Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Azure Storage是一种可靠的常规用途存储解决方案,可与 HDInsight 无缝集成。 HDInsight 可以使用 Azure Storage 中的 blob 容器作为群集的默认文件系统。 HDInsight 中的整套组件可以通过 HDFS 接口直接操作以 Blob 形式存储的结构化或非结构化数据。
我们建议为默认群集存储和业务数据使用单独的存储容器。 分离是为了将 HDInsight 日志和临时文件与你自己的业务数据隔离。 我们还建议在每次使用后删除默认的 Blob 容器(其中包含应用程序和系统日志),以降低存储成本。 请确保在删除该容器之前检索日志。
如果选择使用 防火墙和虚拟网络限制来保护 选定网络 的存储帐户,请确保启用异常 允许受信任的 Azure 服务...。启用该例外使 HDInsight 能够访问您的存储帐户。
HDInsight 存储体系结构
下图提供了 Azure Storage HDInsight 体系结构的抽象视图:
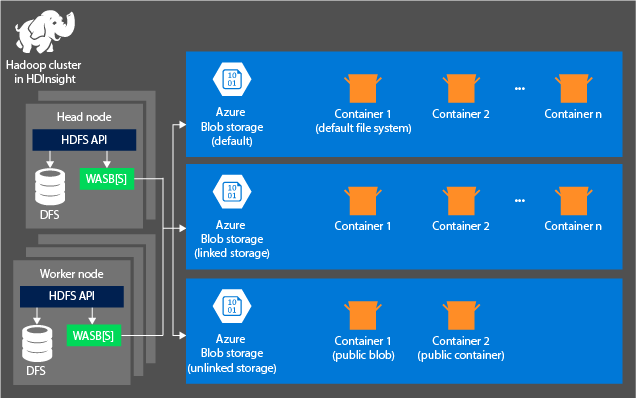
HDInsight 提供对在本地附加到计算节点的分布式文件系统的访问。 可使用完全限定 URI 访问该文件系统,例如:
hdfs://<namenodehost>/<path>
通过 HDInsight,还可以访问Azure Storage中的数据。 语法如下所示:
wasb://<containername>@<accountname>.blob.core.chinacloudapi.cn/<path>
对于具有分层命名空间(Azure Data Lake Storage Gen2)的帐户,语法如下所示:
abfs://<containername>@<accountname>.dfs.core.chinacloudapi.cn/<file.path>/
将 Azure Storage 帐户与 HDInsight 群集配合使用时,请考虑以下原则:
连接到群集的存储帐户中的容器:由于在创建过程中帐户名称和密钥将与群集相关联,因此,对这些容器中的 Blob 具有完全访问权限。
没有连接到群集的存储帐户中的公共容器或公共 Blob:你对这些容器中的 Blob 具有只读权限。
注释
利用公共容器,可以获得该容器中可用的所有 Blob 的列表以及容器元数据。 利用公共 Blob,仅在知道正确 URL 时才可访问 Blob。 有关详细信息,请参阅管理对容器和 Blob 的匿名读取访问。
没有连接到群集的存储帐户中的私有容器:不能访问这些容器中的 Blob,除非在提交 WebHCat 作业时定义存储帐户。
创建过程中定义的存储帐户及其密钥存储在群集节点上的 %HADOOP/_HOME%/conf/core-site.xml 中。 HDInsight 默认使用 core-site.xml 文件中定义的存储帐户。 可以使用 Apache Ambari 修改此设置。 有关可以修改或放置在 core-site.xml 文件中的存储帐户设置的详细信息,请参阅以下文章:
多个 WebHCat 作业,包括 Apache Hive。 MapReduce、Apache Hadoop 流和 Apache Pig 带有对存储帐户和元数据的描述。 (它目前适用于带有存储帐户的 Pig,但不适用于元数据。)有关详细信息,请参阅将 HDInsight 群集与备用存储帐户和元存储配合使用。
Blob 可用于结构化和非结构化数据。 Blob 容器将数据存储为键值对,没有目录层次结构。 不过,键名称可以包含斜杠字符 (/),使其看起来像存储在目录结构中的文件。 例如,Blob 的键可以是 input/log1.txt。 不存在实际的 input 目录,但由于键名称中包含斜杠字符,键看起来像一个文件路径。
Azure Storage的优点
未共置在一起的计算群集和存储资源存在隐含的性能成本。 通过创建靠近Azure区域中存储帐户资源的计算群集的方式,可以减轻这些成本。 在此区域中,计算节点可以通过Azure Storage内的高速网络有效地访问数据。
将数据存储在 Azure Storage 而不是 HDFS 中时,可以获得以下几个好处:
数据重用和共享: HDFS 中的数据位于计算群集内。 仅有权访问计算群集的应用程序才能通过 HDFS API 使用数据。 相比之下,可以通过 HDFS API 或 Blob 存储 REST API 访问Azure Storage中的数据。 因此,可以使用更多的应用程序(包括其他 HDInsight 群集)和工具来生成和使用此类数据。
数据存档:将数据存储在Azure Storage中时,可以安全地删除用于计算的 HDInsight 群集,而不会丢失用户数据。
数据存储成本:长期在 DFS 中存储数据的成本比将数据存储在 Azure Storage 中要高。 因为计算群集的成本高于Azure Storage的成本。 此外,由于数据无需在每次生成计算群集时重新加载,也节省了数据加载成本。
弹性横向扩展:尽管 HDFS 提供了向外扩展文件系统,但缩放由你为群集创建的节点数量决定。 更改缩放比在Azure Storage中自动获取的弹性缩放功能要复杂得多。
Geo-replication:您的 Azure 存储可以进行异地复制。 尽管异地复制可提供地理恢复和数据冗余功能,但针对异地复制位置的故障转移将大大影响性能,并且可能会产生额外成本。 因此,请谨慎选择异地复制,并仅在数据的价值值得支付额外成本时才选择它。
某些 MapReduce 作业和包可能会创建不希望存储在Azure Storage的中间结果。 在此情况下,仍可以选择将数据存储在本地 HDFS 中。 HDInsight 在 Hive 作业和其他过程中会为其中某些中间结果使用 DFS。
注释
大多数 HDFS 命令(例如,ls、copyFromLocal 和 mkdir)在Azure Storage中按预期工作。 只有特定于本机 HDFS 实现(称为 DFS)的命令(如 fschk 和 dfsadmin)在Azure Storage中显示不同的行为。