Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
本文介绍 Azure 机器学习中的自动化机器学习 (AutoML) 如何搜索并选择预测模型。 如果有兴趣详细了解 AutoML 中的预测方法,请参阅 AutoML 中的预测方法概述一文。 若要浏览 AutoML 中预测模型的训练示例,请参阅设置 AutoML 以使用 SDK 和 CLI 训练时序预测模型。
AutoML 中的模型扫描
AutoML 的核心任务是训练和评估若干个模型,并针对给定的主要指标选择一个最佳模型。 此例中的“模型”一词既指模型类(如 ARIMA 或随机林),也指用于区分一个类中的不同模型的特定超参数设置。 例如,ARIMA 是指共享数学模板和一组统计假设的一类模型。 为了训练(或拟合)ARIMA 模型,需要一个正整数的列表,用于指定模型的精确数学形式。 这些值是超参数。 ARIMA(1, 0, 1) 和 ARIMA(2, 1, 2) 模型具有相同的类,但具有不同的超参数。 这些定义可分别与训练数据相拟合,并相互评估。 AutoML 通过改变超参数,对不同的模型类和在类的内部进行搜索或扫描。
超参数扫描方法
下表显示了 AutoML 用于不同模型类的各种超参数扫描方法:
| 模型类组 | 模型类型 | 超参数扫描方法 |
|---|---|---|
| Naive、Seasonal Naive、Average、Seasonal Average | 时序 | 由于模型很简单,无类内扫描 |
| 指数平滑,ARIMA(X) | 时序 | 类内扫描的网格搜索 |
| Prophet | 回归 | 类内无扫描 |
| Linear SGD、LARS LASSO、弹性网络、K 最近的邻域、决策树、随机林、极端随机树、梯度提升树、LightGBM、XGBoost | 回归 | AutoML 的模型建议服务动态地探索超参数空间 |
| ForecastTCN | 回归 | 模型静态列表,然后是网络大小、丢弃率和学习率的随机搜索 |
有关不同模型类型的说明,请参阅预测方法概述一文的“AutoML 中的预测模型”部分。
AutoML 的扫描量取决于预测作业配置。 可将停止条件指定为时间限制或试用次数的限制,或者等效的模型数量。 在这两种情况下,如果主要指标没有改进,则可以使用提前终止逻辑来停止扫描。
AutoML 中的模型选择
AutoML 遵循三个阶段的过程来搜索并选择预测模型:
阶段 1:扫描时序模型,并使用极大似然估计方法从每个类中选择最佳模型。
阶段 2:扫描回归模型,并根据验证集中的主要指标值,对这些模型以及阶段 1 中的最佳时序模型进行排名。
阶段 3:基于排名靠前的模型生成一个集成模型,计算其验证指标,并将其与其他模型一起排名。
在第 3 阶段结束时,指标值排名靠前的模型被指定为最佳模型。
重要
在阶段 3 中,AutoML 始终针对未用于拟合模型的样本外数据计算指标。 此方法有助于防止过度拟合。
验证配置
AutoML 有两种验证配置:交叉验证和显式验证数据。
在交叉验证情况下,AutoML 使用输入配置创建数据拆分,拆分为训练折叠和验证折叠。 必须保留这些拆分中的时间顺序。 AutoML 使用所谓的滚动原点交叉验证,它使用原始时间点将系列数据划分为训练和验证数据。 在时间内滑动原点会生成交叉验证折叠。 每个验证折叠包含紧跟在给定折叠的原点位置之后的下一个观测范围。 此策略保留了时序数据完整性,并降低了信息泄露风险。
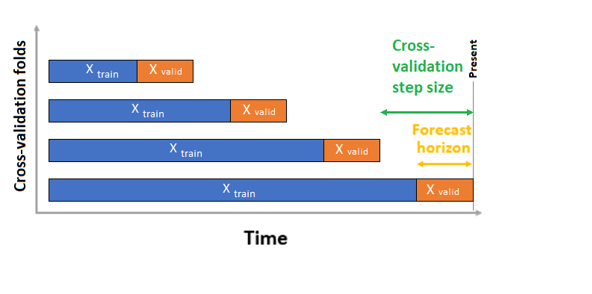
AutoML 遵循惯常的交叉验证过程,在每个折叠上训练单独的模型,并计算所有折叠中的验证指标的平均值。
通过设置交叉验证折叠数和(可选)两个连续交叉验证折叠之间的时间段数来配置预测作业的交叉验证。 有关详细信息以及配置交叉验证进行预测的示例,请参阅自定义交叉验证设置。
你也可以自带验证数据。 有关详细信息,请参阅在 AutoML 中配置训练、验证、交叉验证和测试数据 (SDK v1)。