 Ambari 服务器高可用性。 应用程序时间线服务器、作业历史记录服务器和 Livy 都仅在 headnode0 上运行,当 Ambari 故障转移时不会故障转移到 headnode1。 应用程序时间线数据库也位于 headnode0 上,不位于 Ambari SQL 服务器上。
体系结构
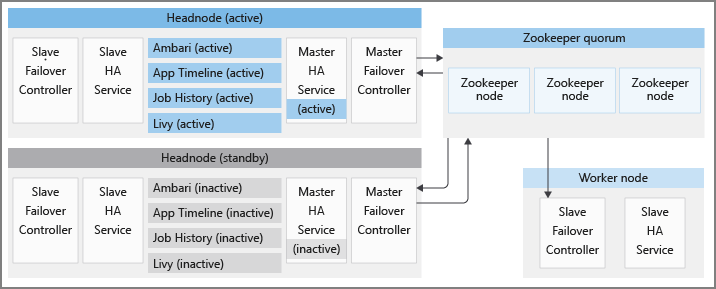
每个 HDInsight 群集有两个头节点,这些节点分别处于活动状态和待机模式。 HDInsight HA 服务仅在头节点上运行。 这些服务应始终在活动头节点上运行,在待机头节点上应将其停止并置于维护模式。
为了保持 HA 服务的正常状态并提供快速故障转移,HDInsight 利用 Apache ZooKeeper(分布式应用程序的协调服务)来执行活动头节点的选举。 HDInsight 还会预配几个后台 Java 进程,用于协调 HDInsight HA 服务的故障转移过程。 这些服务包括:主故障转移控制器、从属故障转移控制器、master-ha-service 和 slave-ha-service。
Apache ZooKeeper
Apache ZooKeeper 是分布式应用程序的高性能协调服务。 在生产环境中,ZooKeeper 通常在复制模式下运行,其中的 ZooKeeper 服务器复制组构成了仲裁。 每个 HDInsight 群集包含三个 ZooKeeper 节点,这些节点允许三个 ZooKeeper 服务器构成仲裁。 HDInsight 的两个 ZooKeeper 仲裁以相互并行的方式运行。 其中一个仲裁确定了群集中应运行 HDInsight HA 服务的活动头节点。 另一个仲裁用于协调 Apache 提供的 HA 服务,后续部分将会详述。
从属故障转移控制器
从属故障转移控制器在 HDInsight 群集中的每个节点上运行。 此控制器负责在每个节点上启动 Ambari 代理和 slave-ha-service。 它定期在第一个 ZooKeeper 仲裁中查询有关活动头节点的信息。 当活动和待机头节点发生变化时,从属故障转移控制器将执行以下操作:
- 更新主机配置文件。
- 重启 Ambari 代理。
slave-ha-service 负责停止待机头节点上的 HDInsight HA 服务(Ambari 服务器除外)。
主故障转移控制器
主故障转移控制器在两个头节点上运行。 这两个主故障转移控制器与第一个 ZooKeeper 仲裁通信,以将它们运行所在的头节点指定为活动头节点。
例如,如果头节点 0 上的主故障转移控制器赢得选举,则会发生以下更改:
- 头节点 0 变为活动头节点。
- 主故障转移控制器在头节点 0 上启动 Ambari 服务器和 master-ha-service。
- 另一个主故障转移控制器在头节点 1 上停止 Ambari 服务器和 master-ha-service。
master-ha-service 仅在活动头节点上运行,它会停止待机头节点上的 HDInsight HA 服务(Ambari 服务器除外),并在活动头节点上启动这些服务。
故障转移过程
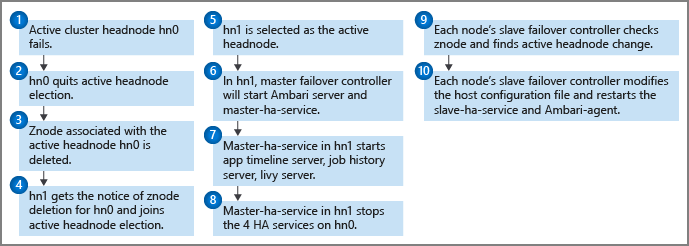
运行状况监视器在每个头节点上连同主故障转移控制器一起运行,将检测信号通知发送到 Zookeeper 仲裁。 在此方案中,头节点被视为 HA 服务。 运行状况监视器检查每个高可用性服务是否正常,以及该服务是否已准备好参与领导选举。 如果是,则此头节点将参与选举。 否则,它将退出选举,直到再次准备就绪。
如果待机头节点赢得领导选举并变为活动头节点(例如,在前一个活动节点发生故障时),则其主故障转移控制器将启动其上的所有 HDInsight HA 服务。 主故障转移控制器会停止另一头节点上的这些服务。
HDInsight HA 服务发生故障(例如,服务关闭或不正常)时,主故障转移控制器应根据头节点的状态自动重启或停止服务。 用户不应在这两个头节点上手动启动 HDInsight HA 服务, 而应通过自动或手动故障转移来帮助恢复服务。
意外的手动干预
HDInsight HA 服务只应在活动头节点上运行,并在必要时自动重启。 由于单个 HA 服务没有自身的运行状况监视器,因此无法在单个服务的级别触发故障转移。 可以确保故障转移在节点级别发生,但不能确保在服务级别发生。
某些已知问题
在待机节点上手动启动某个 HA 服务时,在发生下一次故障转移之前该服务不会停止。 当 HA 服务同时在两个头节点上运行时,可能会出现的一些问题包括:Ambari UI 不可访问、Ambari 引发错误,YARN、Spark、Oozie 作业可能会停滞。
当活动头节点上的某个 HA 服务停止时,在发生下一次故障转移或者主故障转移控制器/master-ha-service 重启之前,该服务不会重启。 当活动头节点上的一个或多个 HA 服务停止时(尤其是当 Ambari 服务器停止时),Ambari UI 将不可访问,其他潜在问题包括 YARN、Spark 和 Oozie 作业失败。
Apache 高可用性服务
Apache 为 HDFS NameNode、YARN ResourceManager 和 HBase Master(在 HDInsight 群集中也可用)提供高可用性。 与 HDInsight HA 服务不同,这些组件在 ESP 群集中受支持。 Apache HA 服务与第二个 ZooKeeper 仲裁通信(如上一部分所述),以选择活动/待机状态并执行自动故障转移。 以下部分将详细说明这些服务的工作原理。
Hadoop 分布式文件系统 (HDFS) NameNode
基于 Apache Hadoop 2.0 或更高版本的 HDInsight 群集提供 NameNode 高可用性。 有两个为自动故障转移配置的 NameNode 在头节点上运行。 这些 NameNode 使用 ZKFailoverController 来与 Zookeeper 通信,以选择活动/待机状态。 ZKFailoverController 在两个头节点上运行,其工作方式与主故障转移控制器相同。
第二个 Zookeeper 仲裁独立于第一个仲裁,因此活动 NameNode 不能在活动头节点上运行。 当活动 NameNode 处于死机或不正常状态时,待机 NameNode 将赢得选举并变为活动头节点。
YARN ResourceManager
基于 Apache Hadoop 2.4 或更高版本的 HDInsight 群集支持 YARN ResourceManager 高可用性。 有两个 ResourceManager(rm1 和 rm2)分别在头节点 0 和头节点 1 上运行。 与 NameNode 一样,YARN ResourceManager 也是为自动故障转移配置的。 如果当前活动 ResourceManager 关闭或无响应,将自动选择另一个 ResourceManager 作为活动头节点。
YARN ResourceManager 使用其嵌入式 ActiveStandbyElector 作为故障检测器和领导选举器。 与 HDFS NameNode 不同,YARN ResourceManager 不需要独立的 ZKFC 守护程序。 活动的 ResourceManager 将其状态写入 Apache Zookeeper。
YARN ResourceManager 的高可用性独立于 NameNode 和其他 HDInsight HA 服务。 活动的 ResourceManager 不可以在头节点上运行,也不可以在正在运行活动 NameNode 的头节点上运行。 有关 YARN ResourceManager 高可用性的详细信息,请参阅 ResourceManager 高可用性。
HBase Master
HDInsight HBase 群集支持 HBase Master 高可用性。 与头节点上运行的其他 HA 服务不同,HBase 主机在三个 Zookeeper 节点上运行,其中一个节点是活动主节点,另外两个节点是待机节点。 与 NameNode 一样,HBase Master 将与 Apache Zookeeper 协调以进行领导选举,并在当前活动主节点出现问题时执行自动故障转移。 无论何时,都只有一个活动的 HBase Master。