Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Apache Phoenix 是构建在 Apache HBase 基础之上的开源大规模并行关系数据库层。 Phoenix 允许通过 HBase 使用类似于 SQL 的查询。 Phoenix 在幕后使用 JDBC 驱动程序,可让用户创建、删除和更改 SQL 表、索引、视图与序列,以及单独或批量更新插入行。 Phoenix 使用 noSQL 本机编译而不是 MapReduce 来编译查询,可让用户在 HBase 的顶层创建低延迟的应用程序。 Phoenix 添加了协处理器,支持在服务器的地址空间中运行客户端提供的代码,执行与数据共置的代码。 此方法可将客户端/服务器数据传输延迟降到最低。
非开发人员可以借助 Apache Phoenix 创建大数据查询,并在其中使用类似于 SQL 的语法,而无需编程。 与 Apache Hive 和 Apache Spark SQL 等其他工具不同,Phoenix 已针对 HBase 高度优化。 开发人员可以利用它来编写高性能的查询,同时大大减少代码量。
提交 SQL 查询时,Phoenix 会将该查询编译到 HBase 本机调用,然后并行运行扫描(或计划)以进行优化。 此抽象层使得开发人员无需编写 MapReduce 作业,让他们专注于围绕 Phoenix 的大数据存储构建应用程序的业务逻辑和工作流。
查询性能优化和其他功能
Apache Phoenix 为 HBase 查询带来了多种性能增强和功能。
辅助索引
HBase 使用根据主行键按字典顺序排序的单个索引。 只能通过行键访问这些记录。 通过除行键以外的任何列访问记录都需要扫描所有数据,同时应用所需的筛选器。 辅助索引中,从备用行键编制索引的列或表达式,可用于针对该索引执行查找和范围扫描。
使用 CREATE INDEX 命令创建辅助索引:
CREATE INDEX ix_purchasetype on SALTEDWEBLOGS (purchasetype, transactiondate) INCLUDE (bookname, quantity);
与执行单一索引查询相比,此方法可以大幅提升性能。 这种类型的辅助索引是涵盖索引,包含查询中包括的所有列。 因此,不需要执行表查找,索引能够满足整个查询的需求。
视图
Phoenix 视图可以克服一项 HBase 限制:创建 100 个以上的物理表时,性能开始下降。 Phoenix 视图可让多个虚拟表共享一个 HBase 基础物理表。
创建 Phoenix 视图的过程类似于使用标准的 SQL 视图语法。 两者的一项差别在于,除了继承自基表的列以外,还可为视图定义列。 此外,可以添加新的 KeyValue 列。
例如,下面是一个包含以下定义的、名为 product_metrics 的物理表:
CREATE TABLE product_metrics (
metric_type CHAR(1) NOT NULL,
created_by VARCHAR,
created_date DATE NOT NULL,
metric_id INTEGER NOT NULL
CONSTRAINT pk PRIMARY KEY (metric_type, created_by, created_date, metric_id));
基于此表定义视图,并在其中包含更多列:
CREATE VIEW mobile_product_metrics (carrier VARCHAR, dropped_calls BIGINT) AS
SELECT * FROM product_metrics
WHERE metric_type = 'm';
以后若要添加更多的列,可以使用 ALTER VIEW 语句。
跳过扫描
跳过扫描使用组合索引的一个或多个列来查找非重复值。 与范围扫描不同,跳过扫描实施行内扫描,因此可以提高性能。 扫描时,会连同索引一起跳过第一个匹配值,直到找到下一个值。
跳过扫描使用 HBase 筛选器的 SEEK_NEXT_USING_HINT 枚举。 跳过扫描使用 SEEK_NEXT_USING_HINT 来跟踪在每个列中搜索的键集或键范围。 然后,跳过扫描将使用在评估筛选器期间传递给它的键,并确定该键是否为组合之一。 如果不是,则跳过扫描会评估要跳转到的下一个最高键。
事务
尽管 HBase 提供行级事务,但 Phoenix 与 Tephra 集成,添加了跨行和跨表事务支持,并具有完整的 ACID 语义。
与传统的 SQL 事务一样,通过 Phoenix 事务管理器提供的事务可以确保成功更新插入数据原子单位;如果任何已启用事务的表中的更新插入操作失败,还可以回滚事务。
若要启用 Phoenix 事务,请参阅Apache Phoenix 事务文档。
若要创建启用事务的新表,请在 CREATE 语句中将 TRANSACTIONAL 属性设置为 true:
CREATE TABLE my_table (k BIGINT PRIMARY KEY, v VARCHAR) TRANSACTIONAL=true;
若要将现有表更改为事务表,请在 ALTER 语句中使用相同的属性:
ALTER TABLE my_other_table SET TRANSACTIONAL=true;
注意
无法将事务表切换回到非事务表。
加盐表
向 HBase 写入包含顺序键的记录时,可能会出现区域服务器热点。 即使群集中包含多个区域服务器,也只会在一个服务器中进行写入。 这种集中化会产生热点问题,即,写入工作负荷不会分散在所有可用的区域服务器之间,而是只有一个服务器处理该负载。 由于每个区域都具有预定义的最大大小,所以当某个区域达到该大小限制时,它将会拆分为两个较小区域。 在这种情况下,其中一个新区域会接收所有新记录,因而变成了新的热点。
若要缓解此问题并提高性能,请预先拆分表,以便均衡使用所有的区域服务器。 Phoenix 提供加盐表,以透明方式将加盐字节添加到特定表的行键。 该表已在加盐字节边界上预先拆分,确保在表的初始阶段,在区域服务器之间均衡分配负载。 此方法可在所有可用的区域服务器之间分配写入工作负荷,从而提高了写入和读取性能。 若要给表加盐,请在创建表时指定 SALT_BUCKETS 表属性:
CREATE TABLE Saltedweblogs (
transactionid varchar(500) Primary Key,
transactiondate Date NULL,
customerid varchar(50) NULL,
bookid varchar(50) NULL,
purchasetype varchar(50) NULL,
orderid varchar(50) NULL,
bookname varchar(50) NULL,
categoryname varchar(50) NULL,
invoicenumber varchar(50) NULL,
invoicestatus varchar(50) NULL,
city varchar(50) NULL,
state varchar(50) NULL,
paymentamount DOUBLE NULL,
quantity INTEGER NULL,
shippingamount DOUBLE NULL) SALT_BUCKETS=4;
使用 Apache Ambari 启用和优化 Phoenix
HDInsight HBase 群集提供 Ambari UI 用于进行配置更改。
若要启用或禁用 Phoenix 并控制 Phoenix 的查询超时设置,请使用 Hadoop 用户凭据登录到 Ambari Web UI (
https://YOUR_CLUSTER_NAME.azurehdinsight.cn)。在左侧菜单中的服务列表内选择“HBase”,然后选择“配置”选项卡。
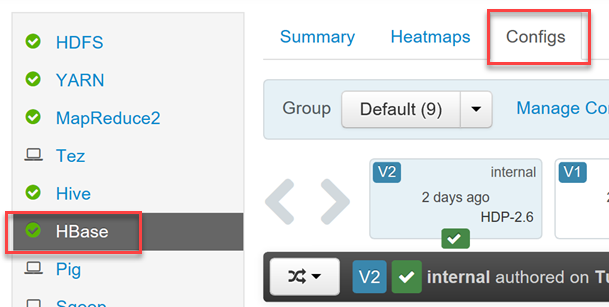
找到“Phoenix SQL”配置部分,启用或禁用 Phoenix,并设置查询超时。