Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
若要处理交互式 Azure 机器学习笔记本数据整理,可以使用 Azure 机器学习与 Azure Synapse Analytics 的集成轻松访问 Apache Spark 框架。 进行这种访问可以实现 Azure 机器学习笔记本交互式数据整理。
本快速入门指南介绍如何使用 Azure 机器学习无服务器 Spark 计算、Azure Data Lake Storage (ADLS) Gen 2 存储帐户和用户标识传递执行交互式数据整理。
先决条件
- 一个 Azure 订阅;如果你没有 Azure 订阅,请在开始之前创建一个试用帐户。
- 一个 Azure 机器学习工作区。 请访问创建工作区资源。
- Azure Data Lake Storage (ADLS) Gen 2 存储帐户。 请访问创建 Azure Data Lake Storage (ADLS) Gen 2 存储帐户。
将 Azure 存储帐户凭据作为机密存储在 Azure 密钥保管库
要使用 Azure 门户用户界面将 Azure 存储帐户凭据作为机密存储在 Azure 密钥保管库中:
在 Azure 门户中,导航到 Azure Key Vault
在左窗格中选择“机密”
选择“+ 生成/导入”
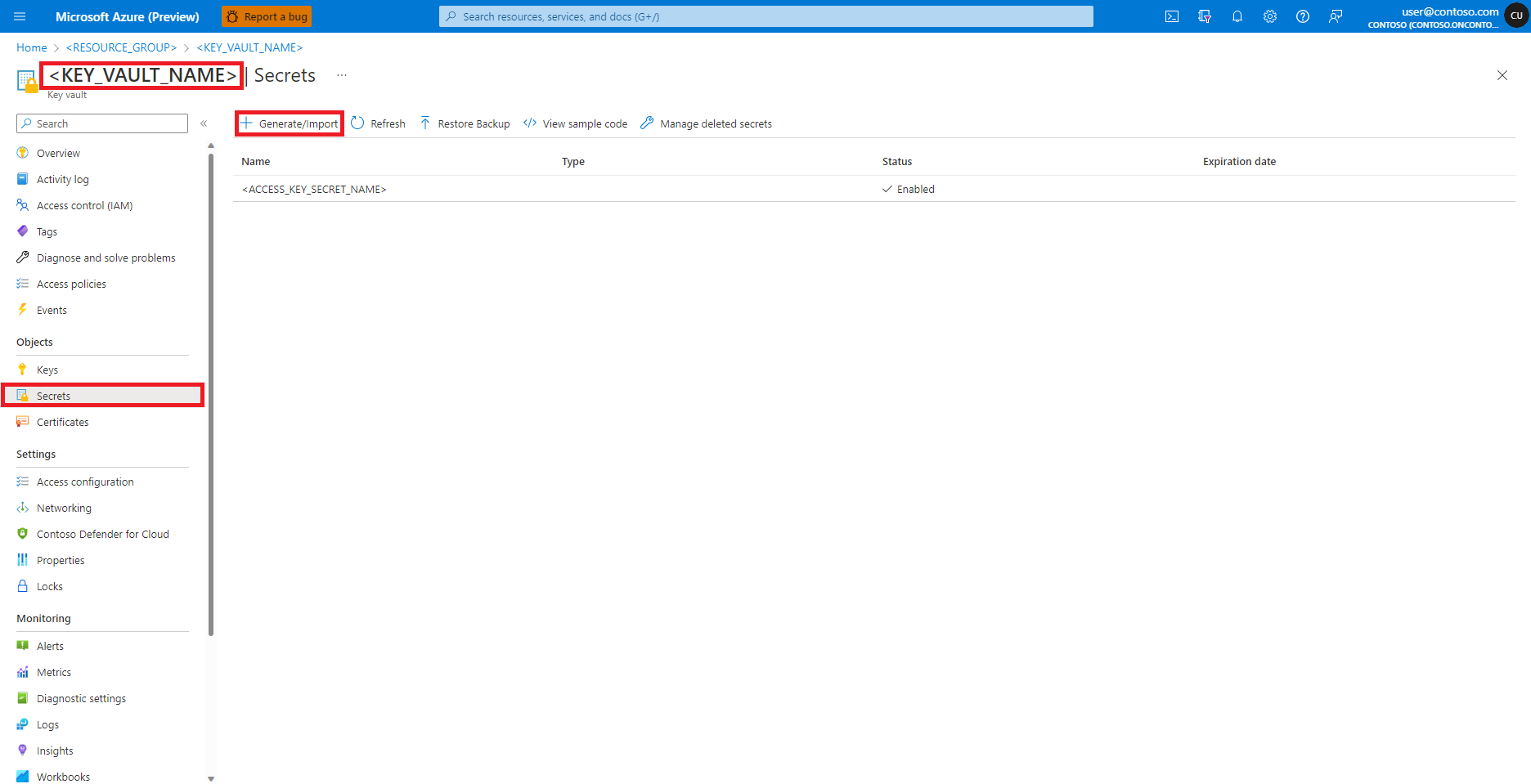
在“创建机密”屏幕上,输入要创建的机密的名称
在 Azure 门户中导航到 Azure Blob 存储帐户,如下图所示:
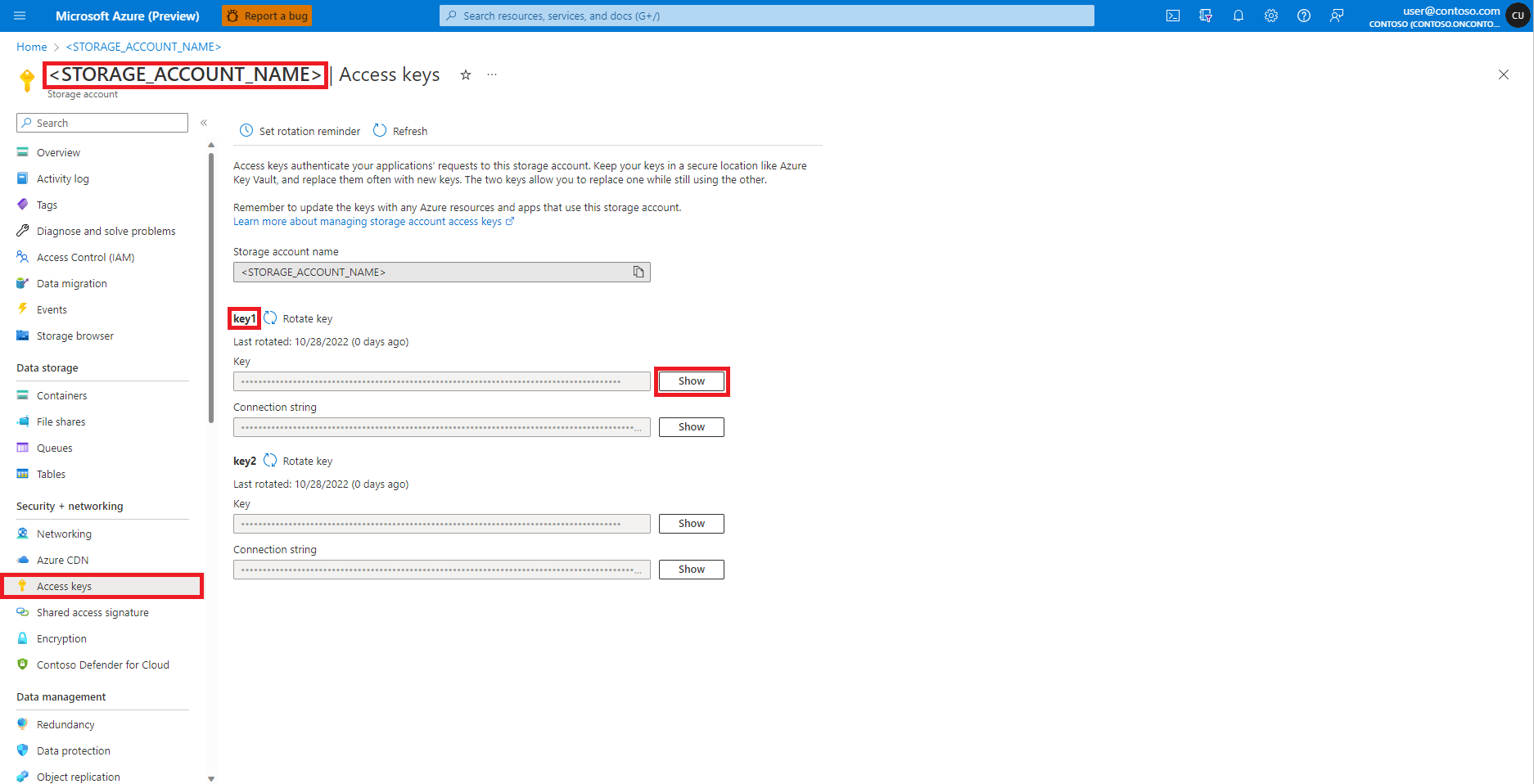
从“Azure Blob 存储帐户”页面左侧面板中选择“访问密钥”
选择“密钥 1”旁边的“显示”,然后选择“复制到剪贴板”以获取存储帐户访问密钥
注意
选择适当的选项进行复制
- Azure Blob 存储容器共享访问签名 (SAS) 令牌
- Azure Data Lake Storage (ADLS) Gen 2 存储帐户服务主体凭据
- 租户 ID
- 客户端 ID 和
- secret
创建 Azure 密钥保管库机密时各自的用户界面上
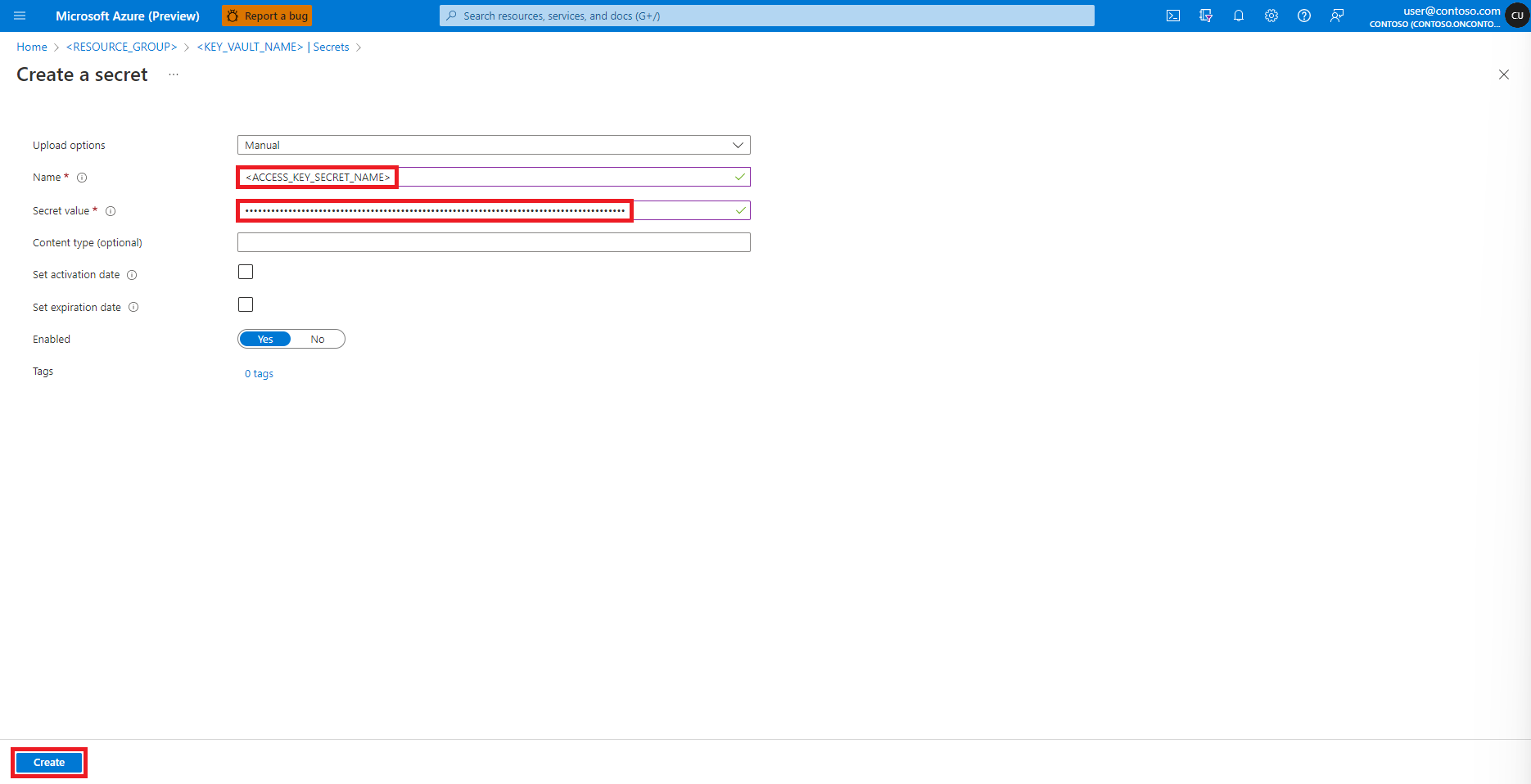
导航回“创建机密”屏幕
在“机密值”文本框中,输入 Azure 存储帐户的访问密钥凭据,该凭据在前面的步骤中已复制到剪贴板
选择“创建”
提示
Azure CLI 和适用于 Python 的 Azure 密钥保管库机密客户端库也可以创建 Azure 密钥保管库机密。
在 Azure 存储帐户中添加角色分配
在开始进行交互式数据整理之前,必须确保输入和输出数据路径可访问。 首先,对于
笔记本会话登录用户的用户标识
或
服务主体
将“读取者”和“存储 Blob 数据读取者”角色分配给已登录用户的用户标识。 但在某些情况下,我们可能需要将整理的数据写回到 Azure 存储帐户。 “读取者”角色和“存储 Blob 数据读取者”角色提供对用户标识或服务主体的只读访问权限。 若要启用读取和写入访问权限,请将“参与者”角色和“存储 Blob 数据参与者”角色分配给用户标识或服务主体。 要为用户标识分配适当的角色,请执行以下操作:
打开 Azure 门户
搜索并选择“存储帐户”服务

在“存储帐户”页面上,从列表中选择 Azure Data Lake Storage (ADLS) Gen 2 存储帐户。 此时将打开显示存储帐户概述的页面
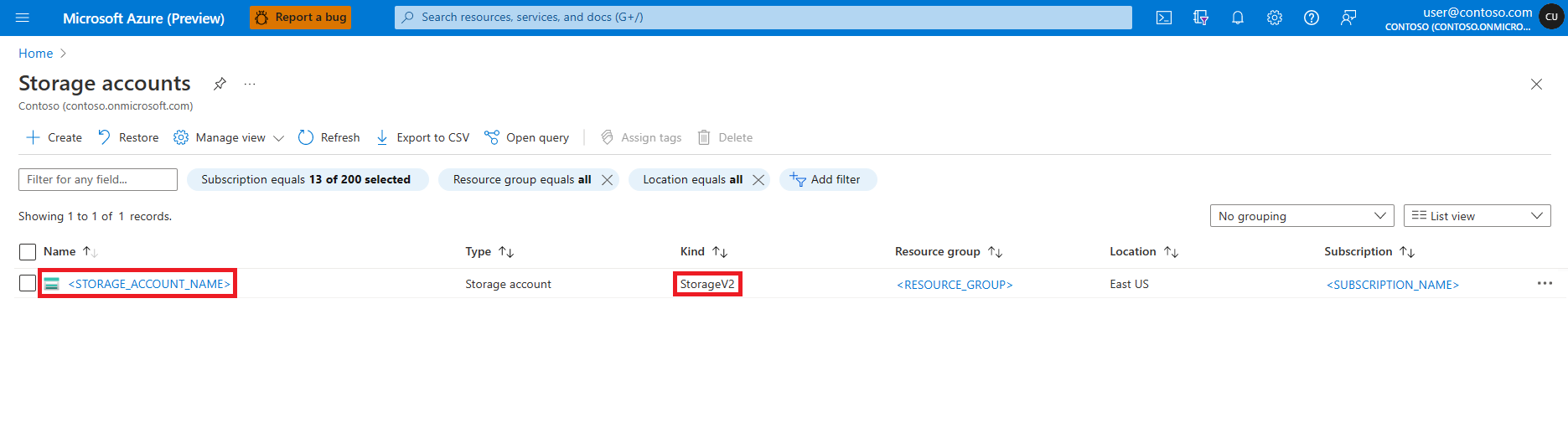
在左侧窗格中选择“访问控制(IAM)”
选择“添加角色分配”
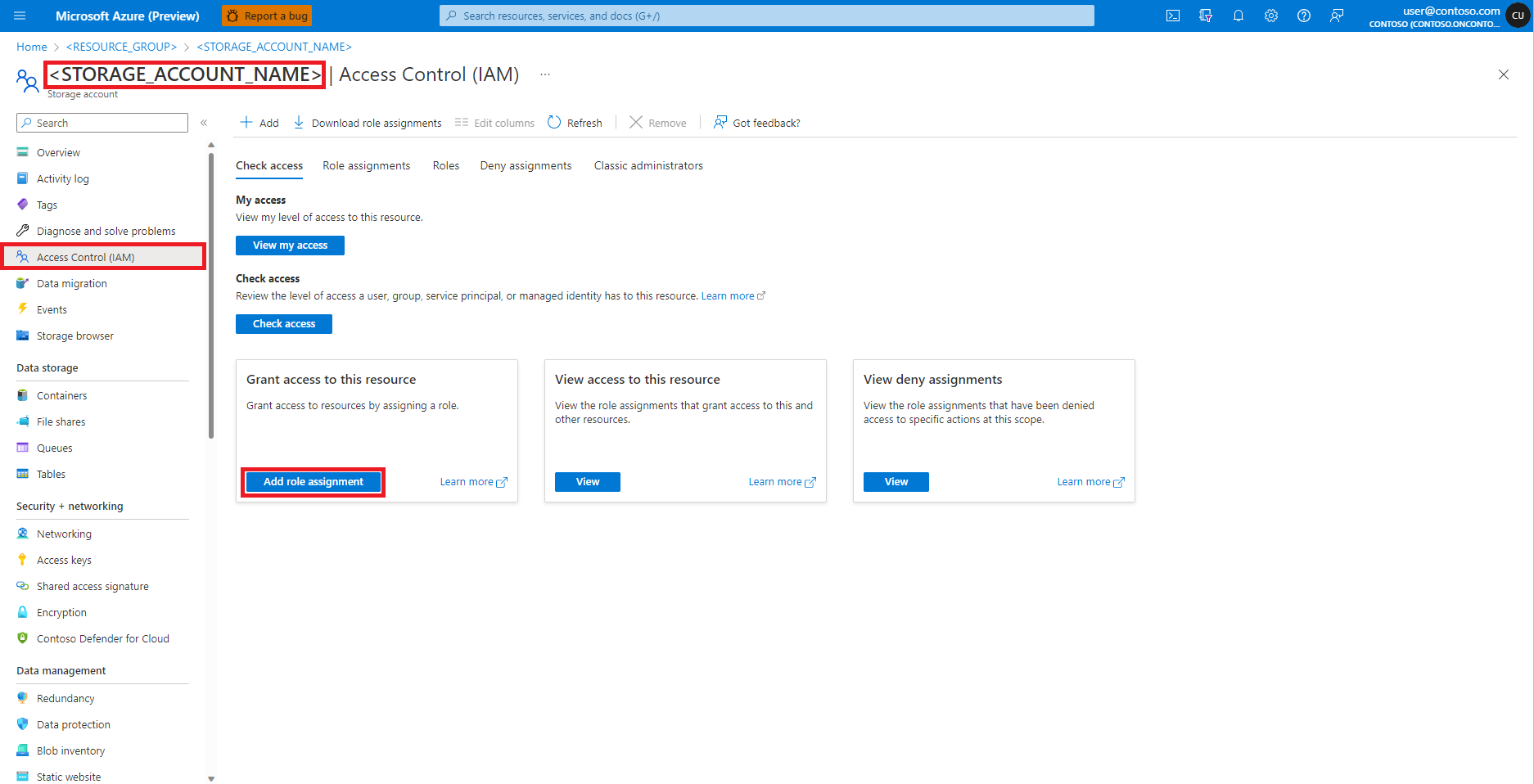
找到并选择角色“存储 Blob 数据参与者”
选择下一个
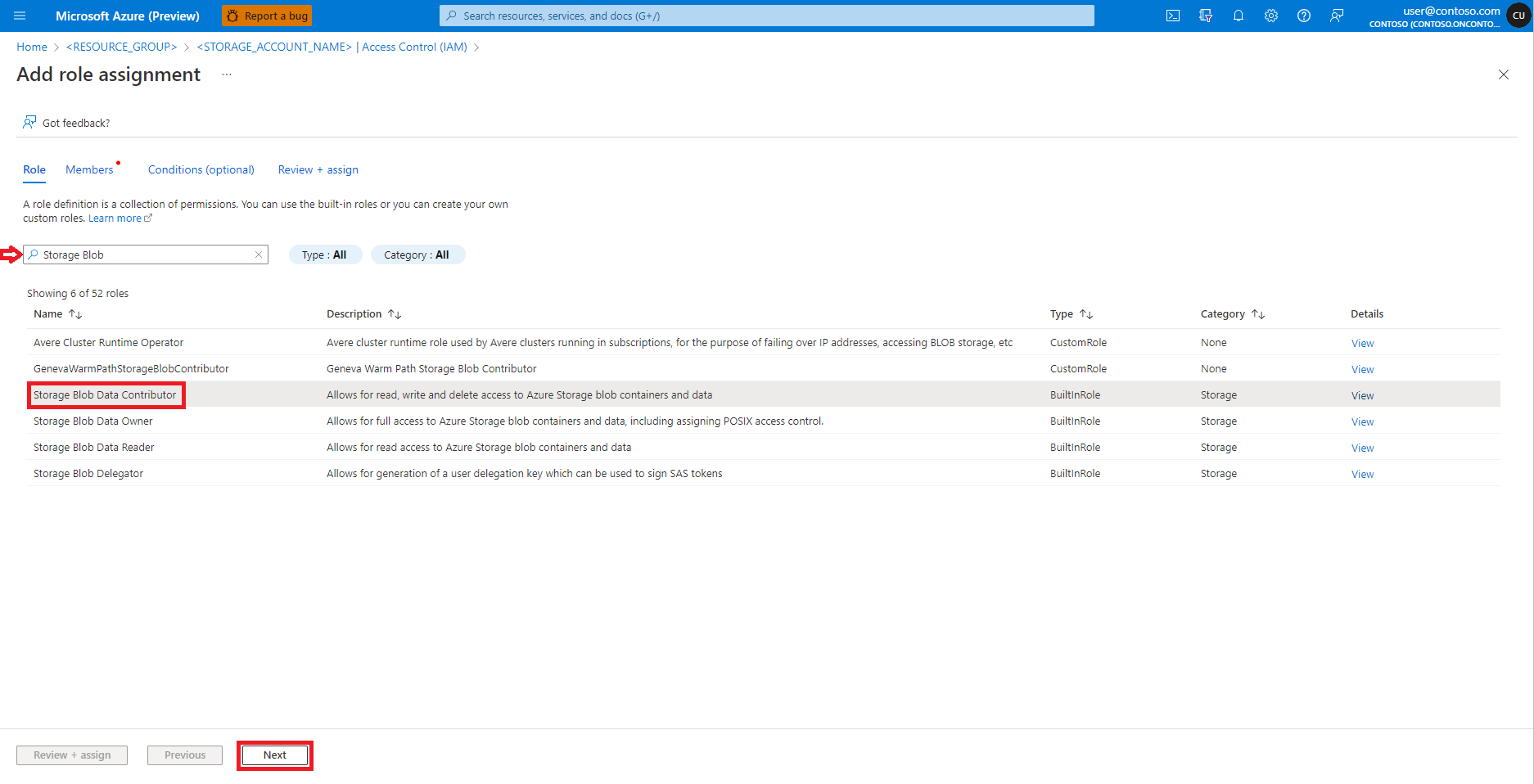
选择“用户、组或服务主体”
选择“+ 选择成员”
在“选择”下面搜索用户标识
从列表中选择该用户标识,使其显示在“所选成员”下
选择适当的用户标识
选择下一个
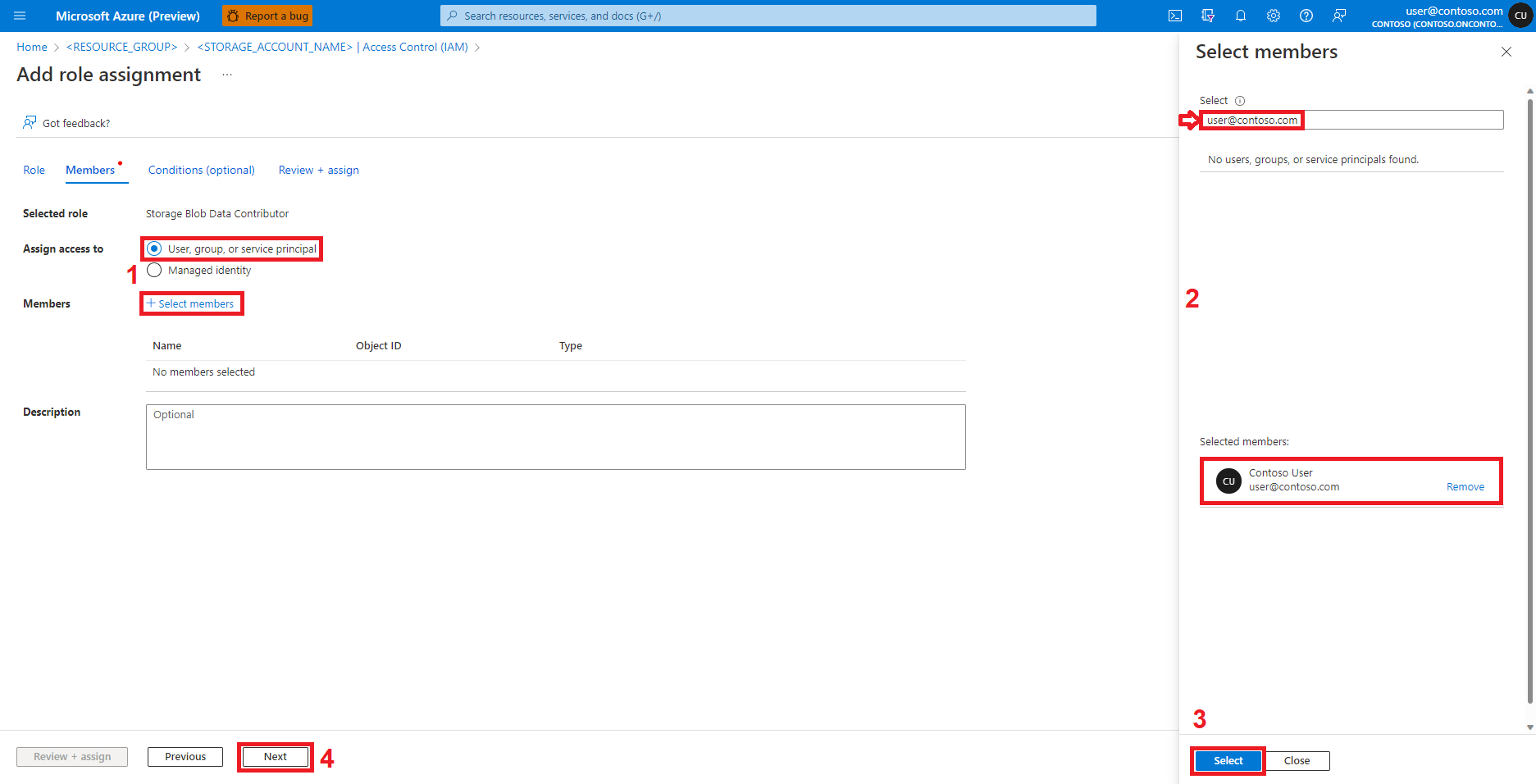
选择“查看 + 分配”
对“参与者”角色分配重复执行步骤 2-13






为用户标识分配适当的角色后,Azure 存储帐户中的数据应该可供访问。
注意
如果附加的 Synapse Spark 池指向关联了托管虚拟网络的 Azure Synapse 工作区中的 Synapse Spark 池,则应配置存储帐户的托管专用终结点,以确保能够访问数据。
确保 Spark 作业的资源访问
Spark 作业可以使用托管标识或用户标识传递来访问数据和其他资源。 下表总结了在使用 Azure 机器学习无服务器 Spark 计算和附加的 Synapse Spark 池时进行资源访问的不同机制。
| Spark 池 | 支持的标识 | 默认标识 |
|---|---|---|
| 无服务器 Spark 计算 | 用户标识,附加到工作区的用户分配的托管标识 | 用户标识 |
| 附加的 Synapse Spark 池 | 用户标识,附加到所附加的 Synapse Spark 池的用户分配的托管标识,所附加的 Synapse Spark 池的系统分配的托管标识 | 所附加的 Synapse Spark 池的系统分配的托管标识 |
如果 CLI 或 SDK 代码定义了一个使用托管标识的选项,则 Azure 机器学习无服务器 Spark 计算会依赖附加到工作区的用户分配的托管标识。 可以使用 Azure 机器学习 CLI v2 或 ARMClient 将用户分配的托管标识附加到现有的 Azure 机器学习工作区。