Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
HDInsight Spark 群集包含 Apache Spark 库的安装。 每个 HDInsight 群集包含其所有已安装服务(包括 Spark)的默认配置参数。 管理 HDInsight Apache Hadoop 群集时,一个重要方面是监视工作负荷(包括 Spark 作业)。 若要最合理地运行 Spark 作业,请在确定群集的逻辑配置时考虑物理群集配置。
默认的 HDInsight Apache Spark 群集包括以下节点:三个 Apache ZooKeeper 节点、两个头节点和一个或多个工作节点:
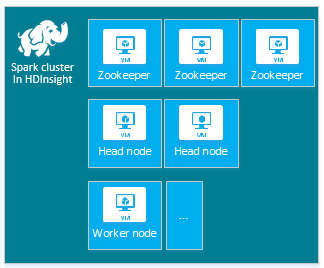
HDInsight 群集中节点的 VM 数目和 VM 大小可能影响 Spark 配置。 非默认的 HDInsight 配置值通常需要非默认的 Spark 配置值。 在创建 HDInsight Spark 群集时,系统会显示每个组件的建议 VM 大小。 目前,Azure 的 内存优化 Linux VM 大小为 D12 v2 或更高版本。
Apache Spark 版本
使用适合你的群集的最佳 Spark 版本。 HDInsight 服务本身包含 Spark 和 HDInsight 的多个版本。 每个 Spark 版本包含一组默认群集设置。
创建新群集时,可从以下多个 Spark 版本中进行选择。 若要查看完整列表,请参阅 HDInsight 组件和版本。
注意
HDInsight 服务中的默认 Apache Spark 版本可随时更改,恕不另行通知。 如果有版本依赖项,Azure建议在使用 .NET SDK、Azure PowerShell 和 Azure 经典 CLI 创建群集时指定该特定版本。
Apache Spark 有三个系统配置位置:
- Spark 属性控制大多数应用程序参数,可以使用
SparkConf对象或通过Java系统属性进行设置。 - 可以通过每个节点上的
conf/spark-env.sh脚本,使用环境变量来配置每台计算机的设置,例如 IP 地址。 - 可以通过
log4j.properties配置日志记录。
选择特定的 Spark 版本时,群集将包含默认的配置设置。 可以通过使用自定义的 Spark 配置文件来更改默认的 Spark 配置值。 下面显示了一个示例。
spark.hadoop.io.compression.codecs org.apache.hadoop.io.compress.GzipCodec
spark.hadoop.mapreduce.input.fileinputformat.split.minsize 1099511627776
spark.hadoop.parquet.block.size 1099511627776
spark.sql.files.maxPartitionBytes 1099511627776
spark.sql.files.openCostInBytes 1099511627776
上面所示的示例替代了五个 Spark 配置参数的多个默认值。 这些值分别是压缩编解码器、Apache Hadoop MapReduce 拆分的最小大小和 Parquet 块大小。 同时也是 Spark SQL 分区和打开文件大小默认值。 之所以选择这些配置更改,是因为关联的数据和作业(在此示例中为基因组数据)具有特定的特征。 使用这些自定义配置设置,这些特征会表现得更好。
查看群集配置设置
在群集上进行性能优化之前,请验证当前的 HDInsight 群集配置设置。 通过单击 Spark 群集窗格上的 Dashboard 链接,从 Azure 门户启动 HDInsight 仪表板。 使用群集管理员的用户名和密码登录。
此时会显示 Apache Ambari Web UI,其中的仪表板显示了重要的群集资源使用指标。 Ambari 仪表板显示 Apache Spark 配置,以及安装的其他服务。 仪表板包含“配置历史记录”选项卡,可在其中查看已安装服务(包括 Spark)的信息。
若要查看 Apache Spark 的配置值,请依次选择“配置历史记录”、“Spark2”。 选择配置选项卡,然后在服务列表中选择Spark(或Spark2,取决于版本)链接。 此时会显示群集的配置值列表:
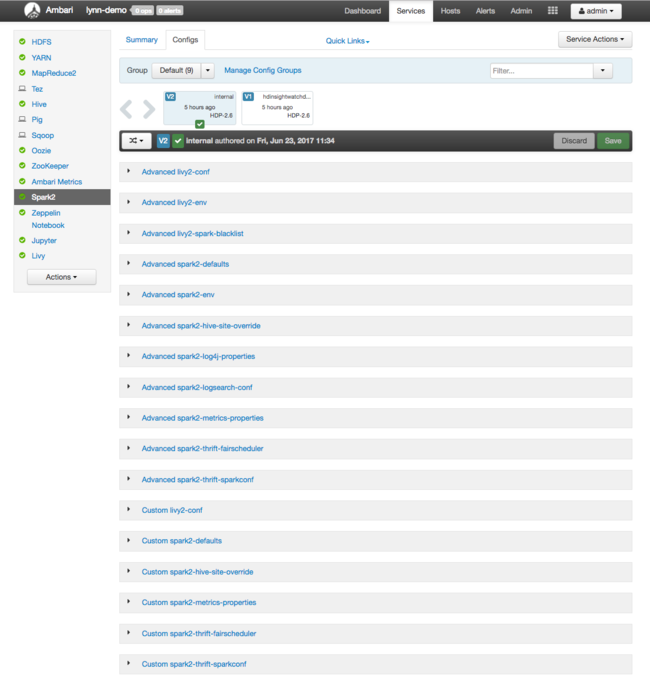
若要查看和更改单个 Spark 配置值,请选择标题中包含“spark”的任何链接。 Spark 配置包括以下类别的自定义配置值和高级配置值:
- 自定义 “Spark2-defaults”
- 自定义 “Spark2-metrics-properties”
- 高级 Spark2-defaults
- 高级 Spark2 环境
- 高级 spark2-hive-site-覆盖设置
如果创建一组非默认配置值,则更新历史记录可见。 借助此配置历史记录可以确定哪个非默认配置具有最佳性能。
注意
若要查看但不更改常用的 Spark 群集配置设置,请在顶层“Spark 作业 UI”界面上选择“环境”选项卡。
配置 Spark 执行器
下图显示了关键的 Spark 对象:驱动程序及其关联的 Spark 上下文,以及群集管理器及其 n 个 工作节点。 每个工作节点包括执行器、缓存和 n 个 任务实例。
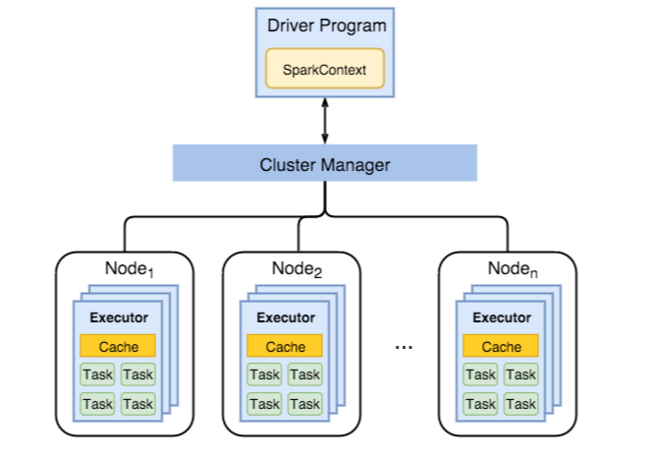
Spark 作业使用辅助角色资源(具体而言是内存),因此,我们往往会调整工作节点执行器的 Spark 配置值。
我们经常调整 spark.executor.instances、spark.executor.cores 和 spark.executor.memory 这三个关键参数来优化 Spark 配置,以改善应用程序要求。 执行器是针对 Spark 应用程序启动的进程。 执行器在工作节点上运行,负责执行应用程序的任务。 工作器节点数量和工作器节点大小决定执行程序数量和执行程序大小。 这些值存储在群集头节点的 spark-defaults.conf 中。 可以在 Ambari 的 Web UI 中选择“自定义 spark-defaults”,以编辑正在运行的集群中的这些值。 做出更改后,UI 会提示重启所有受影响的服务。
注意
这三个配置参数可在群集级别配置(适用于群集中运行的所有应用程序),也可以针对每个应用程序指定。
Spark 执行程序使用的资源的另一个信息源是 Spark 应用程序 UI。 在 UI 中,“执行程序”显示有关配置和已使用资源的“摘要”和“详细信息”视图。 确定是更改整个群集的执行程序值,还是更改一组特定的作业执行操作。
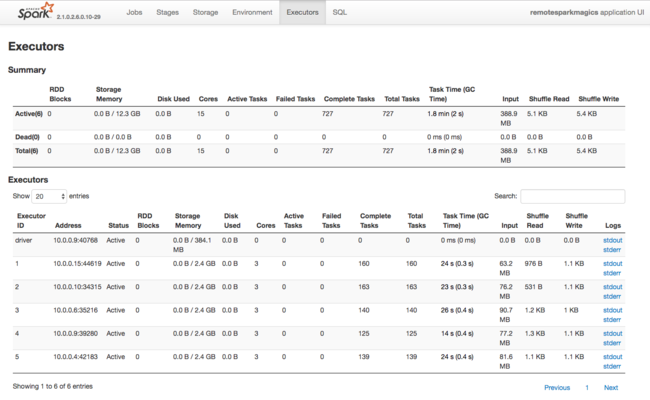
或者,可以使用 Ambari REST API 以编程方式验证 HDInsight 和 Spark 群集的配置设置。 有关详细信息,请参阅 Apache Ambari API 参考GitHub。
根据 Spark 群集工作负荷,可以确定某个非默认 Spark 配置是否提供更优化的 Spark 作业执行。 使用示例工作负荷执行基准测试,以验证任何非默认群集配置。 下面是可以考虑调整的一些常见参数:
| 参数 | 说明 |
|---|---|
| --num-executors | 设置执行程序数量。 |
| --executor-cores | 设置每个执行程序的核心数。 我们建议使用中等大小的执行器,因为其他进程也会占用一部分可用内存。 |
| --executor-memory | 控制 Apache Hadoop YARN 上每个执行器的内存大小(堆大小),并且你需要留出一些内存以供执行开销使用。 |
下面是使用不同配置值的两个工作节点的示例:

以下列表显示关键的 Spark 执行器内存参数。
| 参数 | 说明 |
|---|---|
| spark.executor.memory | 定义执行程序可用的内存总量。 |
| spark.storage.memoryFraction | (默认为大约 60%)定义可用于存储持久性 RDD 的内存量。 |
| spark.shuffle.memoryFraction | (默认为约 20%)定义保留给数据重排的内存量。 |
| spark.storage.unrollFraction 和 spark.storage.safetyFraction | (合计为总内存的大约 30%)- 这些值由 Spark 在内部使用,不应更改。 |
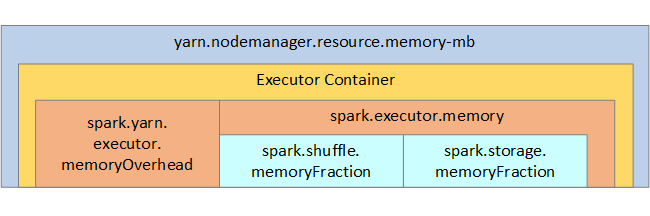
YARN 控制每个 Spark 节点上的容器使用的最大内存量总计。 下图显示了 YARN 配置对象与 Spark 对象之间的节点关系。
更改Jupyter Notebook中运行的应用程序的参数
HDInsight 中的 Spark 群集默认包含许多组件。 其中每个组件包含可按需替代的默认配置值。
| 组件 | 说明 |
|---|---|
| Spark Core | Spark Core、Spark SQL、Spark 流式处理 API、GraphX 和 Apache Spark MLlib。 |
| Anaconda | Python包管理器。 |
| Apache Livy | Apache Spark REST API,用于将远程作业提交到 HDInsight Spark 群集。 |
| Jupyter 笔记本和 Apache Zeppelin 笔记本 | 用来与 Spark 群集交互的基于浏览器的交互式 UI。 |
| ODBC 驱动程序 | 将 HDInsight 中的 Spark 群集连接到商业智能(BI)工具,例如Microsoft Power BI和 Tableau。 |
对于在Jupyter Notebook中运行的应用程序,请使用 %%configure 命令从笔记本本身中进行配置更改。 这些配置更改将应用到从 Notebook 实例运行的 Spark 作业。 先在应用程序的开头进行此类更改,然后再运行第一个代码单元。 创建 Livy 会话时,会将更改的配置应用到该会话。
注意
若要更改处于应用程序中后面某个阶段的配置,请使用 -f (force) 参数。 但是,应用程序中的所有进度将会丢失。
下面的代码演示如何更改在Jupyter Notebook中运行的应用程序的配置。
%%configure
{"executorMemory": "3072M", "executorCores": 4, "numExecutors":10}
结论
监视核心配置设置,以确保 Spark 作业以可预测且高效的方式运行。 这些设置可帮助确定特定工作负荷的最佳 Spark 群集配置。 此外,还需要监视长时间运行且/或消耗大量资源的 Spark 作业的执行情况。 最常见的难题集中在不正确的配置(例如执行程序的大小不正确)引起的内存压力上。 此外还有长时间运行的操作以及会导致笛卡尔运算的任务。