Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
本文介绍了如何在 HDInsight 中使用企业安全性套餐为 Spark SQL 配置 Apache Ranger 策略。
在本文中,学习如何:
- 创建 Apache Ranger 策略。
- 验证所应用的 Ranger 策略。
- 应用为 Spark SQL 设置 Apache Ranger 的指南。
先决条件
- HDInsight 版本 5.1 中采用企业安全性套餐的 Apache Spark 群集
连接到 Apache Ranger 管理员 UI
在浏览器中,使用 URL
https://ClusterName.azurehdinsight.cn/Ranger/连接到 Ranger 管理用户界面。将
ClusterName更改为 Spark 群集的名称。使用 Microsoft Entra 管理员凭据登录。 Microsoft Entra 管理员凭据与 HDInsight 群集凭据或 Linux HDInsight 节点安全外壳 (SSH) 凭据不同。
创建域用户
若要了解如何创建 sparkuser 域用户,请参阅创建具有 ESP 的 HDInsight 群集。 在生产场景中,域用户来自 Microsoft Entra 租户。
创建 Ranger 策略
在此部分中,需要创建两个 Ranger 策略:
- 用于从 Spark SQL 访问
hivesampletable的访问策略 - 用于在
hivesampletable中模糊处理列的屏蔽策略
创建 Ranger 访问策略
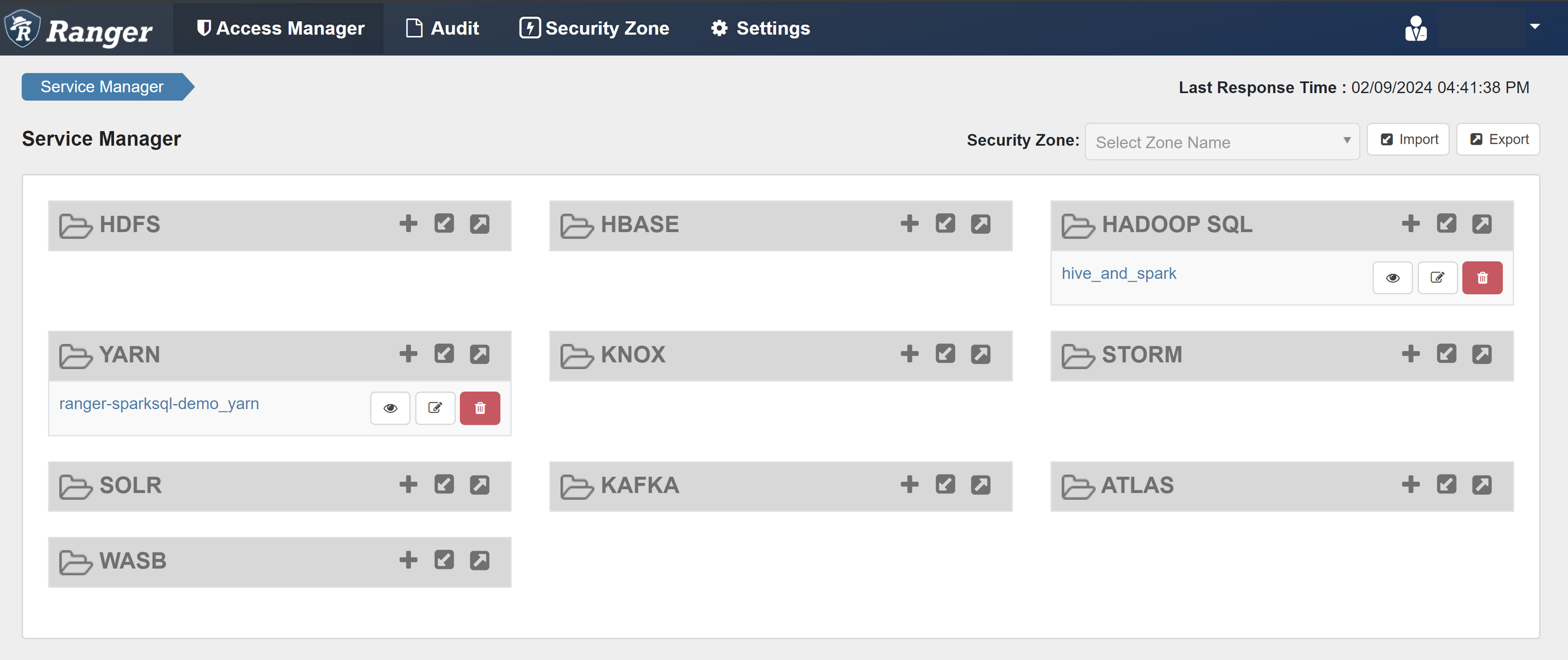
打开 Ranger 管理员 UI。
在“HADOOP SQL”下,选择“hive_and_spark”。
在“访问”选项卡上,选择“添加新策略”。
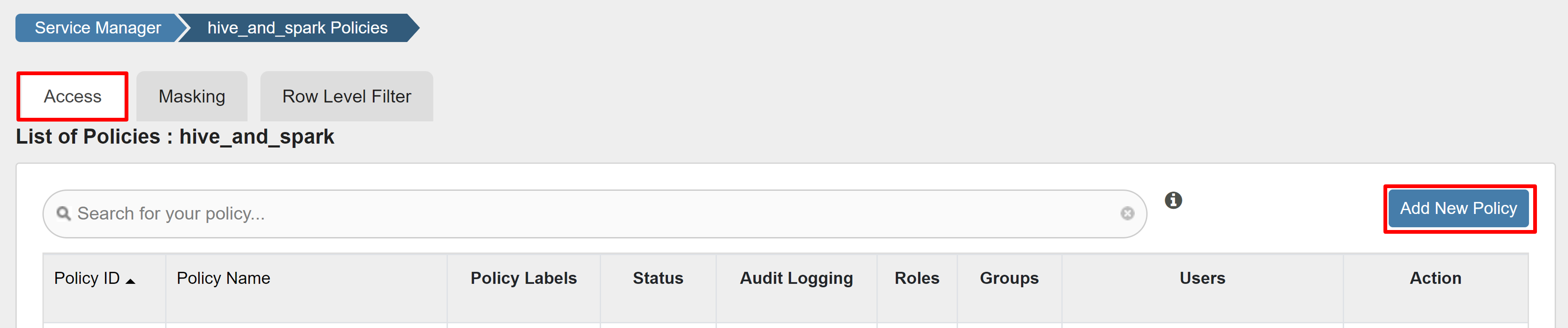
输入以下值:
属性 值 策略名称 read-hivesampletable-all database 默认值 表 hivesampletable 列 * 选择用户 sparkuser权限 SELECT… 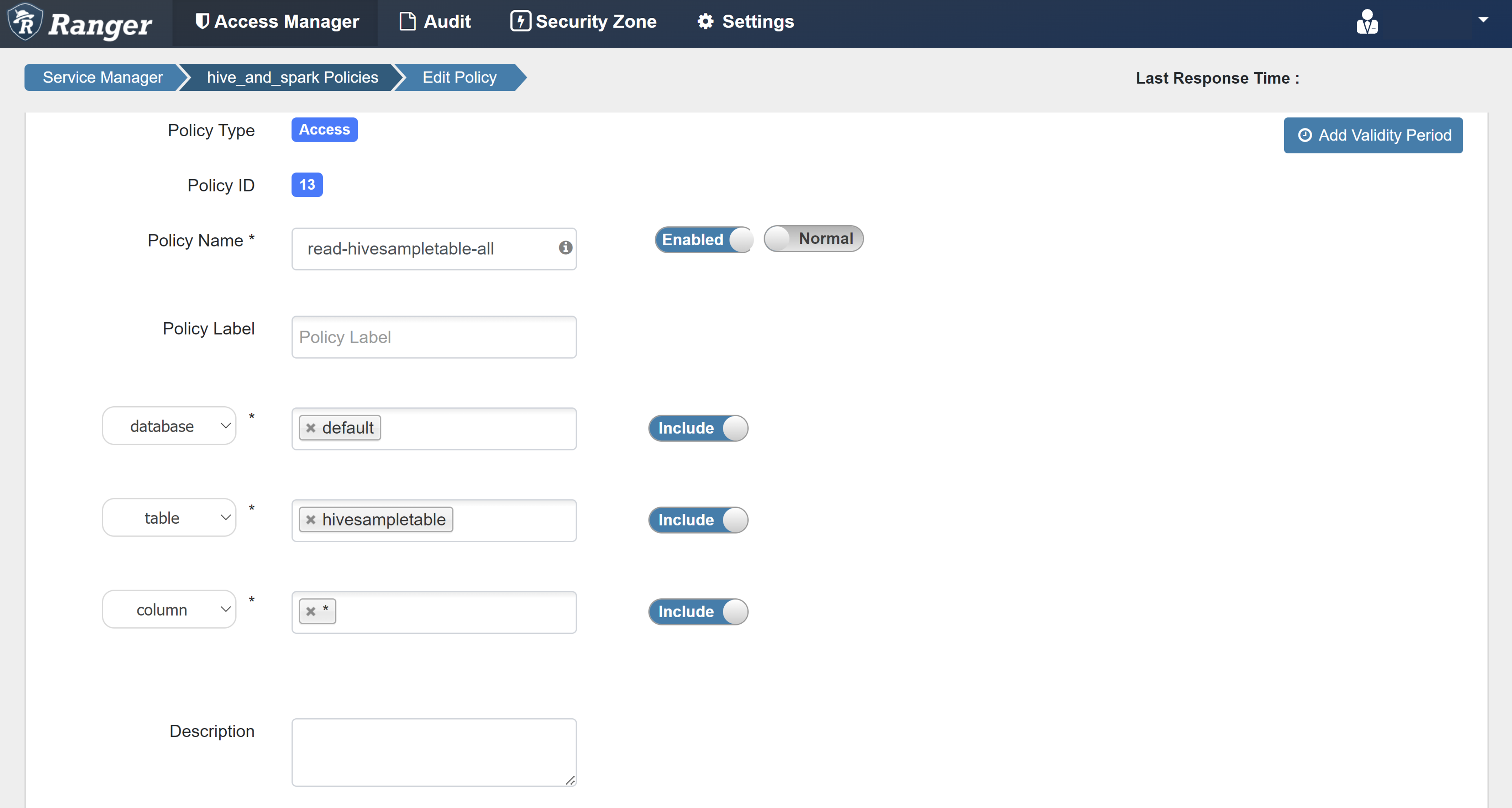
如果选择用户未自动填充域用户,请稍等,以便 Ranger 与 Microsoft Entra ID 同步。
选择“添加”以保存策略。
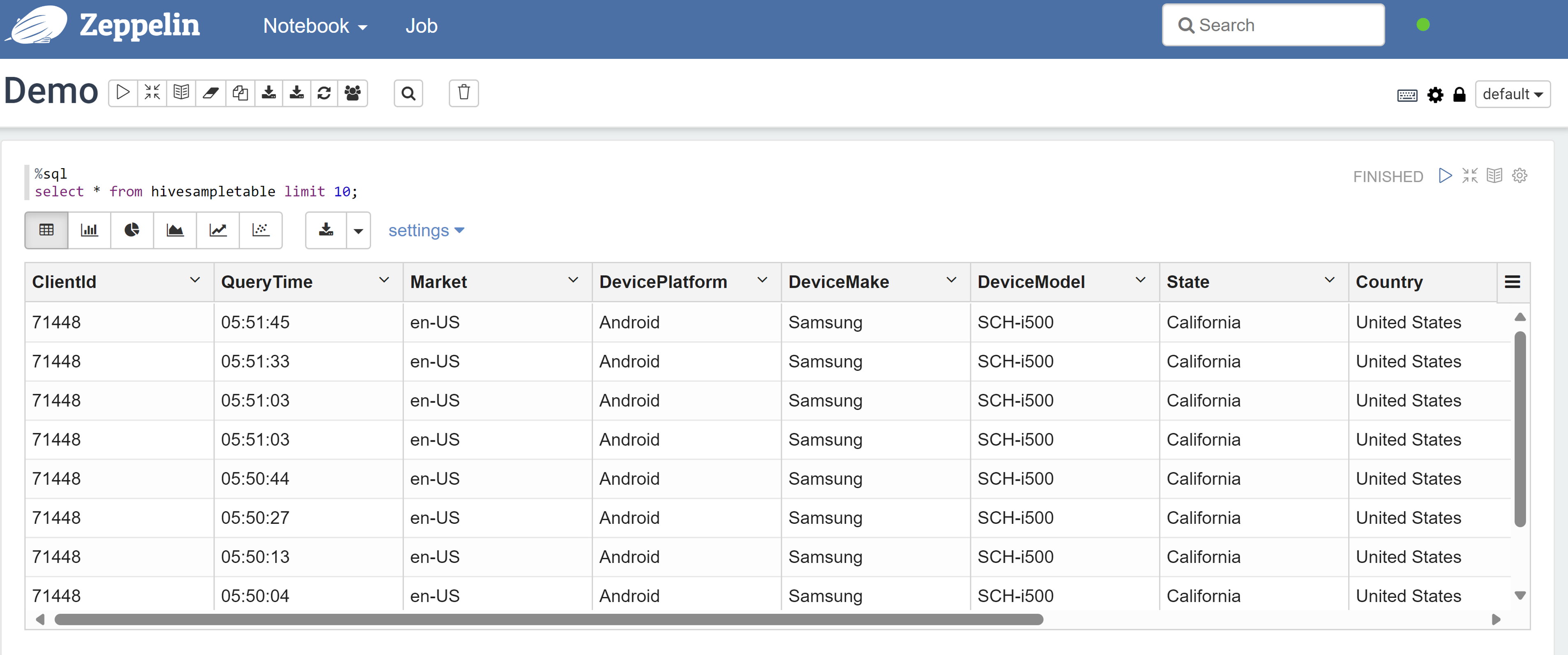
打开 Zeppelin 笔记本,并运行以下命令来验证策略:
%sql select * from hivesampletable limit 10;下面是应用策略之前的结果:
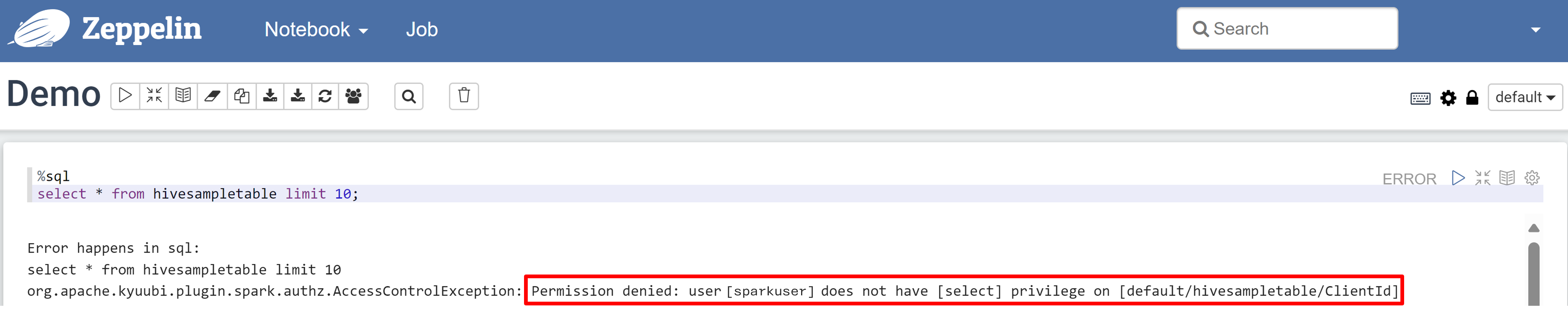
下面是应用策略之后的结果:




创建 Ranger 屏蔽策略
以下示例演示了如何创建策略来屏蔽列:
在“屏蔽”选项卡上,选择“添加新策略”。
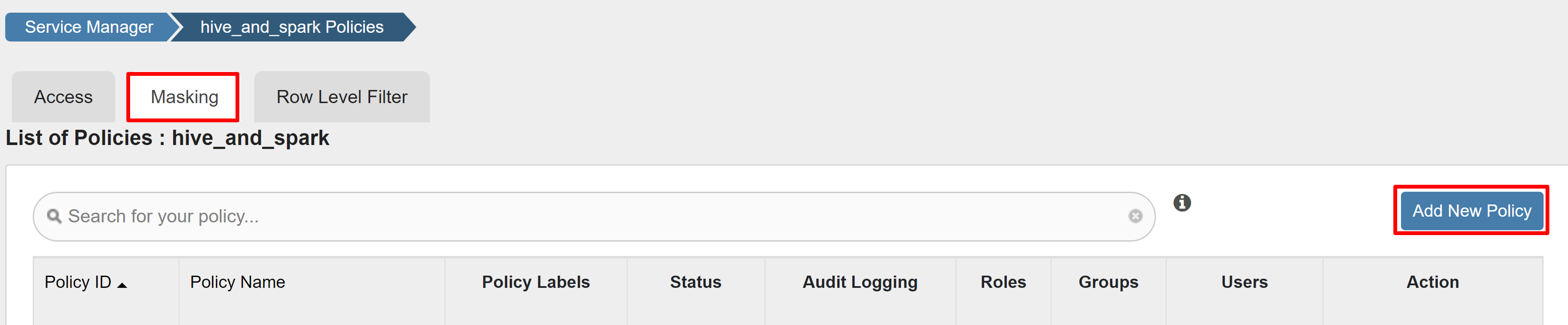
输入以下值:
属性 值 策略名称 mask-hivesampletable Hive 数据库 默认值 Hive 表 hivesampletable Hive 列 devicemake 选择用户 sparkuser访问类型 SELECT… 选择屏蔽选项 哈希 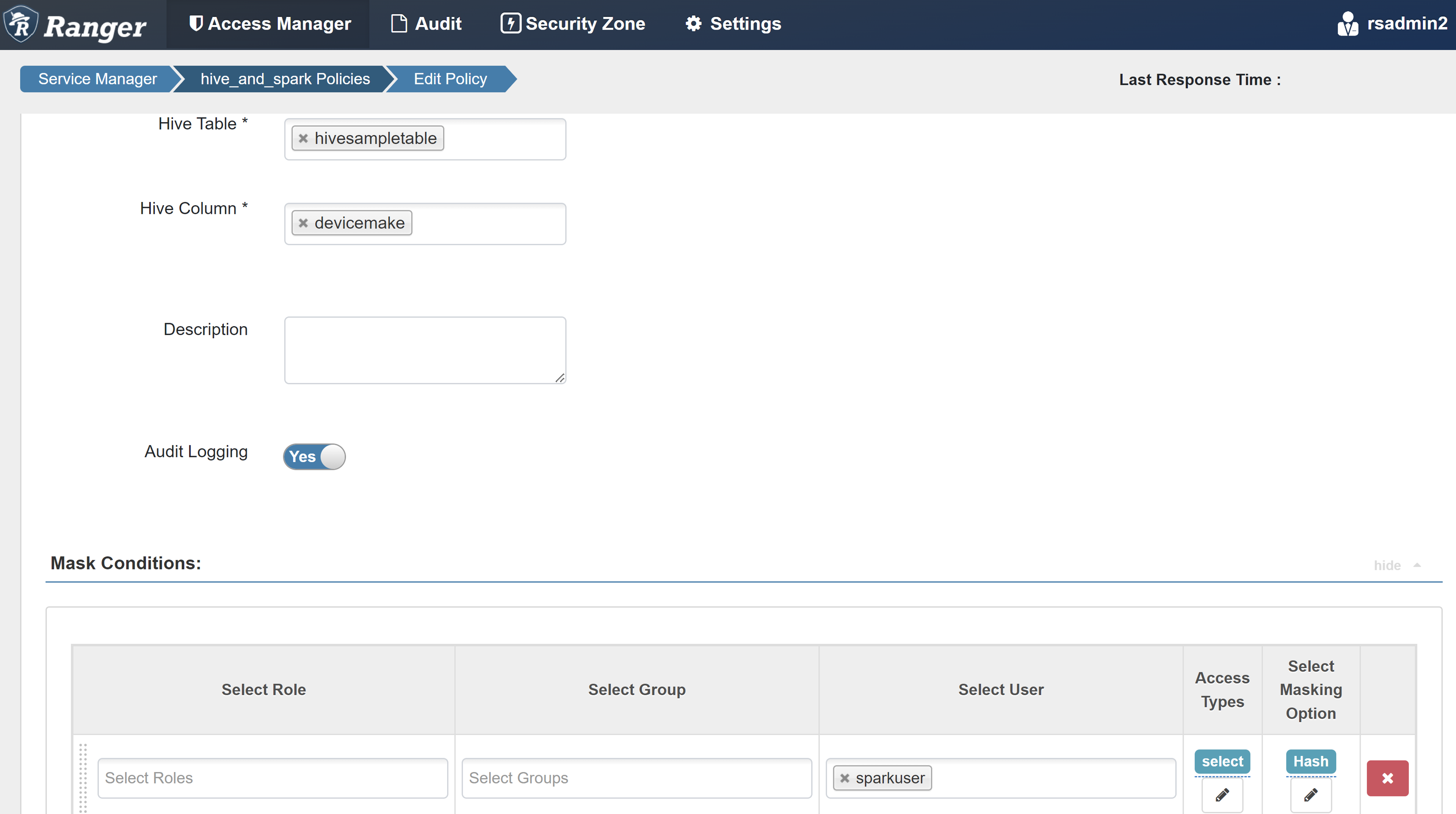
选择“保存”以保存策略。
打开 Zeppelin 笔记本,并运行以下命令来验证策略:
%sql select clientId, deviceMake from hivesampletable;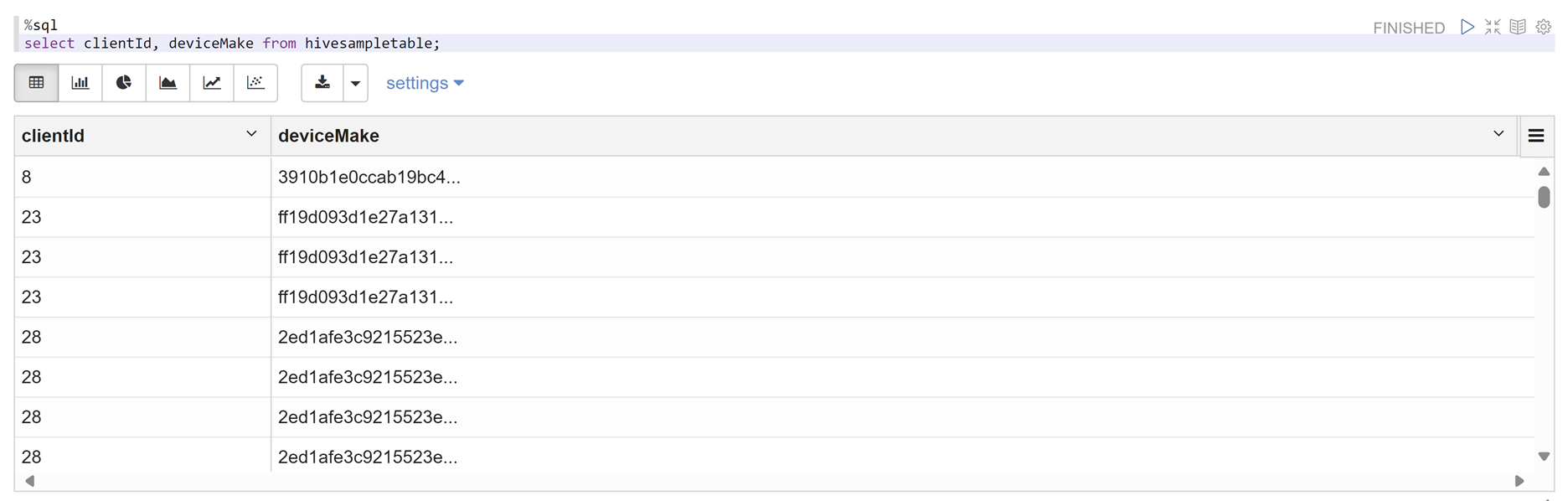



注意
默认情况下,Hive 和 Spark SQL 的策略在 Ranger 中很常见。
应用为 Spark SQL 设置 Apache Ranger 的指南
以下场景探讨了使用新的 Ranger 数据库和现有 Ranger 数据库创建 HDInsight 5.1 Spark 群集的准则。
场景 1:在创建 HDInsight 5.1 Spark 群集时使用新的 Ranger 数据库
使用新的 Ranger 数据库创建群集时,将在 Ranger 数据库的 Hadoop SQL 服务中使用名称hive_and_spark创建包含 Hive 和 Spark 的 Ranger 策略的相关 Ranger 存储库。

如果编辑策略,它们将同时应用于 Hive 和 Spark。
请考虑以下几点:
如果有两个元存储数据库,它们对 Hive(例如DB1)目录和 Spark 目录使用相同的名称(例如DB1):
- 如果 Spark 使用 Spark 目录 (
metastore.catalog.default=spark),则策略会应用于 Spark 目录的DB1数据库。 - 如果 Spark 使用 Hive 目录 (
metastore.catalog.default=hive),则策略会应用于 Hive 目录的DB1数据库。
从 Ranger 的角度来看,无法区分 Hive 目录和 Spark 目录的DB1。
在这种情况下,建议:
- 将 Hive 目录用于 Hive 和 Spark。
- 为 Hive 和 Spark 目录维护不同的数据库名称、表名和列名,这样策略就不会跨目录应用于数据库。
- 如果 Spark 使用 Spark 目录 (
如果将 Hive 目录用于 Hive 和 Spark,请考虑以下示例。
假设使用当前xyz用户通过 Hive 创建名为table1的表。 它创建名为table1.db的 Hadoop 分布式文件系统 (HDFS) 文件,其所有者是xyz用户。
现在,假设使用用户abc启动 Spark SQL 会话。 在用户abc的此会话中,如果尝试将任何内容写入table1,操作肯定会失败,因为表所有者是xyz。
在这种情况下,建议在 Hive 和 Spark SQL 中使用同一用户更新表。 该用户应具有足够的权限来执行更新操作。
场景 2:在创建 HDInsight 5.1 Spark 群集时使用现有的 Ranger 数据库(具有现有策略)
使用现有的 Ranger 数据库创建 HDI 5.1 群集时,会在此数据库上再次新建 Ranger 存储库,新群集的名称采用此格式:hive_and_spark。

假设你已经在 Hadoop SQL 服务中的现有 Ranger 数据库上使用oldclustername_hive名称在 Ranger 存储库中定义了策略。 你想要在新的 HDInsight 5.1 Spark 群集中共享相同的策略。 要实现此目标,请使用以下步骤。
注意
拥有 Ambari 管理员权限的用户可以执行配置更新。
从新的 HDInsight 5.1 群集打开 Ambari UI。
转到Spark3服务,然后转到配置。
打开高级 ranger-spark-security配置。
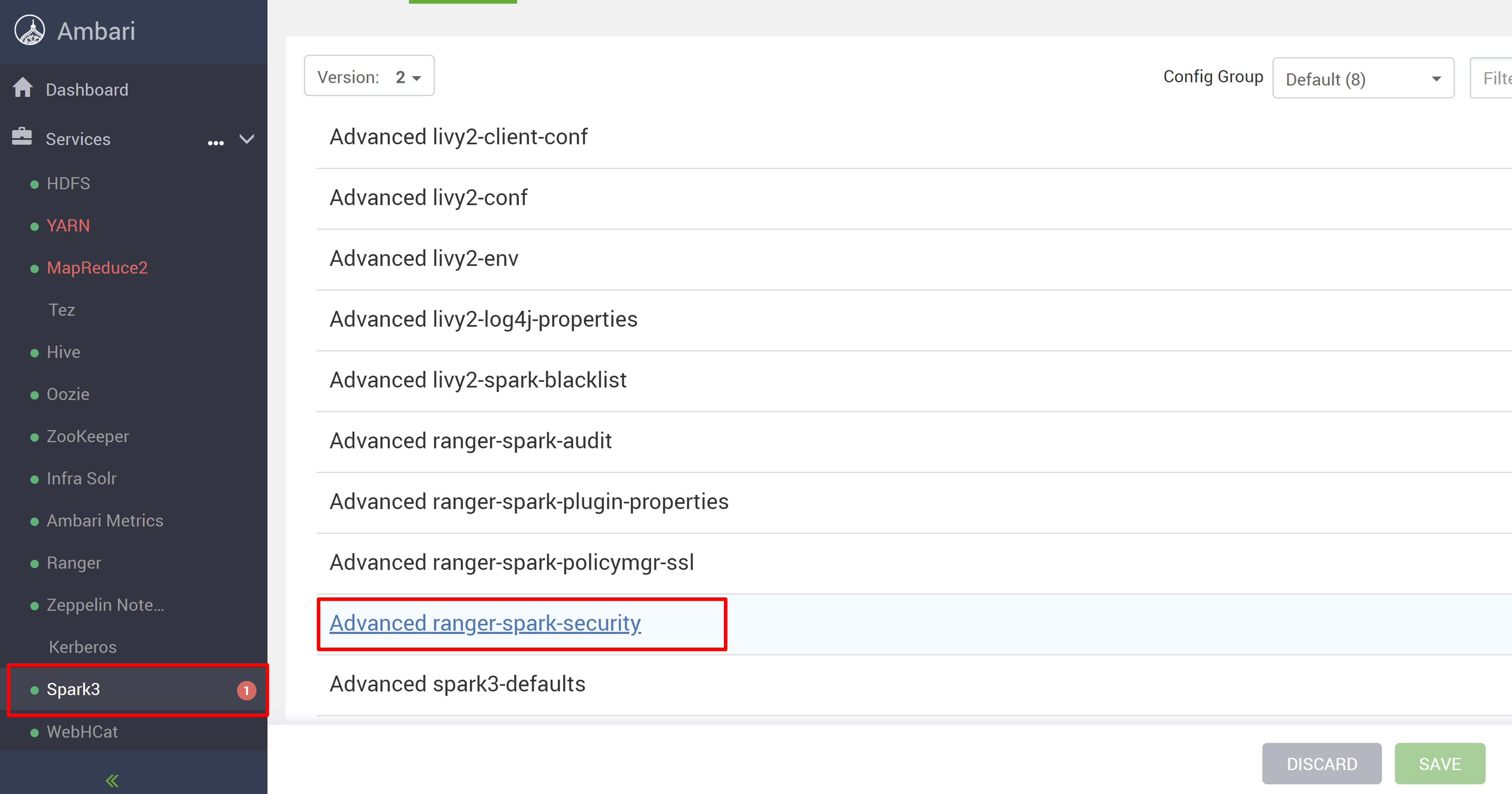
或者,还可以使用 SSH 在 /etc/spark3/conf 中打开此配置。
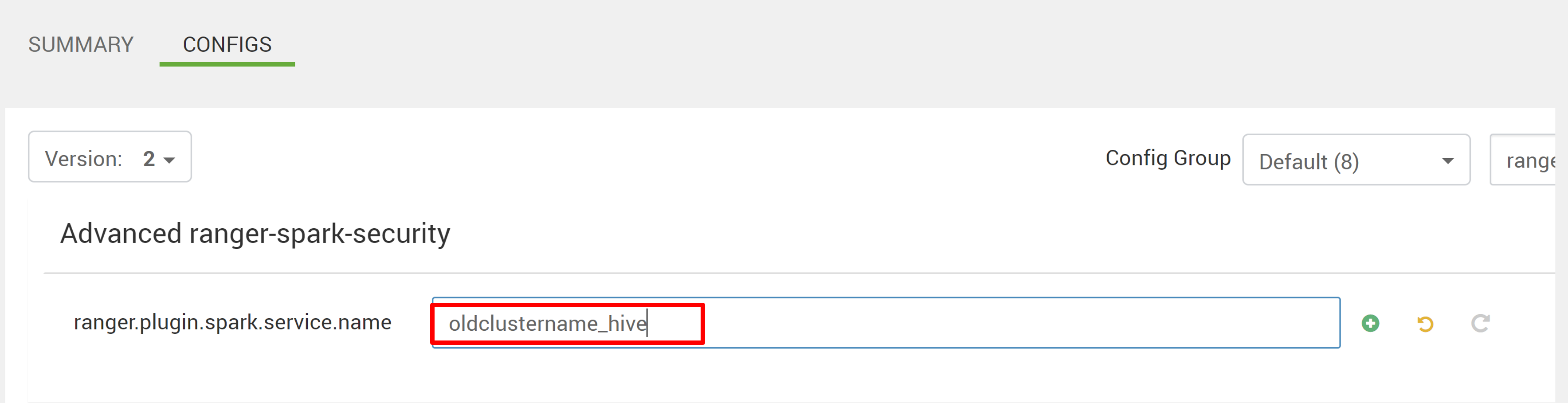
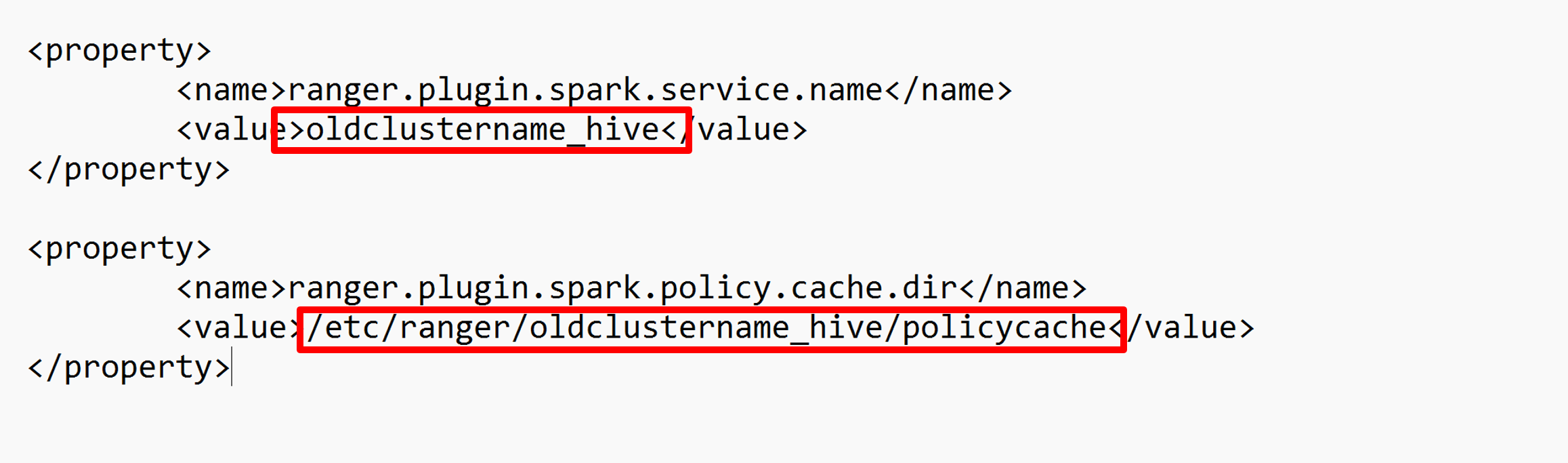
编辑两个配置(ranger.plugin.spark.service.name和ranger.plugin.spark.policy.cache.dir)以指向旧策略存储库oldclustername_hive,然后保存配置。
Ambari:
XML 文件:
从 Ambari 重启 Ranger 和 Spark 服务。
打开 Ranger 管理员 UI,然后单击 HADOOP SQL 服务下的“编辑”按钮。
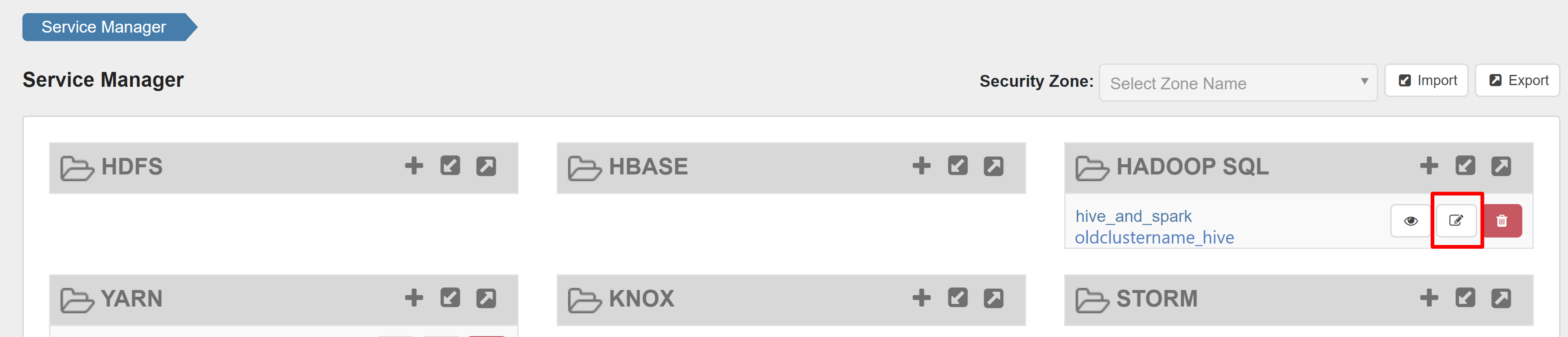
对于 oldclustername_hive 服务,请在 policy.download.auth.users 和 tag.download.auth.users 列表中添加 rangersparklookup 用户,然后单击“保存”。






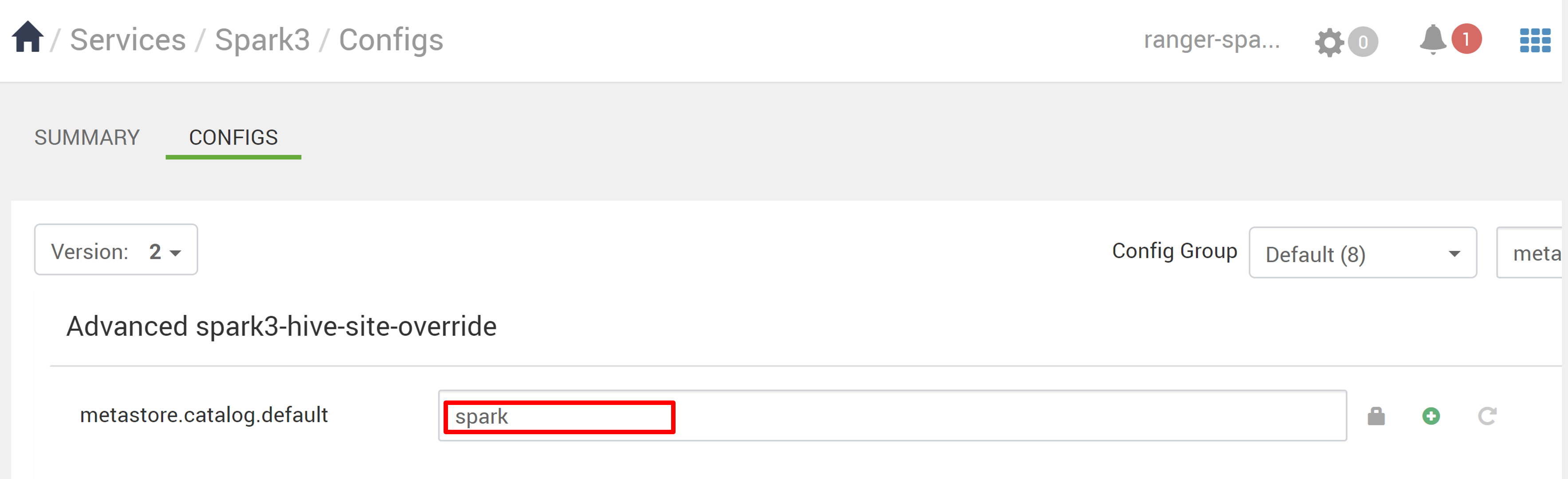
策应用于 Spark 目录中的数据库。 如果要访问 Hive 目录中的数据库:
在 Ambari 中,转到Spark3>配置。
将metastore.catalog.default从spark更改为hive。

已知问题
- 如果 Ranger 管理员关闭,Apache Ranger 与 Spark SQL 的集成不起作用。
- 在 Ranger 审核日志中,将鼠标悬停在“资源”列上时,无法显示所运行的全部查询。