Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
HDInsight Spark 群集提供可在 Apache Spark 上的 Jupyter Notebook 中用于测试应用程序的内核。 内核是可以运行和解释代码的程序。 三个内核如下:
- PySpark - 适用于以 Python2 编写的应用程序。 (仅适用于 Spark 2.4 版本群集)
- PySpark3 - 适用于以 Python3 编写的应用程序。
- Spark - 适用于以 Scala 编写的应用程序。
本文介绍如何使用这些内核以及使用它们的优势。
先决条件
HDInsight 中的 Apache Spark 群集。 有关说明,请参阅在 Azure HDInsight 中创建 Apache Spark 群集。
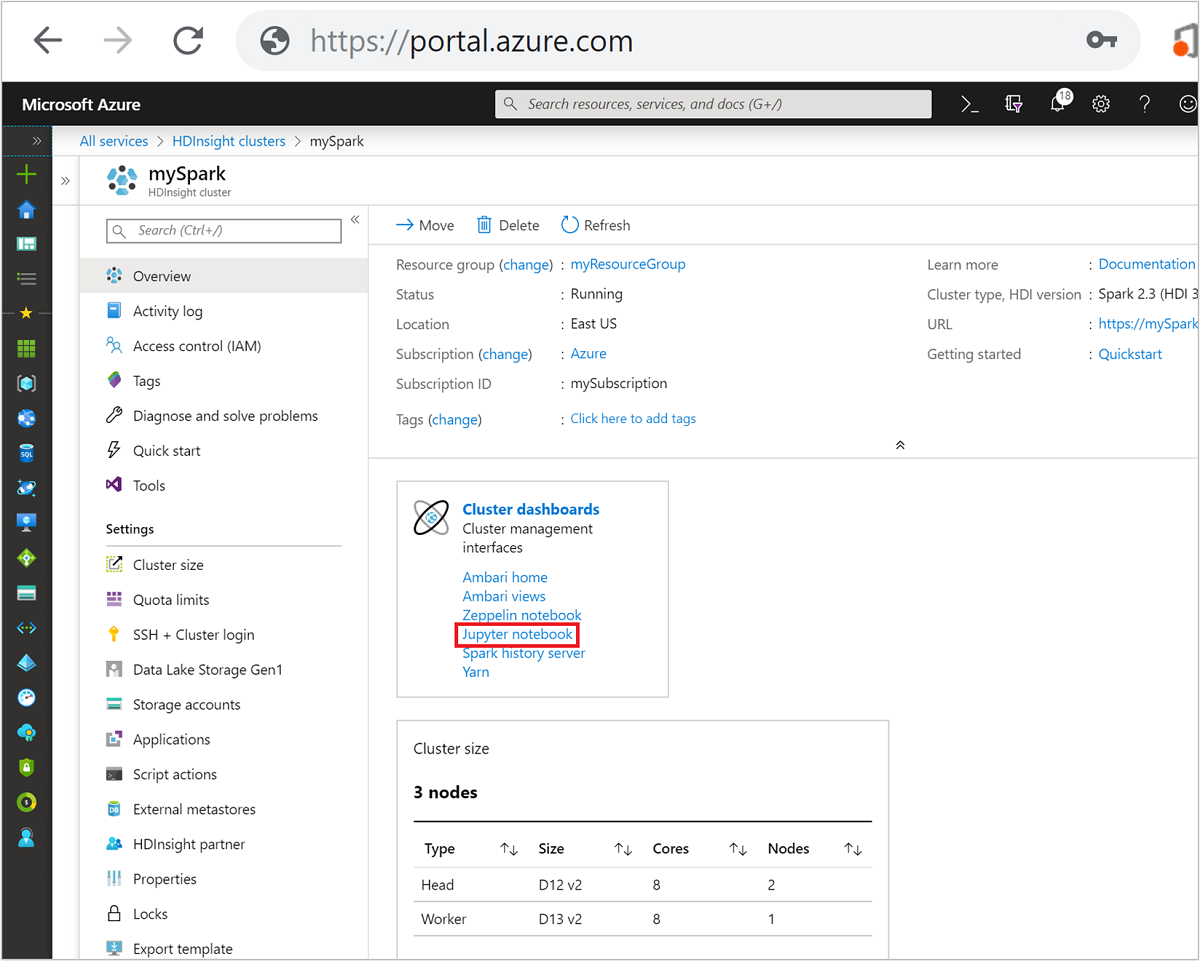
在 Spark HDInsight 上创建 Jupyter Notebook
在“概述”视图的“群集仪表板”框中,选择“Jupyter Notebook”。 出现提示时,请输入群集的管理员凭据。
注意
也可以在浏览器中打开以下 URL 来访问 Spark 群集中的 Jupyter Notebook。 将 CLUSTERNAME 替换为群集的名称:
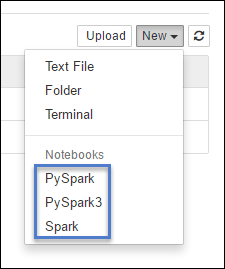
https://CLUSTERNAME.azurehdinsight.cn/jupyter选择“新建”,然后选择“Pyspark”、“PySpark3”或“Spark”创建 Notebook。 使用适用于 Scala 应用程序的 Spark 内核、适用于 Python2 应用程序的 PySpark 内核,以及适用于 Python3 应用程序的 PySpark3 内核。
注意
对于 Spark 3.1,只有 PySpark3 或 Spark 可用。
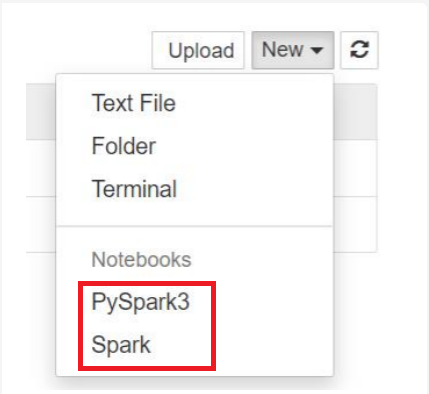
- 此时会打开使用所选内核的 Notebook。
使用这些内核的好处
以下是在 Spark HDInsight 群集中的 Jupyter Notebook 上使用新内核的几个好处。
预设上下文。 使用 PySpark、PySpark3 或 Spark 内核时,无需先显式设置 Spark 或 Hive 上下文,即可开始使用应用程序。 这些上下文默认可用。 这些上下文包括:
sc - 表示 Spark 上下文
sqlContext - 表示 Hive 上下文
因此,不需要运行如下语句来设置上下文:
sc = SparkContext('yarn-client') sqlContext = HiveContext(sc)可以直接在应用程序中使用预设上下文。
单元 magic。 PySpark 内核提供一些预定义的“magic”,这是可以结合
%%调用的特殊命令(例如%%MAGIC<args>)。 magic 命令必须是代码单元中的第一个字,并且允许多行内容。 magic 一字应该是单元中的第一个字。 在 magic 前面添加任何内容(即使是注释)都会导致错误。 有关 magic 的详细信息,请参阅 此文。下表列出了可通过内核提供的不同 magic。
Magic 示例 说明 help %%help生成所有可用 magic 的表,其中包含示例和说明 info %%info输出当前 Livy 终结点的会话信息 配置 %%configure -f{"executorMemory": "1000M","executorCores": 4}配置用于创建会话的参数。 如果已创建会话,则必须指定 force 标志 ( -f),确保删除再重新创建该会话。 有关有效参数的列表,请查看 Livy's POST /sessions Request Body (Livy 的 POST /sessions 请求正文)。 参数必须以 JSON 字符串传入,并且必须位于 magic 后面的下一行,如示例列中所示。sql %%sql -o <variable name>
SHOW TABLES针对 sqlContext 执行 Hive 查询。 如果传递了 -o参数,则查询的结果以 Pandas 数据帧的形式保存在 %%local Python 上下文中。local %%locala=1后续行中的所有代码将在本地执行。 无论你使用哪个内核,代码都必须是有效的 Python2 代码。 因此,即使在创建 Notebook 时选择了“PySpark3”或“Spark”,但如果在单元中使用 %%localmagic,该单元也只能包含有效的 Python2 代码。日志 %%logs输出当前 Livy 会话的日志。 删除 %%delete -f -s <session number>删除当前 Livy 终结点的特定会话。 无法删除针对内核本身启动的会话。 cleanup %%cleanup -f删除当前 Livy 终结点的所有会话,包括此笔记本的会话。 force 标志 -f 是必需的。 注意
除了 PySpark 内核添加的 magic 以外,还可以使用内置的 IPython magic(包括
%%sh)。 可以使用%%shmagic 在群集头节点上运行脚本和代码块。自动可视化。 Pyspark 内核会自动将 Hive 和 SQL 查询的输出可视化。 可以选择多种不同类型的视觉效果,包括表、饼图、折线图、分区图和条形图。
%%sql magic 支持的参数
%%sql magic 支持不同的参数,可以使用这些参数控制运行查询时收到的输出类型。 下表列出了输出。
| 参数 | 示例 | 说明 |
|---|---|---|
| -o | -o <VARIABLE NAME> |
使用此参数将查询结果以 Pandas 数据帧的形式保存在 %%local Python 上下文中。 数据帧变量的名称是指定的变量名称。 |
| -q | -q |
使用此参数可关闭单元可视化。 如果不想自动将单元内容可视化,而只想将它作为数据帧捕获,可以使用 -q -o <VARIABLE>。 如果想要关闭可视化而不捕获结果(例如,运行诸如 CREATE TABLE 语句的 SQL 查询),请使用不带 -o 参数的 -q。 |
| -m | -m <METHOD> |
其中,METHOD 是 take 或 sample(默认为 take)。 如果方法为 take ,内核将从 MAXROWS 指定的结果数据集顶部选取元素(如此表中的后面部分所述)。 如果方法为 sample,内核将根据 -r 参数进行数据集的元素随机采样,如此表中稍后所述。 |
| -r | -r <FRACTION> |
此处的 FRACTION 是介于 0.0 与 1.0 之间的浮点数。 如果 SQL 查询的示例方法为 sample,则内核会随机地对结果集的指定部分元素取样。 例如,如果使用参数 -m sample -r 0.01运行 SQL 查询,则 1% 的结果行是随机取样的。 |
| -n | -n <MAXROWS> |
MAXROWS 是整数值。 内核将输出行的数目限制为 MAXROWS。 如果“MAXROWS”是负数(例如“-1”),结果集中的行数不受限制。 |
示例:
%%sql -q -m sample -r 0.1 -n 500 -o query2
SELECT * FROM hivesampletable
上述语句执行以下操作:
- 从 hivesampletable中选择所有记录。
- 由于使用了 -q,因此将关闭自动可视化。
- 由于使用了
-m sample -r 0.1 -n 500,因此将从 hivesampletable 的行中随机采样 10%,并将结果集的大小限制为 500 行。 - 最后,由于使用了
-o query2,因此将输出保存到名为 query2的数据帧中。
使用新内核时的注意事项
不管使用哪种内核,使 Notebook 一直保持运行都会消耗群集资源。 使用这些内核时,由于上下文是预设的,仅退出笔记本并不会终止上下文, 因此会继续占用群集资源。 合理的做法是在使用完笔记本后,使用笔记本的“文件”菜单中的“关闭并停止”选项。 关闭会终止上下文,并退出笔记本。
Notebook 存储在何处?
如果群集使用 Azure 存储作为默认存储帐户,Jupyter Notebook 将保存到“/HdiNotebooks”文件夹下的存储帐户。 可以从存储帐户访问在 Jupyter 内部创建的 Notebook、文本文件和文件夹。 例如,如果使用 Jupyter 创建文件夹 myfolder 和笔记本“myfolder/mynotebook.ipynb”,则可在存储帐户中通过 /HdiNotebooks/myfolder/mynotebook.ipynb 访问该笔记本。 反之亦然,如果直接将 Notebook 上传到 /HdiNotebooks/mynotebook1.ipynb中的存储帐户,则可以从 Jupyter 查看该 Notebook。 即使删除了群集,Notebook 也仍会保留在存储帐户中。
注意
将 Azure Data Lake Storage 作为默认存储的 HDInsight 群集不在关联的存储中存储笔记本。
将笔记本保存到存储帐户的方式与 Apache Hadoop HDFS 兼容。 如果通过 SSH 连接到群集,可以使用文件管理命令:
| Command | 说明 |
|---|---|
hdfs dfs -ls /HdiNotebooks |
# 列出根目录中的所有内容 - Jupyter 可以从主页看到此目录中的所有内容 |
hdfs dfs -copyToLocal /HdiNotebooks |
# 下载 HdiNotebooks 文件夹的内容 |
hdfs dfs -copyFromLocal example.ipynb /HdiNotebooks |
# 将笔记本 example.ipynb 上传到根文件夹,使其在 Jupyter 中可见 |
不论群集是使用 Azure 存储还是 Azure Data Lake Storage 作为默认存储帐户,笔记本还是会保存在群集头节点上的 /var/lib/jupyter 中。
建议
新内核正处于发展阶段,一段时间后将变得成熟。 因此,API 会随着这些内核的成熟而改变。 如果在使用这些新内核时有任何反馈,我们将不胜感激。 此反馈对于塑造这些内核的最终版本会很有帮助。 可以在本文末尾的“反馈”部分下面留下意见/反馈。