Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
本文介绍与预测任务中的模型推理和评估相关的概念。 有关 AutoML 中训练预测模型的说明和示例,请参阅设置 AutoML 以使用 SDK 和 CLI 训练时序预测模型。
使用 AutoML 训练并选择最佳模型后,下一步是生成预测。 然后,如果可能,在从训练数据中保留的测试集上评估它们的准确性。 若要了解如何在自动化机器学习中设置和运行预测模型评估,请参阅协调训练、推理和评估。
推理方案
在机器学习中,推理是为训练中不使用的新数据生成模型预测的过程。 由于数据依赖于时间,可通过多种方式在预测中生成预测。 最简单的方案是,推理周期紧跟训练周期,并生成直至预测范围的预测结果。 下图演示了此方案:
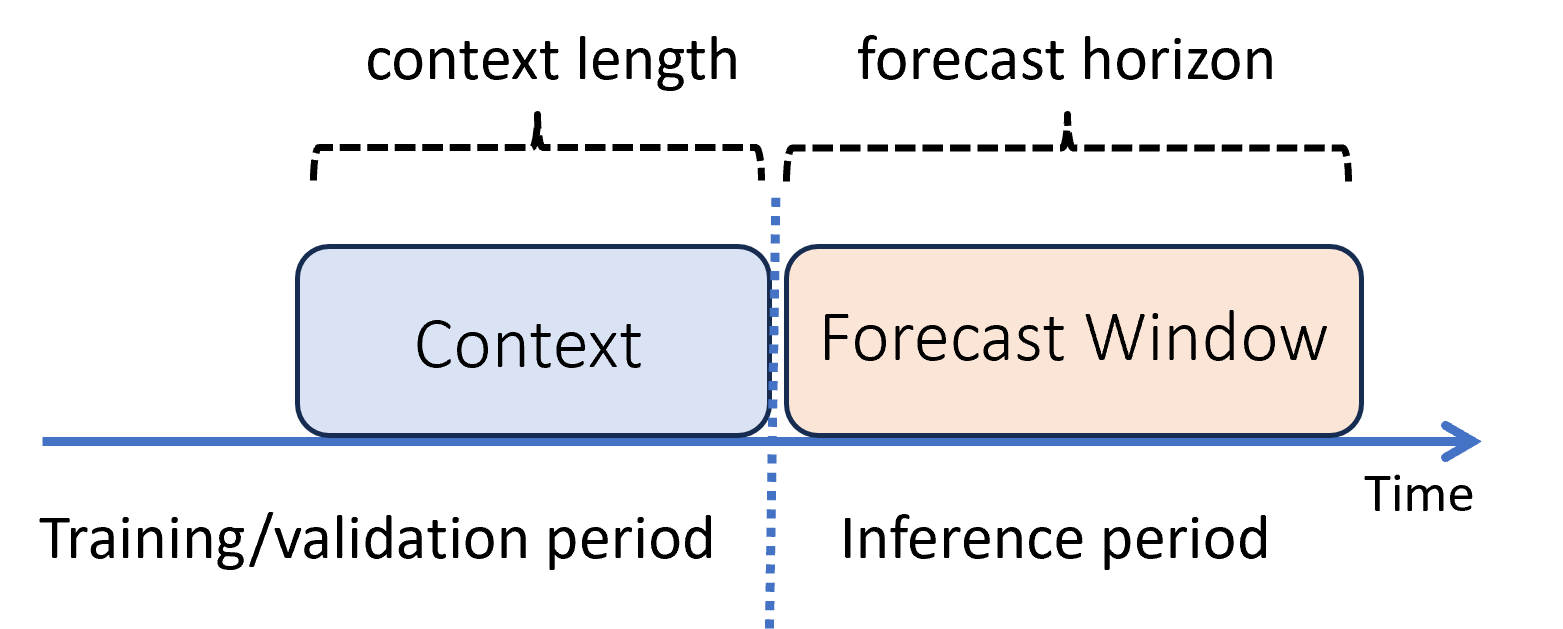
此图显示了两个重要的推理参数:
- 上下文长度是指模型进行预测所需的历史记录量。
- 预测范围是指将预测程序训练成预测多久以后的时间。
预测模型通常使用一些历史信息(上下文)来提前预测到预测范围。 当上下文是训练数据的一部分时,AutoML 会保存生成预测所需的内容。 你不需要显式提供它。
另外两种推理方案更为复杂:
- 生成比预测范围更远的未来预测
- 在训练和推理周期之间存在差距时获取预测
下面的小节将探讨这些情况。
预测超出预测范围:递归预测
当需要预测超出范围时,自动化机器学习在推理周期内以递归方式应用模型。 模型的预测被作为输入反馈以便为后续预测窗口生成预测。 下面的图表显示了一个简单的示例:
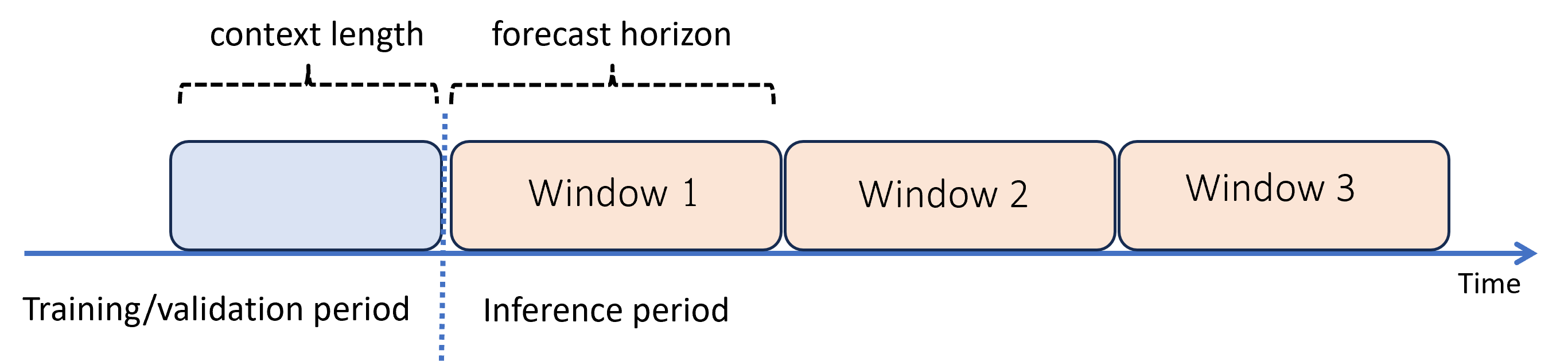
在这种情况下,机器学习会在三倍于预测范围长度的周期内生成预测。 它会将一个窗口中的预测用作下一个窗口的上下文。
警告
递归预测会加剧建模误差。 预测离原始预测范围越远,其准确性就越低。 您可能通过用更长的预测期重新训练来找到更准确的模型。
训练和推理周期之间存在差距时的预测
假设训练了一个模型后,你想要使用它根据训练期间尚不可用的新观察值进行预测。 在这种情况下,训练和推理周期之间存在时间差距:
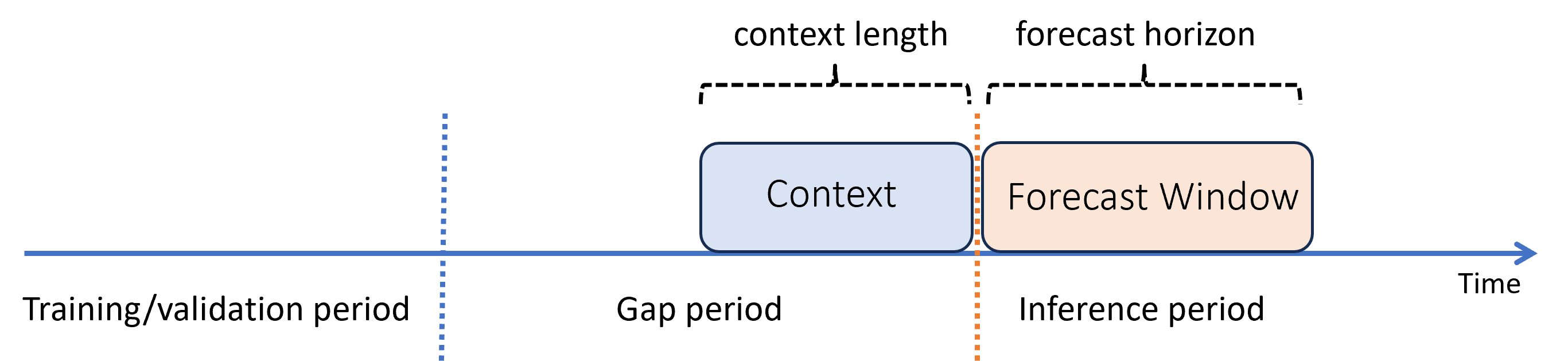
自动化机器学习支持此推理方案,但需要在差距周期内提供上下文数据,如图所示。 传递给 [推理组件](how-to-auto-train-forecast.md#orchestrate-training-inference-and-evaluation-by using-components-and-pipelines) 的预测数据需要特征值以及观测目标值,在推理期间目标值的间隔和缺失值或 NaN 值。 下表所示为此模式的示例:
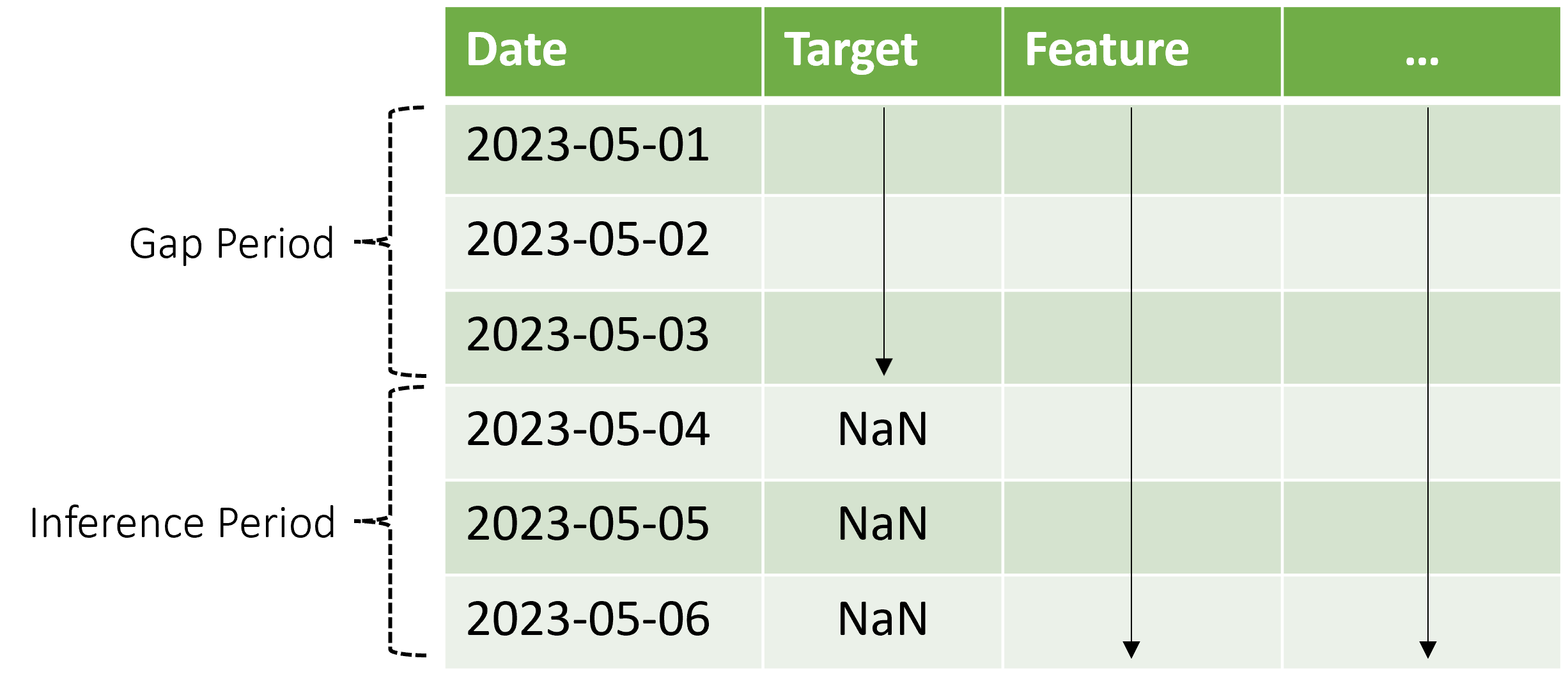
目标和特征的已知值针对 2023-05-01 到 2023-05-03 提供。 缺少从 2023-05-04 开始的目标值表示推理周期从该日期开始。
自动化机器学习使用新的上下文数据来更新延迟和其他回溯功能,以及更新保持内部状态的 ARIMA 等模型。 此操作不会更新或重新拟合模型参数。
模型评估
评估 是在从训练数据中分离出的测试集上生成预测,并计算这些预测的指标,以指导模型部署决策的过程。 因此,有一种适合模型评估的推理模式:滚动预测。
评估预测模型的最佳实践过程是让经过训练的预测程序在测试集上按时间向前滚动,计算多个预测窗口上的误差指标平均值。 此过程有时称为回溯测试。 理想情况下,用于评估的测试集相对于模型的预测范围较长。 否则,预测误差的估计在统计上可能会有噪声,从而降低可靠性。
下图显示了一个包含三个预测窗口的简单示例:
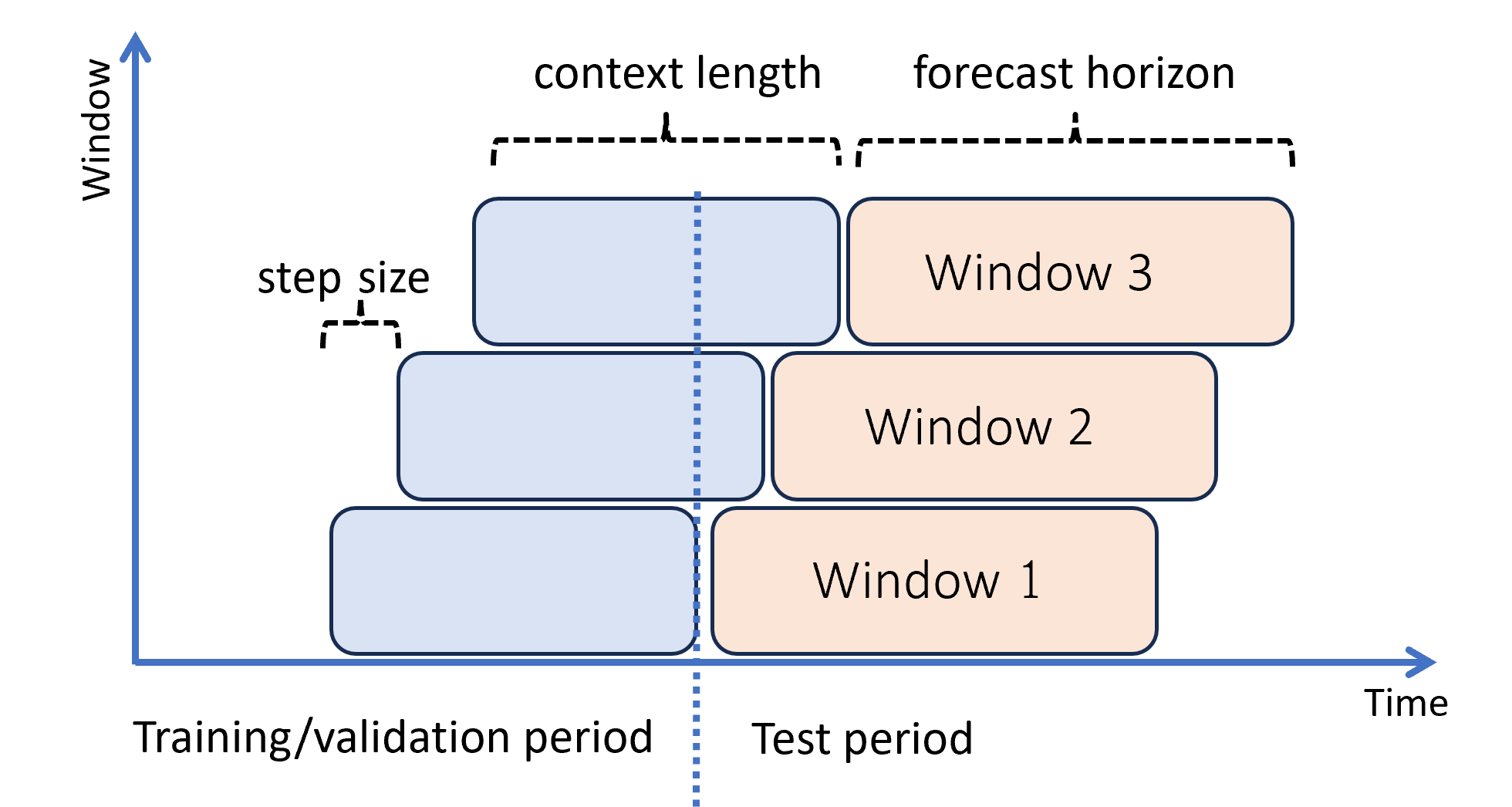
此图演示了三个滚动评估参数:
- 上下文长度是指模型进行预测所需的历史记录量。
- 预测范围是指将预测程序训练成预测多久以后的时间。
- 步长大小是指在测试集上每次迭代时滚动窗口向前推进的时间提前多远。
上下文随预测窗口一起前进。 测试集中的实际值会用于在当前上下文窗口中进行预测。 用于给定预测窗口的实际值的最新日期称为窗口的起始时间。 下表显示了三窗口滚动预测的示例输出,范围为三天,步长为一天:
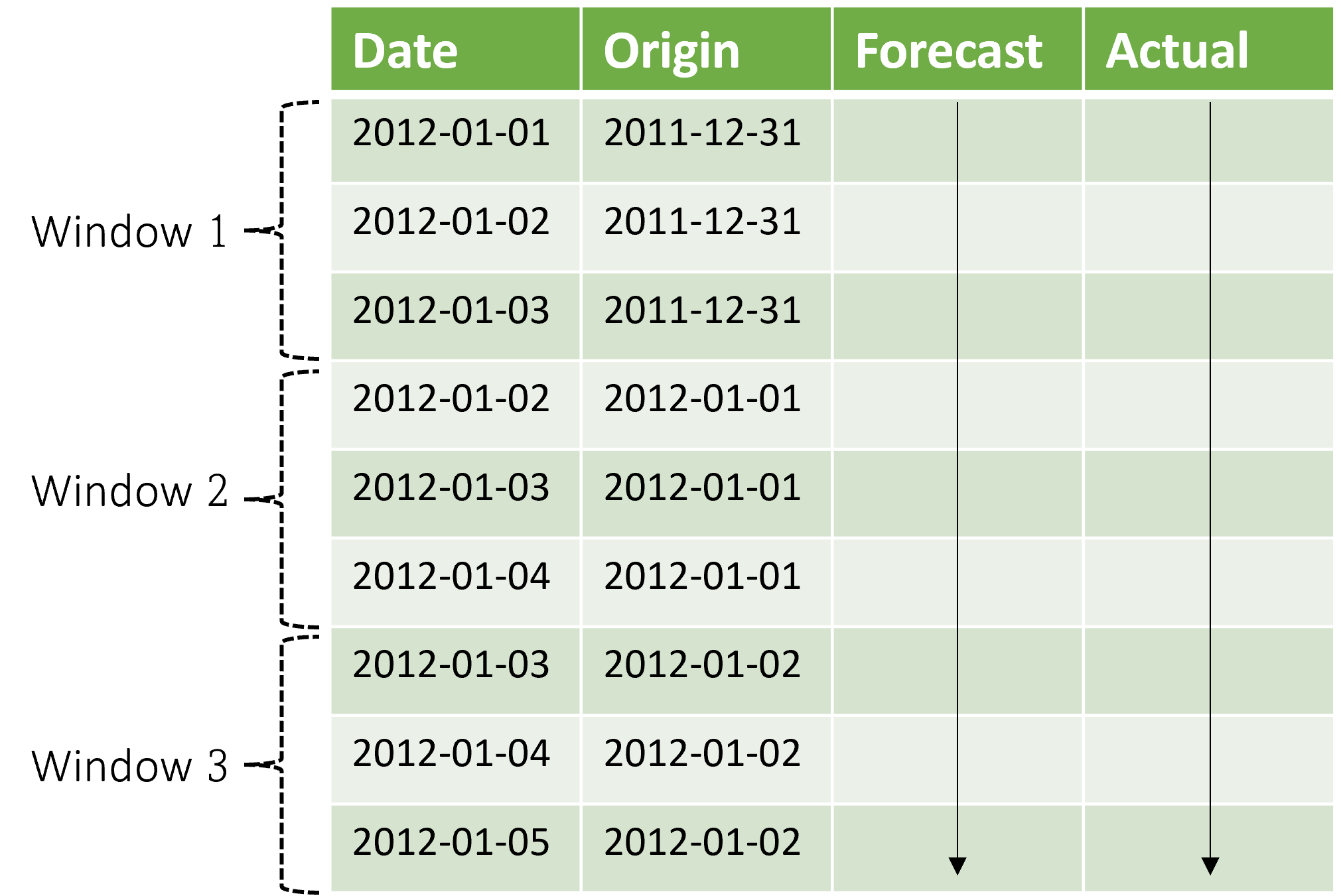
通过这样的表,你可以可视化预测与实际值的对比并计算所需的评估指标。 自动化机器学习管道可以的对具有推理组件测试集生成滚动预测。
注意
当测试周期的长度与预测范围相同时,滚动预测会提供一个直到范围的预测窗口。
评估指标
特定的业务方案通常驱动着评估摘要或指标的选择。 一些常见的选择包括以下示例:
- 观察到的目标值与预测值绘图,以检查模型是否捕获数据的某些动态
- 实际值和预测值之间的平均绝对百分比误差 (MAPE)
- 实际值与预测值之间的均方根误差 (RMSE),可能具有归一化
- 实际值与预测值之间的平均绝对误差 (MAE),可能具有归一化
根据业务方案,可能需要创建自己的后处理实用工具,以便从推理结果或滚动预测计算评估指标。 有关指标的详细信息,请参阅回归/预测指标。
相关内容
- 详细了解如何设置 AutoML 来训练时序预测模型。
- 了解 AutoML 如何使用机器学习生成预测模型。
- 阅读有关在 AutoML 中预测的常见问题解答的答案。